
![[Lora] Kohya_ss GUI 介面筆記](/content/images/size/w960/2023/10/feature.jpg)
這是單純介紹一下 Kohya_ss GUI 的操作界面,雖然每次版本升級之後都有些微差異,但大抵上還是可以通用。我這邊僅介紹關於 Lora 的部分,其他介面上的東西勞煩大家自行研究。
Kohya_ss GUI 24.1.4 Update
這個部分是更新新版本的介面,順便補充一些之前沒有提到的部分。
Accelerate launch
現在在介面上,可以設定 accelerate 啟動器的參數,但請注意,如果你有做過 Accelerate 的設定動作,這邊參數雖然會覆寫,但如果 Accelerate 設定檔故障,會連整個訓練都無法啟動。
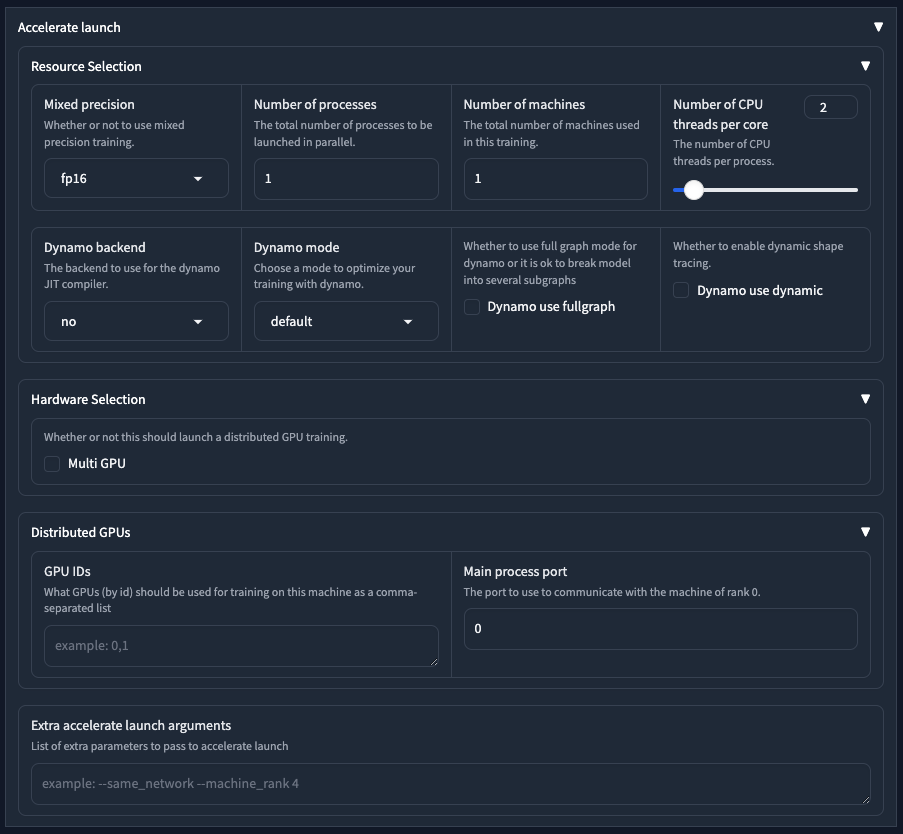
Resource Selection
這個部分是設定啟動 accele 的部分,基本上不太需要做更動。唯一可能需要選擇的大概就屬 Mixed precision 的部分,通常我們會選擇 fp16。
| 參數 | 說明 |
|---|---|
Number of processes |
則為啟動多少訓練程序在此一訓練中,單機就維持 1 就好 |
Number of machines |
則表示多少台機器用於此一訓練,單機一樣維持 1 就好 |
Number of CPU threads per core |
表示 CPU 有多少個超線程,一般就是 2 |
而以下四個參數則是針對後端 CUDA graph 加速的部分,我不多做解釋,除非你知道自己在做什麼,不然維持預設就好。
Dynamo backend為no。Dynamo mode為default。Dynamo use fullgraph不勾選。Dynamo use dynamic不勾選。
Hardware Selection
裡面只有一個選項,就是當你有多張 GPU 顯卡時,可以啟用 Multi GPU 的功能。
Distributed GPUs
這邊可以指定要用哪一個 GPU 進行訓練,如果你只有一張 GPU 的話就不需要更改。
GPU IDs代表每張 GPU 的 ID,數字從0開始。Main process port主程序用於各機器溝通的port,預設使用0,就是第一台。
Extra accelerate launch arguments
在這邊你可以額外再輸入 Accelerate 的參數。
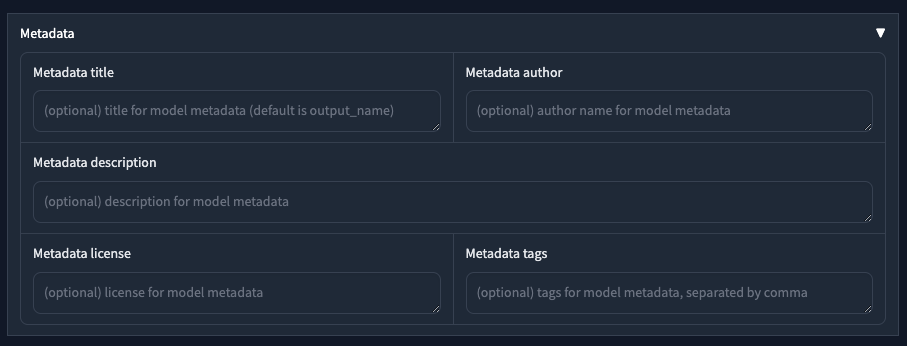
Metadata
這邊是讓你撰寫關於訓練好的 Lora 當中的 Metadata 相關資訊,如果你都不寫的話,基本上他會自己去取用訓練的部分內容。
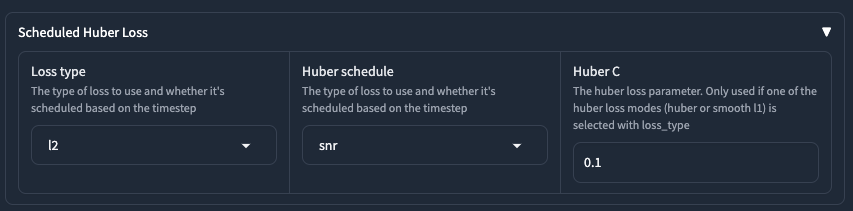
Scheduled Huber Loss
這大概是 23 之後,在 Kohya-ss 0.8.6 之後放入的功能,關於 Huber Loss 的相關資料可以參考這個 #PR1228。這個設定藏在 Advanced 的項目裡面,在 Additional parameters 的下方。
Loss type
| 參數 | 說明 |
|---|---|
l2 |
不使用 Huber 計算,等於之前不支援 Huber Loss 的訓練方式 |
smooth_l1 |
使用 smooth L1 計算 Loss |
huber |
使用 Huber 計算 Loss |
實際的計算方式可以看原始程式碼,其實 Huber 的算法跟原論文有點出入,但根據實驗結果,這個計算方式訓練效果比較好。
def conditional_loss(
model_pred: torch.Tensor, target: torch.Tensor, reduction: str = "mean", loss_type: str = "l2", huber_c: float = 0.1
):
if loss_type == "l2":
loss = torch.nn.functional.mse_loss(model_pred, target, reduction=reduction)
elif loss_type == "huber":
loss = 2 * huber_c * (torch.sqrt((model_pred - target) ** 2 + huber_c**2) - huber_c)
if reduction == "mean":
loss = torch.mean(loss)
elif reduction == "sum":
loss = torch.sum(loss)
elif loss_type == "smooth_l1":
loss = 2 * (torch.sqrt((model_pred - target) ** 2 + huber_c**2) - huber_c)
if reduction == "mean":
loss = torch.mean(loss)
elif reduction == "sum":
loss = torch.sum(loss)
else:
raise NotImplementedError(f"Unsupported Loss Type {loss_type}")
return loss
Huber schedule
當使用 Huber Loss 時,排程器的選擇。
| 參數 | 說明 |
|---|---|
constant |
使用常數排程 |
exponential |
使用指數函數排程 |
snr |
使用訊號雜訊比(Signal-to-noise ratio)方式排程 |
在整個 #PR1228 的討論中,原本一開始的測試是使用 smooth_l1 加上 expontential 來做,效果不錯。後來則是更推薦使用 huber 加上 snr 的方式來做。
Huber C
這個參數只有 Loss Type 使用 huber 或 sommth_l1 的時候才會生效。預設是使用 0.1 這個常數。在實際的訓練測試中,我發現把他打對折效果會比較好,也就是使用 0.05 這個數值。但是,這個數字還是要看訓練集的狀況,沒有一個固定很好的小抄可用。
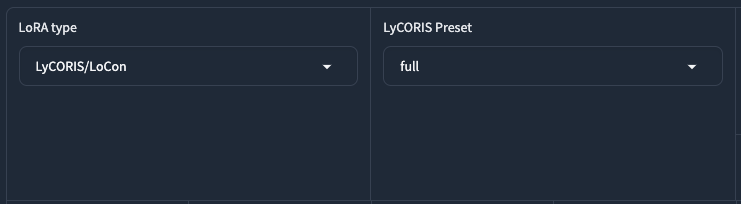
LyCORIS Preset
當你的 LoRA Type 選擇 LyCORIS/ 系列的時候,會有一個 LyCORIS Preset 可以選擇。他是 LyCORIS 所提供的一個設定。關於這個部分,作者 青葉有寫說明在這裡。
| 參數 | 說明 |
|---|---|
full |
預設,訓練所有層的 UNet 與 CLIP |
full-lin |
跟 full 一樣,但不訓練卷積層(convolutional layers) |
attn-mlp |
使用 Kohya 預設,訓練所有轉換區塊(transformer block) |
attn-only |
僅訓練注意力層(attention layer) |
unet-transformer-only |
使用 Kohya 預設,但不訓練 TextEncoder,等同於使用 attn-mlp 加上 --train_unet_only 的效果 |
unet-convblock-only |
僅訓練 ResBlock, UpSample, DownSample 三個部分 |
同時,在你選擇了 LyCORIS/ 系列後,在進階設定中還會有關於 LyCORIS 的設定。
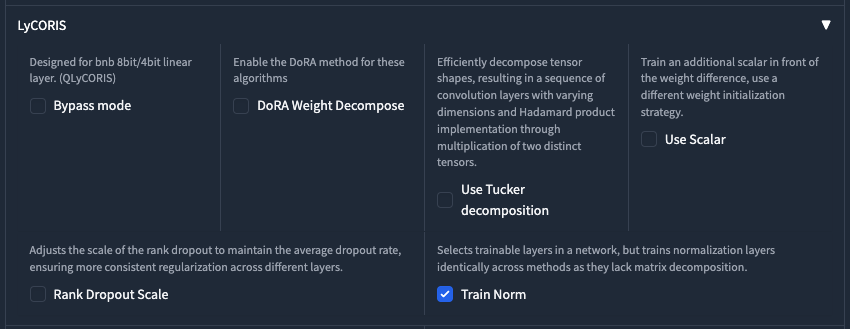
LyCORIS 更多的設定
這個部分就不是我的專業,如果有興趣的人可以去參考作者 青葉的 Github。
| 參數 | 說明 |
|---|---|
Bypass mode |
設計給 8bit/4bit 的線性層使用 |
DoRA Weight Decompose |
使用 DoRA 權重分解 |
Use Tucker decomposition |
在神經網路模型中一種高效地構建卷積層序列的方法,其中包括對輸入張量形狀進行分解,並通過相乘兩個不同張量的方式來實現哈達馬積運算 |
Use Scalar |
為了提高模型的訓練穩定性和收斂速度,在權重差值前面訓練一個額外的標量,使用不同的權重初始化策略。 |
Rank Dropout Scale |
通過動態調整不同層的丟棄比例,在維持整體平均丟棄率不變的前提下,讓網絡各層所受到的正則化作用更加均衡,從而達到更好的正則化效果,防止過度擬合 |
Train Norm |
只對具有可訓練權重矩陣的層應用特殊訓練方法,而對於標準化層則統一採用普通方式訓練,因為標準化層本身的結構不適合應用那些利用矩陣分解的技術 |
以上的參數並不一定每一種 LyCORIS 的模型都會有,另外,在 iA3, OFT 與 LoKr 還會有以下專有的設定。
| 參數 | 說明 |
|---|---|
iA3 train on input |
設定是否改變輸入系統的資訊 |
Constrain OFT |
限制 oft_blocks 的範數(Norm),確保它們的幅度不超過指定的閾值,從而控制所應用的轉換程度 |
Rescaled OFT |
對 oft_blocks 應用一個額外的縮放因子,允許進一步調整它們對模型轉換的影響程度 |
LoKr decompose both |
設置控制了在該層的權重矩陣張量上,是僅對輸入或輸出其中一個維度進行參數分解,還是同時對這兩個維度都進行參數分解,以減少參數量並加速計算 |

訓練精度進階設定
我們現在可以選擇使用三種精度來訓練,如果你的 VRAM 吃緊的話,可以試試看 fp8 base training (experimental) 這個選項。
不過請注意,由於需要 bitsandbytes 這個套件,所以請先確保你的環境有安裝好。
Scale v prediction loss
這是給 SD v2 模型使用的設定,如果你是訓練 SD v2 的模型,就需要把他勾選起來。
Masked loss
這個功能原本是在 ControlNet 訓練中所使用,雖然普通的 Lora 訓練也可以做相關操作,但這個功能目前在 GUI 需要一連串特殊操作才能使用。
他主要的目的是使用一個遮罩圖片,讓整個訓練過程,會專注在遮罩的部分,而忽略遮罩以外的地方。但目前 Kohya-ss 在 dev 中已經合併了一個 alpha mask 的相關功能,所以這邊我不多做介紹。
若之後真的合併到主分支後,我會在另外開一篇文章來寫這個部分。
Debiased Estimation loss
這個解釋起來也是一篇論文,基本上跟 min-SNR-gamma 是類似的作法,具體資料在 #PR889 有一點點討論。
Noise offset random strength
這是在 Noise offset type 為 Original 才有的設定,他會將原本的 Noise offset 改為 0 ~ noise_offset 之中取一個亂數來當作 noise_offset,而不是使用固定值。
Adaptive noise scale
這也是在 Noise offset type 為 Original 才有的設定,意思是使用一個潛空間平均絕對值(latent mean absolute value),乘上這個數字來當作 noise_offset。
IP noise gamma
在訓練的時候輸入一個擾動的噪聲,用來正規化訓練結果,建議使用 0.1。
IP noise gamma random strength
在你有設定 IP noise gamma 時,若啟用這個項目,則他會在 0 ~ ip_noise_gamma 當中取一個隨機數值,來當作輸入的擾動噪聲。
以上關於 Noise 的部分,具體使用的結果我會另外寫文章來介紹。
Save training state at end of training
勾選這個項目,會儲存最後一次的訓練狀態(state)檔案,方便你用於接續訓練。
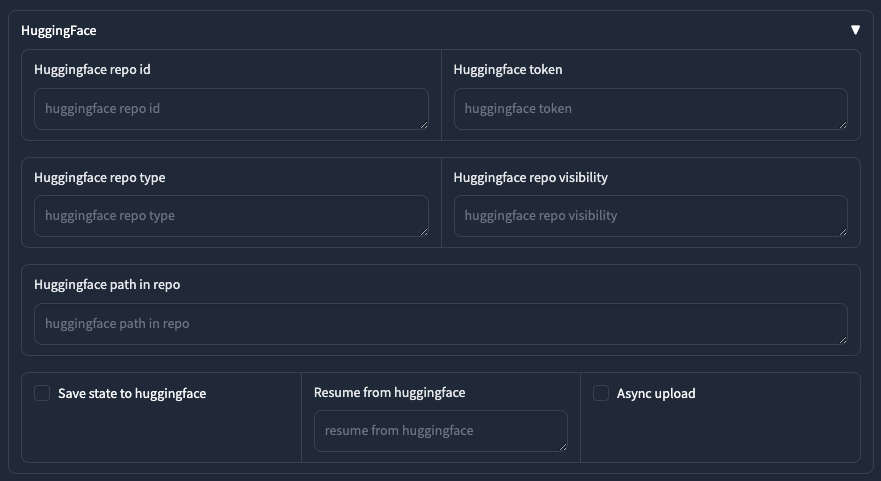
HuggingFace 設定
這一個區塊就是方便你把訓練好的東西,直接發佈到 HuggingFace 上面。實際上的操作我就不在這邊贅述了。
Kohya_ss GUI
本次文章所記錄的版本是 v22.0.1,當然比較舊的版本可能會缺少一些功能。
Lora 訓練介面
首先是最上面的 Configuration file 的部分,

這邊可以讓你存放你的訓練設定檔,應該沒有什麼懸念。接著整個訓練區塊分成四個部分,
- Source Model
- Folders
- Parameters
- Dataset Preparation
Source Model
這邊可以讓你選擇你要訓練的模型,目前 Kohya_ss GUI 支援所有關方模型,但 不包含 SDXL。你可以從 Model Quick Pick 快速選擇官方模型。
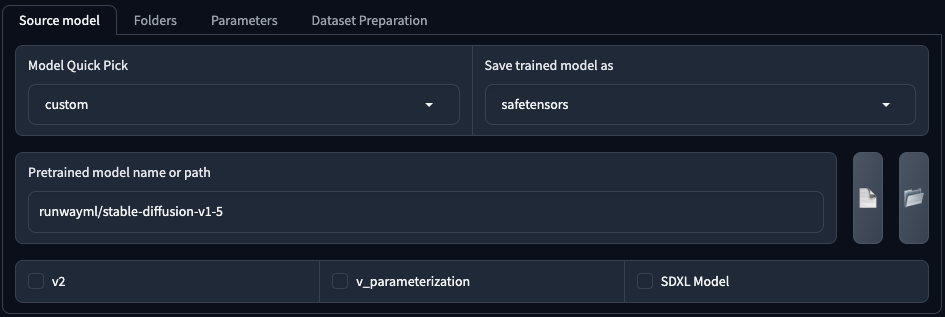
或是使用 custom(以下稱「自訂模型」自訂模型)來設定自己想要使用的模型,另外,如果要訓練 SDXL 也是得使用自訂模型來填寫。
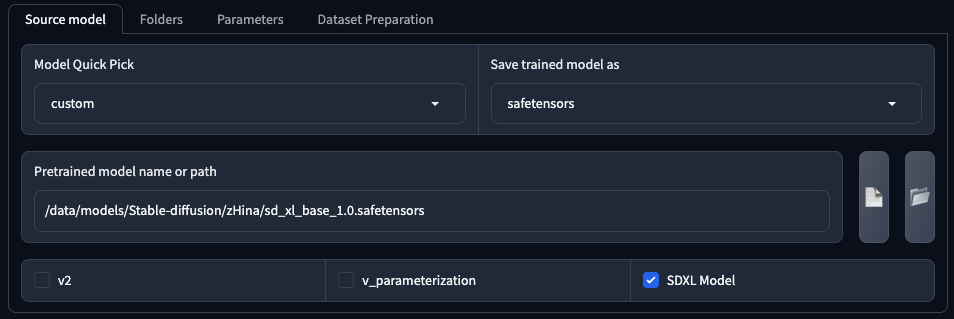
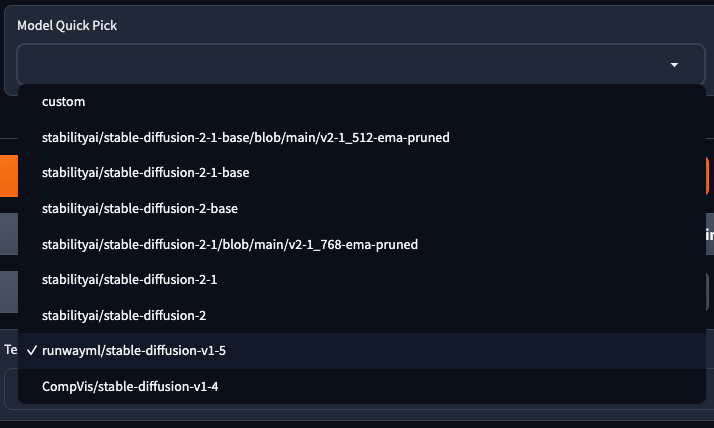
使用自訂模型的時候,會有額外的三個項目可以勾選,
| 參數 | 說明 |
|---|---|
v2 |
訓練 SD 2/2.1 模型 |
v_parameterization |
這是在 SD 2 所引入的一個新技術,目的是使用更少的採樣步數來達到更好的收斂效果。如果訓練 2/2.1 模型,或是你的自訂模型有使用,那你就可以開啟,也最好同時使用 v2。 |
SDXL |
訓練 SDXL 模型 |
而 Save trained model as 則是讓你選擇要儲存成哪一種模型類型,預設會使用 safetensors。
Folders
這裡是用來設定你的訓練資料集、正規化(Regularisation)資料集、輸出以及記錄的地方。
| 參數 | 說明 |
|---|---|
Image folder |
放置訓練資料集的資料夾,資料夾中包含了 Repeats_[Concept Prompt] 這樣命名結構的資料夾。例如 50_hina lora-girl,至於這個資料夾細分 Instance Prompt 與 Class Prompt 後面會另行討論。 |
Regularisation folder |
放置訓練正規化(Regularisation)資料集的資料夾,關於這個部分後面會另行補述。 |
Output folder |
模型輸出的資料夾,如果你有儲存訓練狀態(state)紀錄,也會放在這裡。 |
Logging folder |
訓練模型時的紀錄檔,如果你想使用 Tensorboard 觀察訓練過程,這裡就必需要填寫。 |
Model output name |
訓練模型輸出的檔案名稱,請注意,他會自動加上附檔名(依據你所選擇的儲存模型的類型)。 |
Training comment |
訓練完成後在模型的 Metadata 當中加入註記。 |
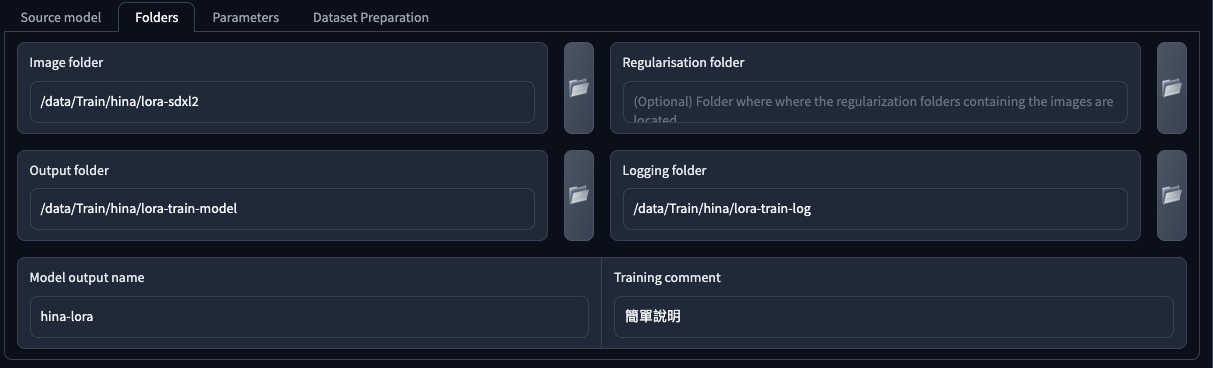
Parameters
這個部分則是整個 Lora 訓練的所有參數設定的地方,裡面分成了三個區塊,
- Basic
- Advanced
- Samples
其中 Presets 是 Kohya-ss 所提供的現成的設定檔,方便使用。
Basic 基本設定
這個畫面包含了以下資訊,
LoRA type
訓練 Lora 的種類,有以下幾種:
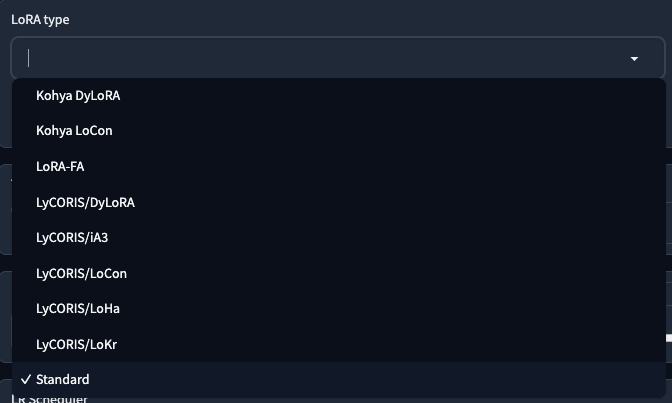
如果你不知道怎麼選,就用預設的 Standard 就好了。
LoRA network weights
讀取其他 Lora 的網路權重,來開始一個訓練。
請注意!
市面上「接續訓練」有兩種方式,一種是使用這個設定,另一種是從訓練狀態(state)中繼續。但這兩者之間是有差異的,使用這個 LoRA network weights 設定載入上一個 Lora 的訓練結果,
嚴格來說並不是「接續訓練」
嚴格來說並不是「接續訓練」
嚴格來說並不是「接續訓練」
因為很重要所以說三次,這個設定只是做了這件事,
載入上一個 Lora 訓練結果的網路權重
然後開始這一次的訓練(全新,但是基於讀取的權重),所以,對我而言,這其實是一個全新的訓練。這個與使用 Resume from saved training state 是全然不同的。
DIM from weights
如果勾選,則會從 LoRA network weights 的檔案中,自動偵測 dim(rank) 的數值。
Train batch size
訓練批次的大小,這裡的數字代表了 每次載入的圖片數量,所以當你寫 2 的時候,表示每次載入 2 張圖片進行訓練。在同時載入多張圖片時,每張圖片的訓練精度會降低,但因為是 同時捕捉多張圖片的特徵,所以訓練的結果或許會更好。但是這個數字並不是越大越好,如果你的 VRAM 超大的話就當我沒說。
另外,在加大批次數量時,若學習效果不佳,可以嘗試著增加學習率。
由於每次載入的圖片尺寸必須相同,所以當你的圖片尺寸不固定的情況下,可同時處理的數量會少於此設定的批次大小。
Epoch
設定訓練要跑多少個 Epoch(這個真的很難找到翻譯詞,我之前是使用「輪次」,但直譯成中文是時代、紀元,也是很難懂)。這裡會跟總步數(學習週期)有關,舉例來說,有 20 張圖片,重複 50 次,那麼每一個 Epoch 就是 50 x 20 x 1 = 1000,如果有 2 個 Epoch,那麼就會是 50 x 20 x 2 = 2000,依此類推。當然總步數(學習週期)不僅止於此,這邊僅對 Epoch 發生作用的部分做說明。
Max train epoch
最大訓練 Epoch 數量,如果有填寫這個數字,將會覆蓋 Epoch 設定。
Max train steps
最大訓練總步數(學習週期)數量,如果有填寫這個數字,將會覆蓋最終計算出的總學習步數(學習週期),並且會連帶修正 Epoch 數值。關於總學習步數(學習週期)的計算方式,在 Kohya-ss 當中,公式如下:
Repeats x Images x Epoch / Total batch size / Gradient accumulate steps * Epochs * (是否使用正規化,若有則為 2,若沒有則為 1)
Save every N epochs
訓練過程中,多少個 Epochs 儲存一個模型。這對於初次訓練新概念時會有幫助,你可以測試每一個 Epoch 訓練結果,並挑選一個比較好的。
Caption Extension
提示詞的附檔名,預設是 .caption,如果你的提示詞是純文字檔(txt),你也可以改用 .txt。如果你不填寫,就會使用預設的 .caption。
Mixed precision
設定在學習過程中,訓練混合精度要使用哪一種。一般會推薦 bf16 來避開一些溢位問題,但我個人推薦 fp16,不知為何 fp16 效果略好(純屬個人感覺)。
Save precision
訓練完成後儲存的精度設定,通常跟 Mixed precision 設定成一樣就好了。
Number of CPU threads per core
學習過程中,指定 CPU 線程數,一般預設是 2。基本上就是數量越多,效率越高,但還是需要根據你自己的設備規格而定。
Seed
在訓練過程中,存在著很多需要拿取一個「隨機」數的地方,這裡的種子(seed)數值,是用來指定訓練過程中,當取用隨機時,會以此種子為參考值。如果不設定,則每一次訓練開始,就會先隨機抓一個數字當種子。
指定 Seed 有一個好處,當你想要複現某一次訓練時,有指定這個種子數值的話,會比較容易複現出訓練結果(前提是訓練資料、參數設定等沒有改變的情況下)。
另外,這個 Seed 並不會干擾隨機裁切(Random crop instead of center crop)這個參數的隨機性。
Cache latents
預設開啟,啟用 Latents 快取。在開始一個訓練時,會把圖片壓縮成一個比較小的 Latent 並存放在 VRAM 當中作為快取使用,這樣可以加速整個訓練過程。
在開啟這個功能的情況下,以下功能無法同時使用,
Color augmentationRandom crop instead of center crop
Cache latents to disk
跟 Cache latents 雷同,但儲存到磁碟。當你要多次訓練時,這個可以加速訓練之前的預處理時間,預設為關閉。
LR Scheduler
學習率調度器,預設使用 cosine,用來決定你的學習率用什麼樣的方式進行,有以下幾種,
| 參數 | 說明 |
|---|---|
adafactor |
選擇此項目可將優化器(稍後說明)設定為 Adafactor。是一種自動學習率的方式。 |
constant |
學習率從開始到結束保持不變(常數)。 |
constant_with_warmup |
學習率從 0 開始,在預熱(LR warmup 稍後說明)時逐漸增加到學習率的設定值,最終會使用學習率的設定值直到結束。 |
consine |
學習率使用餘弦曲線,並在訓練結束前,逐漸的趨近於 0。| |
cosine_with_restarts |
多次餘弦重複循環,根據學習率循環次數(LR number of cycles 稍後說明),在訓練結束前,使用餘弦曲線的方式進行訓練。 |
linear |
學習率使用線性函數下降,並在訓練結束前,逐漸的趨近於 0。| |
polynomial |
行為跟 linear 相同,但訓練下降的方式較為複雜(與 LR number of cycles, LR Power 有關,後續會說明)。 |
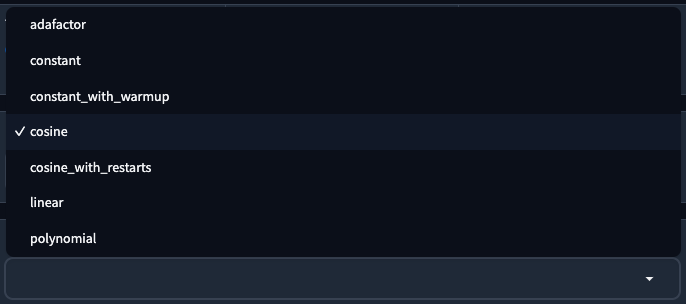
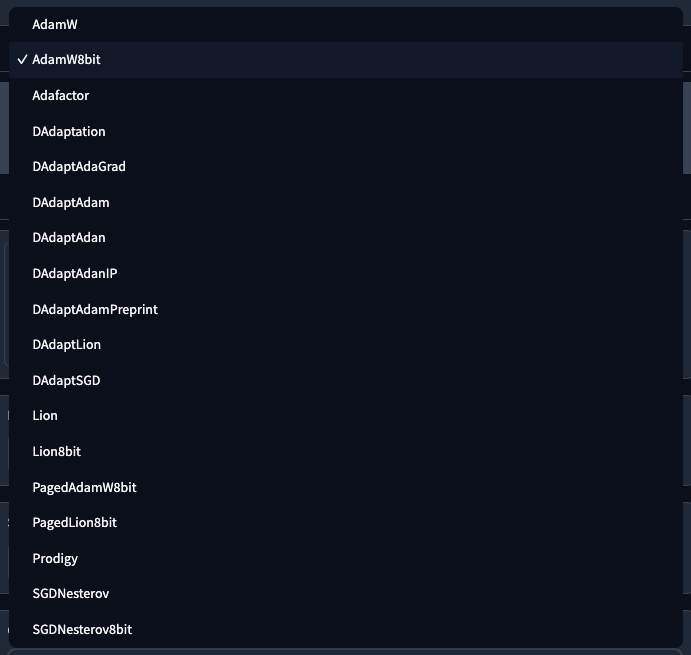
Optimizer
訓練時所使用的優化器,預設是 AdamW8bit。關於優化器的部分,可以參閱我之前的文章 訓練優化器與超參數。
Max grad norm
預設使用 1,如果不確定你在做什麼,請不要更改這個設定。在 Kohya 訓練當中,當這個數值不為 0 的時候,會使用 clip_grad_norm_ 來做梯度剪裁的動作,就是在梯度超過一個閾值的時候,強制把梯度設定為閾值來防止發生梯度爆炸的情況。而這邊所設定的數值就是訓練過程中,梯度剪裁的時候的閾值。
LR scheduler extra arguments
這裡是用來設定學習率調度器(LR Scheduler)的額外參數,每一種調度器的參數不盡相同,所以更換調度器時,請留意額外參數是否正確。
如果對參數有興趣的人,可以自行參考原始碼,他會在 torch/optim/lr_scheduler.py 裡面。
Optimizer extra arguments
這裡是用來設定優化器(Optimizer)的額外參數,跟上述設定一樣,每一種優化器都不太一樣。
Learning rate
學習率設定,預設是 0.0001。但我記得沒錯的話,這邊單純就是個記錄,具體訓練過程所使用的,是使用 Text Encoder learning rate 與 Unet learning rate。
LR warmup (% of steps)
當你的學習調度器使用 constant_with_warmup 時,這邊則是可以設定預熱的步數,這邊是總訓練步數的 % 來計算,所以,你的總訓練步數若有 3,000 步,那麼這裡寫 10,就代表你的預熱步數為 3000 x 10% = 300。
若你的學習調度器是其他的項目,則此項目無效。
LR number of cycles
當你的學習調度器使用 cosine_with_restarts 或 polynomial 時,會決定在訓練過程中,要跑多少個循環週期。如果你不填寫,預設為 1。
通常的建議是,這個數字會以 Epochs 的 1/10 來計算,換句話說,如果你的 Epochs 為 32,那麼這邊可以寫 3 這樣,當然這沒有一定的標準。
若你的學習調度器是其他的項目,則此項目無效。
LR power
當你的學習調度器使用 polynomial 時,用來設定學習率的線性曲線,如果你不填寫,預設為 1。在預設值 1 的情況下,他與 linear 的結果會是相同的。而這個數字越大,則學習曲線會越陡,換句話說,越大的 power 數值,會越快讓學習率趨近於 0。
若你的學習調度器是其他的項目,則此項目無效。
Max resolution
學習目標的最大圖片解析度,以 Pixel 為單位的數字,設定方式是 寬度,高度,預設是 512,512。如果訓練集的資料超過這個尺寸,將會被降低到這個尺寸來做訓練。
Stop text encoder training
停止文字編碼器的訓練。這裡的設定也跟總訓練步數的 % 來計算,所以,你的總訓練步數若有 3,000 步,那麼這裡寫 80,就代表你的文字編碼器僅訓練 3000 x 80% = 2400,在 2,400 步時就會停止,接下來的 600 步就會僅訓練 U-Net 而已。
這對於防止過度訓練產生的過擬合狀況有一定的幫助,但並不是可以絕對防止的,只是一種手段。
預設值為 0,代表從頭訓練到結束。
Enable buckets
如果你的訓練資料集圖片尺寸不同,啟用後會將訓練資料集分成不同的資料桶。若你的圖片尺寸都一樣,則啟用他沒有效果。
另,如果你的訓練資料集圖片尺寸不同,但是 不啟用此項目,那麼你的圖片會被縮小(或放大)到你所設定的 Max resolution 的尺寸。但關於縮放這件事,則跟 Don't upscale bucket resolution 有關(稍後說明)。
Minimum bucket resolution
設定資料桶圖片最小的解析度,以 Pixel 為單位的數字,預設是 256。從這個解析度開始往上做資料集分桶的動作。
Maximum bucket resolution
設定資料桶圖片最大的解析度,以 Pixel 為單位的數字,預設是 2048。從這個解析度開始往下做資料集分桶的動作。
Text Encoder learning rate
文字編碼器的學習率。預設為 0.00005,通常是 Unet learning rate 的一半左右。
Unet learning rate
U-Net 的學習率。預設為 0.0001,你可以使用這個數字開始沒什麼問題。
Network Rank (Dimension)
代表這個 Lora 的神經元的數量,預設為 8。這個數字代表著可以學習並保留的資訊數量,數字越高越多,但同樣的,學習到目標以外的不必要資訊的可能性也會增加。
個人建議小訓練可以從 8, 16, 32 開始。
Network Alpha
由於 LoRA 的結構,神經網路的權重值往往很小,如果變得太小,可能會變得與零無法區分(即四捨五入後變成 0,與沒有學習到任何東西一樣)。所以在 Lora 訓練設計當中,會將實際保存的權重值增大,用以避免上述提到的問題。而 Alpha 則旨在削弱(當然你可以反向增強)這個權重大小。
他並沒有一個固定的數值,通常會建議使用 Network Rank (Dimension) 的一半,或是將他固定為某個數值(常見的是固定為 1),用來測試不同的 dim 與學習率。如果你不設定這個數值,則預設會使用與 Network Rank (Dimension) 相同,也就是完全不削弱權重的狀態下進行。
預設為 1。
Scale weight norms
這是一個用來限制學習網路的權重來穩定訓練的一個技術,可以參考 kohya-ss 的這個 PR#545。如果不知道這個東西在做什麼事情,麻煩不要填寫。
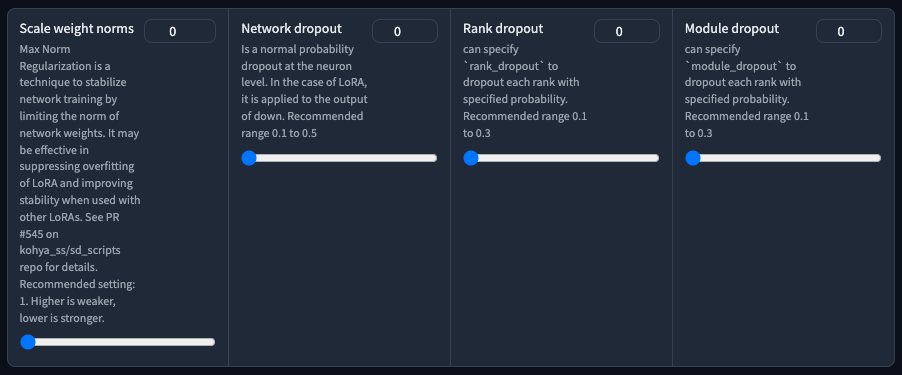
Network dropout
應用在 Lora 輸出層級,通用喪失率(捨棄或縮減)。目的一樣是用來增強訓練的穩定性,但同時你也會需要更多的總訓練步數來達到效果。
Rank dropout
應用在 Lora 輸出層級,神經元排名變化後的喪失率。
Module dropout
應用在 Lora 輸出層級,將模型隨機率低於此喪失率的部分捨棄。
Advanced 進階設定
這個畫面包含了以下資訊,第一組設定是比較進階(分層訓練)的用法,如果不需要可全部不填寫。
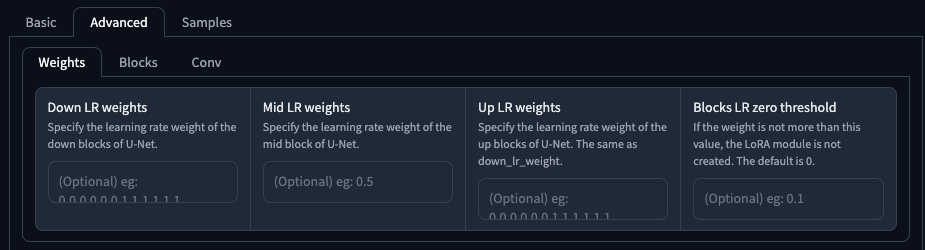
Weights
針對 U-Net 的分層做出獨立的學習率權重設定,分為,
| 參數 | 說明 |
|---|---|
Down LR weights |
針對 IN 層設定獨立的學習率權重,總共 12 個數字。 |
Mid LR weights |
針對 M00 層設定獨立的學習率權重,1 個數字。 |
Up LR weights |
針對 OUT 層設定獨立的學習率權重,總共 12 個數字。 |
Blocks LR zero threshold |
當 U-Net 區塊學習率低於此設定值時,該區塊不儲存(捨棄)。 |
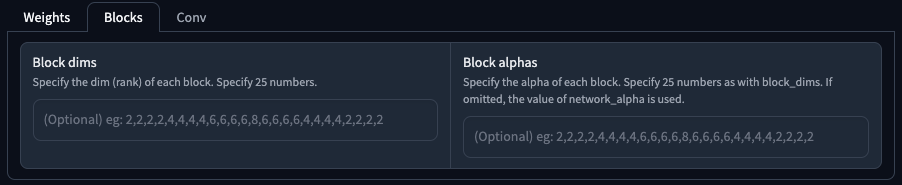
Blocks
針對 U-Net 的分層做出獨立的 Network Dim/Alpha 設定,分為,
| 參數 | 說明 |
|---|---|
Block dims |
針對每一個分層獨立設定 Dim,共 25 個數字。 |
Block alpha |
針對每一個分層獨立設定 Alpha,共 25 個數字。 |
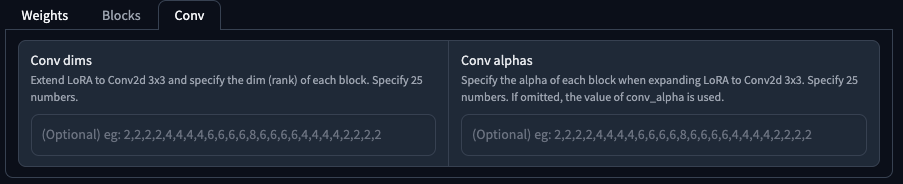
Conv
在 Lora 擴展到 Conv2d 3x3 時,針對分層做出獨立的 Network Dim/Alpha 設定,分為,
| 參數 | 說明 |
|---|---|
Conv dims |
針對每一個分層獨立設定 Dim,共 25 個數字。 |
Conv alpha |
針對每一個分層獨立設定 Alpha,共 25 個數字。 |
No token padding
更新:在新版本的 Kohya-ss 的 Lora 訓練當中,已經取消該設定。
在訓練過程中,如果標記(Token)小於 75 個字元,則將標記填充到 75 個字元。這個參數可以將「填充」的動作關閉。預設關閉,但建議你可以打開他。
Gradient accumulate steps
梯度累加功能,在原始訓練中,每一個 batch 做一次梯度計算,然後根據梯度來更新學習網路參數。預設值為 1。如果這個數字變大,則表示每一個 batch 在梯度計算後不清空,也不更新網路參數,而是累加到指定次數後,才更新學習網路參數。一方面來說,這個設定可以減低對於 Total batch size 的高需求,雖然兩者對於總訓練步數的影響相同,但兩者訓練出來的結果是不同的。
舉例來說,Total batch size 為 4,代表每次載入 4 張圖片,然後做一次(1 batch)更新,倘若 Gradient accumulate steps 設定為 2,則會在第二次(2 batch)後,才更新資料(也就是讀取了 8 張圖片)。這個情況會跟 Total batch size 設定為 8 很類似(但是不一樣!)
增加這個數字會加快學習的速度(因為總訓練步數降低),但同時也需要更多的 VRAM 來運作。
預設是 1。
Weighted captions
這個是因應 Stable Diffusion WebUI 中對於 Token 的特殊權重寫法,若你想要強調某個字詞,可以使用 :數字 來強調,例如 (black:1.3) cat 用來強調 black 這個字詞。在訓練的提示詞當中,如果你想要這麼使用,你可以開啟這個設定。
Prior loss weight
當你有使用正規化(Regularisation)資料集時,此設定才有效。這個數值決定了訓練過程中,對於正規化資料集的重視程度,如果設定為 1 則訓練特徵會更偏向於正規化資料集。此項目用於對「訓練集」與「正規化資料集」的泛化與特徵區分有所幫助。
VAE
可以指定一組 VAE 給訓練的資料。
Additional parameters
在 Kohya_ss GUI 中沒有顯示出來的其他設定,可以透過這個欄位來寫入(或覆寫)。例如 --face_crop_aug_range="2.0,4.0" --network_train_unet_only。
Save every N steps
根據訓練的步數來儲存 Lora 結果,例如總訓練步數為 1,000,此處設定 200,那麼 Lora 訓練中,就會以 200, 400, 600, 800 步數結束時,分別儲存一個訓練結果。
Save last N steps
如果有使用 Save every N steps 則此設定才會生效。此設定的用意在於保存最近 N 步數的 Lora 訓練結果。例如總訓練步數為 1,000,Save every N steps 設定為 200,此處設定為 300,則他會只保留最近 300 步的訓練結果。換句話說,當訓練跑到 600 步時,將會刪除早於 300 步以前的資料,也就是說 200 步所儲存的 Lora 將會被刪除。
Save last N steps state
與 Save last N steps 雷同,但是是針對有開啟 Save training state 的情況下,用於捨棄所儲存過的訓練狀態(state)。
Keep n tokens
當有啟用 Shuffle caption 時,這個數字可以限制多少個標記不會被亂數打亂。例如,black cat, sitting, eat,設定為 1 時,則 black cat 會被固定。若不啟用 Shuffle caption 則此項目不會有效果。
Clip skip
文字編碼器採用 CLIP 機制,由 12 個相似的層組合而成。在標記(Token)通過 12 層轉換成向量之後,最後一層將會被送到 U-Net 的 Attention 模組中。這裡的設定值是指定在這 12 層當中,要 跳過倒數第 N 層,然後將該層的資料送往 U-Net。
市面上之所以建議使用 -2 是因為 Novel AI 的模型的關係(不解釋)。所以會有二次元使用 2,而真實人物使用 1 的說法。
Max Token Length
標記數量的長度,預設使用 75,如果你的描述很長(或很多),你可以用更大的數字。
Full fp16 training (experimental)
實驗性功能,如果 Mixed precision 使用 fp16 或 bf16 時,啟用這個項目,會將所有訓練權重數據精度都對齊 fp16,這樣做可以節省一點 VRAM,但是也可能會降低學習精度。預設關閉。
Required bitsandbytes >= 0.36.0, Full bf16 training (experimental)
同上,但是給 bitsandbytes >= 0.36.0 的設定。
Gradient checkpointing
啟用梯度檢查功能,主要的目的是要縮減 VRAM 的使用,但會增加訓練的時間。啟用或關閉此功能,對於 Lora 最終的訓練結果並沒有影響。
Shuffle caption
隨機打亂提示詞的順序,提示詞檔案以逗號分隔的情況下會生效。一般來說,提示詞的順序越前面,它所代表的權重會越大,在提示詞文件中,因為順序固定,所以最後面的提示詞學習效果可能不佳,爾或順序較前面的提示詞產生非預期關連,為了避免這些狀況,所以可以在每次讀取訓練圖片時,隨機打散提示詞順序,來修正訓練產生的偏差。
預設關閉,但建議打開。
Persistent data loader
在每一個 Epoch 訓練時所產生的數據,進入下一個 Epoch 時會全數丟棄。若啟用此項目,會保留前一次的訓練資訊,以便快速的進行下一次(Epoch)訓練。開啟此項目會需要更多的記憶體來保存資料。
預設關閉。
Memory efficient attention
抑制 VRAM 的使用來進行注意力區塊(Attention block)的處理,當你的 VRAM 偏低時,請開啟此項目。
預設關閉。
CrossAttention
注意力區塊(Attention block)處理的函示庫,預設使用 xformers。
Color augmentation
色彩增強,在每次學習時會針對圖片的色調(Hue)作隨機的改變,讓訓練的結果有些微的色調變化。在 Cache latents 開啟時不可用。
預設關閉。
Flip augmentation
水平翻轉,在訓練時隨機水平翻轉訓練圖片,對於學習對稱的物體時會有所幫助。
預設關閉。
Min SNR gamma
是一種用於優化損失函數來增強訓練穩定性的方法,論文建議使用 5,如果你覺得不好,可以自己試試看其他的數字。
Don't upscale bucket resolution
當啟用這個選項時, Minimum bucket resolution 與 Maximum bucket resolution 會被忽略,並且使用 Max resolution 來裁切資料集(但不會放大)。
預設為開啟。
Bucket resolution steps
在使用資料桶(bucket)時,依照這個數字(steps)來對每個資料作分桶的動作。以預設 64 的數值為例,如果 Max resolution 為 512,512,而每個 steps 為 64,那麼訓練資料分桶將分為 512, 448, 384,... 依此類推。但若有 500 畫素(Pixel)的圖片,他將會被放到 448 的資料分桶中,並裁切成 448。
Random crop instead of center crop
在使用資料桶(bucket)時,啟用隨機裁切來取代從中心擴展裁切。在 Cache latents 開啟時不可用。
預設關閉。
V Pred like loss
使用類似 SD 2 的 v 參數化(v_parameterization)的方式來進行學習。
預設關閉。
Min Timestep / Max Timestep
在訓練的過程中,輸入的資料圖片會隨機的被噪訊化,這兩個數值在穩定擴散模型中,代表了噪訊強度的最小、最大值(0 ~ 1000)。修改這兩個數值對於專門訓練給 img2img 的 Lora 效果會比較好。
Noise offset type
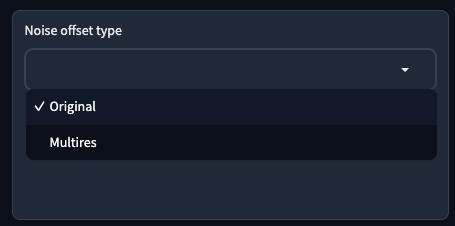
用來指定在訓練圖像中加入額外噪點的方法,加入噪點可以影響訓練圖片的可預測性。這邊提供兩種方式,
| 參數 | 說明 |
|---|---|
Original |
原始噪點 |
Multires |
多重噪點 |
Noise offset
當 Noise offset type 選擇 Original 可使用。
噪訊偏移的數量,可以接受值為 0 到 1 之間的數字。都市傳說 0.1 可以讓畫面更亮(或更暗),預設為 0。
個人認為可以不使用,或是你想實驗的話也可以試試看。
Adaptive noise scale
當 Noise offset type 選擇 Original 可使用。
搭配 Noise offset 使用,範圍從 -1 到 1,用來增強或削弱噪訊偏移的數量,預設為 0。

Multires noise iterations
當 Noise offset type 選擇 Multires 可使用。
同樣是增加噪訊偏移,但這邊所指定的是增加多少個噪訊偏移迭代次數,預設為 0。
Multires noise discount
當 Noise offset type 選擇 Multires 可使用。
搭配 Multires noise iterations 使用,範圍從 0 到 1,用於在一定程度上削弱各種解析度下的噪訊偏移。預設為 0,但當使用 0 時,訓練會預設採用 0.3 的數值。
Dropout caption every n epochs
設定在多少個 Epochs 下不訓練提示詞。舉例來說,如果你寫 2,那麼在第 2, 4, 6, 8... 次的 Epochs 將不會訓練提示詞,僅訓練 U-Net。
預設為 0。
Rate of caption dropout
捨棄提示詞的比例,他會在訓練時取用一個隨機數,並且在這個隨機數小於你的捨棄比例時,會將你的提示詞給丟棄。舉例來說,如果你的設定是 0.1,那麼如果 random.random() 取得的亂數比你設定的數值還大,那麼這個 Token 會被保留。
以我熟悉的 Javascript 來舉例大概是這樣,
// 我們輸入的
tokens = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
// 就是會被保留下來的
flat_tokens = []
tokens.forEach(token => {
if (random.random() >= caption_rate_dropout) {
flat_tokens.push(token)
}
})
// flat_tokens 可能是 [1, 4, 6, 8, 9] 這樣
這個比例並不是你的 Token 總長度的「比例」,而是 隨機依照你所設定的比重,隨機的丟棄。
跟 Dropout caption every n epochs 類似,但是是以總訓練步數的 % 數量來決定多少訓練集不使用提示詞訓練。舉例來說,50 張圖片,重複 20 次,跑了 3 個 Epochs,那麼總步數會是 20 x 50 x 3 = 3000,如果在此設定了 0.2,那麼會有 1000 x 0.2 = 200 張圖片不使用提示詞訓練。而這 200 張圖片是隨機的。
預設為 0。
VAE batch size
如果啟用 Cache latents 項目,則這個數字可以指定在記憶體中儲存中,存放多少壓縮圖像資料。通常來說,由於 Total batch size 指定了一次學習的數量,所以這個數字與 Total batch size 相同是比較合理。
預設為 0,代表此設定與 Total batch size 相同。
Save training state
如果你的 Epochs 很多,或是總訓練步數很長,在需要長時間的情況下,勾選此項目可以在中斷訓練後,保存訓練過程,用以接續訓練。中間的訓練資料會以你的模型名稱加上 -state 的方式儲存在 Output folder 資料夾中。
預設關閉。
Resume from saved training state
當你中斷訓練,或是想從之前的訓練繼續訓練時,可以將 Save training state 的資料夾填入此欄位,用以接續訓練。
Max num workers for DataLoader
此選項指定讀取訓練資料時要使用的 CPU 進程數。增加這個數量將會啟用線程並提高讀取資料的速度,但是增加太多實際上可能會導致效率低下。注意,無論指定多大的數量,都不會超過所使用的 CPU 的併發執行緒數。
預設為 0,僅在 CPU 的主進程中載入資料。個人建議你留空白就好,新版預設填寫 0 是沒有問題的,我個人習慣填寫 8(因為我有 16 個併發執行緒可用)。
後記
希望不要一直改版(笑)

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)