
![[Kohya_ss] 訓練優化器與超參數](/content/images/size/w960/2023/06/00295-c7320a8e.png)
說在最前面的,在 Lora 訓練當中,各種優化器(Optimizer)都有自己專屬的超參數(Hyperparameter)。對於模型訓練而言,超參數的影響並不會非常巨大,所以,在你決定調整超參數之前,請先確保你的模型已經足夠好了。不然花在這上面的時間,很可能會是浪費掉的。
Kohya_ss 版本說明
在本次的紀錄當中,我所使用的 Kohya_ss 的版本是 v21.7.8,所以若你想要參考本次文章的內容,請先確保你所使用的版本跟我是一樣的。
常用優化器與超參數
目前在 Kohya_ss 當中,目前有支援以下的優化器可以使用:
- AdamW
- AdamW8bit
- Adafactor
- Dadaptation
- DadaptAdaGrad
- DadaptAdam
- DadaptAdan
- DadaptAdanIP
- DadaptAdamPreprint
- DadaptLion
- DadaptSGD
- Lion
- Lion8bit
- Prodigy
- SGDNesterov
- SGDNesterov8bit
我是很想跑完上面所有的優化器,但是我沒有那麼多時間,所以我只跑了幾個我比較常用的優化器,
- AdamW8bit
- Adafactor
- Dadaptation
- Lion
如果你想要知道其他優化器的結果,可以自己跑一下,或是等我有空的時候再來更新。上面四個我比較慣用也常用的優化器,在 Pytorch 或原始碼裡面都可以查到屬於他們自己的超參數。
AdamW8bit
基本上他就是 AdamW 的 8bit 版本,常見訓練可用的超參數有:
betas (Tuple[float, float], optional):
coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
weight_decay (float, optional):
weight decay coefficient (default: 1e-2)
Adafactor
這個自動學習率的優化器,使用的是 Huggingface transformer 的版本,常見訓練可用的超參數有:
weight_decay (`float`, *optional*, defaults to 0):
Weight decay (L2 penalty)
relative_step (`bool`, *optional*, defaults to `True`):
If True, time-dependent learning rate is computed instead of external learning rate
warmup_init (`bool`, *optional*, defaults to `False`):
Time-dependent learning rate computation depends on whether warm-up initialization is being used
Dadaptation
這是 Facebook 推出的優化器,他有一系列的相關優化器。我這邊僅提出 Dadaptation,常見訓練可用的超參數有:
betas (Tuple[float, float], optional):
coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
weight_decay (float):
Weight decay, i.e. a L2 penalty (default: 0).
decouple (boolean):
Use AdamW style decoupled weight decay (default: False).
附帶一題,在 Kohya_ss 當中,使用 Dadaptation 跟 DAdaptAdamPreprint 是一樣的。另外,好像有單純設定 decouple=True 的說法,基本上這樣沒有意義,因為 weight_decay 預設是 0。
Lion
這是 Google 所提出的優化器,常見訓練可用的超參數有:
betas (Tuple[float, float], optional):
default: (0.9, 0.99).
weight_decay (float):
Weight decay, i.e. a L2 penalty (default: 0).
weight_decay 超參數
首先,你會看到幾乎每個優化器都有 weight_decay 這個東西可以設定,他是一種類似 L2 正規化(L2 regularization)的作用參數,在 AdamW 新的實作中已經把 weight_decay 修正為 L2 regularization 的作用(在 Adam 當中並不是等價的)。具體 L2 正規化可以參考這一篇文章 L1 , L2 Regularization 到底正則化了什麼 ?。畢竟我不是專業的,所以有興趣的人請自行參考。
這個參數可以讓你的訓練稍微的不會那麼爆炸,但每一組優化器所使用的數值並不一定相同,基於這麼多訓練的結論,以下數字可參考,但非絕對,
AdamW8bit為0.1Adafactor為0.02Dadaptation為0.01Lion為0.01
請注意,以上數字僅供參考。
這個數字亂設定會怎樣?舉例來說,倘若我在 Dadaptation 把 weight_decay=1.0 這樣,跑了 3,000 步的訓練,你會發現你訓練出來的結果好像沒訓練過一樣。
betas 超參數
這個數字更偏向玄學,基本上會依照預設,或是論文建議的方向來使用。根據 Adam 這篇論文提到的 𝛽1 與 𝛽2 的描述來看,降低他們會減緩學習速度,但增加訓練步數並不會讓學習變好(可能會變得更糟)。所以,我們可以把 𝛽1 與 𝛽2 使用預設會是一個比較好的起點。
以下是我訓練時所使用的數字,僅供參考,
AdamW8bit為betas="0.9,0.999"Dadaptation為betas="0.95,0.99"Lion為betas="0.95,0.98"
請注意,以上數字僅供參考。
其餘關於訓練參數設定
目前 Kohya_ss 除了支援分層訓練外,部分基本模型中也支援 Scale weight norm ,或是 Network dropout, Rank dropout, Module dropout 等等。關於 Scale weight norms, Network dropout 可參考 PR#545 的說明。最主要的目的就是拋棄訓練的部分權重跟神經元,讓訓練可以更加多樣化,避免過度擬合的情況。
如果你不知道這些東西是什麼,請不要使用,讓他維持預設的 0 就好了。
關於學習率與步數
目前比較常使用的 AdamW8bit 相信大家都沒什麼問題。你可以使用 Unet Learning rate 1e-4 來當作一個開始,至於 Text Encoder learning rate 則可使用 5e-5 來開始。以下是我在 AdamW8bit 慣用數字,
- Unet Learning rate:
2e-5 - Text Encoder learning rate:
1e-6
請注意,以上數字僅供參考。
至於步數,基本上在 6,000 至 18,000 之間跳動,端看訓練集的資料大小而決定。另外,有一件事情還是得說明一下,
1 Epoch x 120 Repeats x 100 Images = 12,000 Steps
10 Epoch x 12 Repeats x 100 Images = 12,000 Steps
以上兩件事情訓練出來的模型並不等價,我會建議使用 後者,簡單來說,就是要 訓練 10 次 完整的訓練集,箇中差異你可以自己實驗看看。
自動學習率的 Adafactor 則是將 Unet/Text Encoder 都寫 1 讓他自己去跑,至於產出的結果,就會跟你的訓練集、總步數的部分有關。
而 Dadaptation 則還是得設定 Unet/Text Encoder,也有人建議使用 1,但是這個數字取決於你的訓練集、總步數的設計。如果你的總步數偏低(若約 3,000 步),那麼你可以使用 0.7 ~ 0.4 來開始,然後依照產出的結果慢慢調整(看是要調高、或是調低),步數高的話,可以從 0.5 ~ 0.2 開始(如果是 12,000 步的話)。
至於 Lion 則比較敏感一點,我目前在 Lion 所使用的 Unet 學習率約從 1e-4 開始往下降(也是有調高的例子),然後,因為基於 Lion 論文所述,所以相較於 AdamW8bit 的設計,根據 LyCORIS 的作者所述,他需要大概 4 倍左右的 Batch Size 來運作才能獲得差不多的結果。
所以,在 Lion 的訓練中,我使用 Total Batch Size 為 2 的情況下,我在 Gradient accumulate steps 會設定為 4 來跑相關訓練。
測試訓練結果
以下是以四種優化器,除了學習率、超參數與 Gradient accumulate steps 設定不同(針對 Lion)外,其餘設定皆相同,訓練步數為 3,004 步(Lion 因為 Gradient accumulate steps 為 4 的關係,總步數僅 751 步),不使用正規化資料集。四種優化器的訓練時間平均約為 28 分鐘(Lion 雖然因為設定的關係步數減少了 1/4,但是總訓練時間不變)。
Dadaptation- Unet/Text Encoder 學習率
0.4 - 超參數
decouple=True weight_decay=0.02 betas="0.9,0.99"
- Unet/Text Encoder 學習率
Adafactor- Unet/Text Encoder 學習率
1.0 - 超參數
relative_step=True weight_decay=0.02
- Unet/Text Encoder 學習率
AdminW8bit- Unet 學習率
0.0001 - Text Encoder 學習率
0.00002 - 超參數
weight_decay=0.1
- Unet 學習率
Lion- Unet 學習率
0.0001 - Text Encoder 學習率
0.00002 Gradient accumulate steps設定為4- 超參數
weight_decay=0.01 betas="0.95,0.98"
- Unet 學習率

這是訓練記錄圖表,
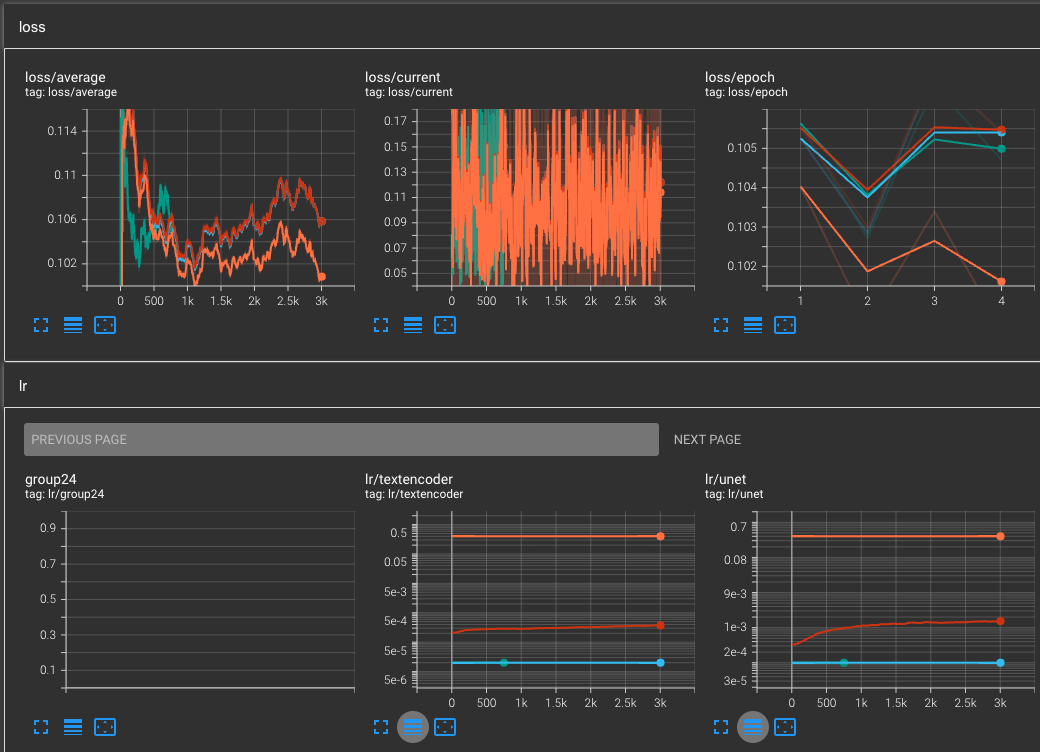
橘色的是 Dadaptation,紅色的是 Adafactor,淡藍色的是 AdamW8bit,綠色的是 Lion。因為 Lion 使用與 AdamW8bit 相同學習率,所以學習率圖表是重疊的。
不要問我為何學習率不同,Loss 走勢看起來都很像,當你練壞上百個就會知道了。
至於穩健性,由於沒有使用正規化資料集,所以目前無法判斷倒底是好還是不好。泛型?你換一下髮色就知道了。

這樣跑一次下來,你就會知道在這麼短的訓練步數中,你若是要快速擬合,就不要任意更動超參數(雖然有些調整確實可以避免過擬合發生),但是在無法確認是否對於你的訓練資料集有幫助的情況下,能照預設值,就用預設值就好了。
真的要說以 Dadaptation 超參數優化,也不是不行,但就是得花時間調教跟測試,

上圖的 v208 總步數用 Epochs 去換,大概是原有的 2 倍,共 8 個 Epoch,學習率在 0.5 左右,並且放入平衡步數後的正規化資料集。
由於正規化資料集的緣故,步數會再 2 倍,此時所使用的超參數為:
decouple=True weight_decay=0.8 betas="0.9,0.99"
同樣都是使用 Dadaptation,針對總步數、學習率搭配超參數做調整,同樣的資料集下,就能得到相當不錯的結果。
給剛入門訓練的建議
以目前這麼多優化器可以選擇的情況下,扣除資料集的準備(目前先不論正規化資料集),剩下的就是各種設定的選擇。如果你的資料集只有一個概念,約 20 張照片(無論風格、人物),那麼以下的訓練參數可以當作一個開始。
- 資料夾設定為
25_Concept。 - 換算下來你的 Repeats 為
500。 - Folder 裡面的 Logging folder 填寫一個資料夾來儲存訓練的 Log 記錄(給 Tensorboard 使用)。
- LoRA type 為
Standard。 - Total batch size
1。 - Epoch 設定為
6。 - 換算下來,總步數為
3,000步。 - 優化器選擇
Adafactor。 - Unet/Text Encoder Lr 都寫
1。 - LR Scheduler 使用
constant。 - LR warmup (% of steps) 使用
0。 Optimizer extra arguments填寫relative_step=True。- Network Rank (Dimension)
128。 - Network Alpha 設定
1。 - Additional parameters 設定
--min_bucket_reso=320 --max_bucket_reso=768,使用 ARB(如果你圖片尺寸沒有特別處理過)。 - 如果你要訓練人臉的話,Additional parameters 增加設定
--face_crop_aug_range="2.0,4.0"。 - Clip skip 設定
2,若訓練真人模型可設定1。 - 以下選項打勾
Shuffle caption,Use xformers,Persistent data loader,Don't upscale bucket resolution。 Flip augmentation若訓練目標有特殊特徵不可翻轉,就不要打勾,如果沒有建議你勾起來試試看。- Min SNR gamma 使用論文推薦
5。
其他的都不需要更動,然後就可以開始訓練。開始之後,可以去啟動 Tensorboard,就能看到訓練的 Log 圖表。至於圖表的部分我就不多做解釋了,最主要的是要看看你有沒有訓練到爆炸的情況,如果有的話,就要調整一下訓練參數(或是重開 Kohya_ss)。如果沒有的話,那麼就可以繼續訓練,等到訓練完畢之後,就可以開始測試看看訓練結果了。
另外,有一種狀況是你訓練感覺沒事,然後 Lora 不能用的情況。你在 SD 套用 Lora 的時候他跟你說這些訊息,
NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
這個多半是練壞掉(A tensor with all NaNs was produced in Unet.),但圖表可能會沒事。
小結
在使用 Adafactor 或 Dadaptation 後,若是想要繼續優化模型,是可以改為 AdamW8bit 繼續訓練,參數的部分可以把學習率降低為原本的 1/3 或 1/10 甚至更低,然後繼續訓練,這樣可以讓模型更加穩定,但是 Epoch 數量增高,代表步數會更多,訓練時間會更長。
一切都是用大把時間換來的結果,就看是不是有那個需要了。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)