
![[ComfyUI] AnimateDiff 影像流程](/content/images/size/w960/2023/11/animateDiff_cover.jpg)
主要是一些操作 ComfyUI 的筆記,還有跟 AnimateDiff 工具的介紹。雖然說這個工具的能力還是有相當的限制,不過對於畫面能夠動起來這件事情,還是挺有趣的。
AnimateDiff 介紹
AnimateDiff 是一個用來生成 AI 影片的工具,這個工具的原始碼是開源的,可以在 Github, AnimateDiff 裡面找到。如果對論文有興趣的人也可以去查閱。
基本上在 AnimateDiff 的管道(pipeline)設計中,主要的目的是在強化創造力,採用了兩個步驟,
- 預先載入一個動作模型(Motion model),用來提供影片所需要的動作驗證。
- 載入主要 T2I 的模型(Base model),並保留此模型 T2I 的特徵空間。
接下來,在已經預訓練好的動作模型(Motion model)會將原有的 T2I 模型特徵轉化為一個動畫生成器,這個動畫生成器會根據所提供的文字描述(Prompt),來生成多樣化的動畫影像。
最後,AnimateDiff 會做一次迭代降噪(Denoising)的過程,用來提升動畫的品質。降噪的過程其實是每次逐步的減少噪音(noise)跟一些鬼影(主要是繪製過程中所產生的不正確影像)。
基本系統需求
t2vid 最少需要 8GB VRAM,在使用 512x512 的解析度與 2 個 ControlNets 的情況下,這是最低的需求,有些情況下,這樣的設定可能會使用到最高 10GB VRAM 的狀況。
如果是 vid2vid,那麼最少需要 12GB VRAM 或以上。由於我這邊的筆記使用了 3 個 ControlNets,所以最高使用到的 VRAM 有機會高達 14GB,所以如果真的不行的話,可以減少 ControlNet 的數量,或是降低解析度。
ComfyUI 需要安裝的套件
首先你需要有 ComfyUI 這個工具。如果你是 Windows 的使用者,他還有提供完全免安裝版本的壓縮檔,可以直接下載使用。
ComfyUI Standalone Portable Windows Build (For NVIDIA or CPU only), 1.44GB
如果你是 Linux 的使用者,那麼你就需要自己安裝 ComfyUI ,這邊我就不多做介紹了。
你可以先安裝 ComfyUI-Manager 後,再透過 ComfyUI-Manager 來安裝剩下的套件。
以下兩個套件是必要安裝,不然 AnimateDiff 會無法正常運作。請注意,我這邊安裝的是 ComfyUI-AnimateDiff-Evolved 套件,與 ArtVentureX 提供的不同,請留意不要裝錯。
- https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
- https://github.com/Kosinkadink/ComfyUI-Advanced-ControlNet
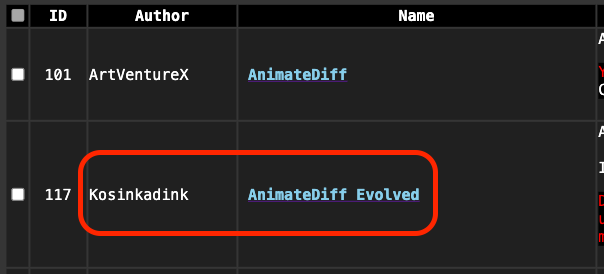
另外,以下是搭配 AnimateDiff 常用套件,或是你有下載過我提供的 Workflow 的話,那麼你應該就不需要再安裝了。
- https://github.com/FizzleDorf/ComfyUI_FizzNodes
- https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
- https://github.com/Fannovel16/comfyui_controlnet_aux
最後是我個人常用,
- https://github.com/ltdrdata/ComfyUI-Impact-Pack
- https://github.com/ltdrdata/ComfyUI-Inspire-Pack
- https://github.com/WASasquatch/was-node-suite-comfyui
- https://github.com/RockOfFire/ComfyUI_Comfyroll_CustomNodes
- https://github.com/ssitu/ComfyUI_UltimateSDUpscale
- https://github.com/TinyTerra/ComfyUI_tinyterraNodes
AnimateDiff 的模型
動作模型與動作 Lora 可以在這邊下載,
另外推薦幾個,可以用來生成動畫的動作模型,
這些模型檔案需要放在這個資料夾裡面,
ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/models
如果是下載動作 Lora,則需要放在這裡,
ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/motion_lora
下載好了之後,如果你有需要用到 ControlNet,請自行把要用到的檔案,放到這裡,
ComfyUI/models/controlnet
當然,你的主模型需要放在 ComfyUI/models/checkpoints 裡面。而如果有 VAE 的話,則需要放在 ComfyUI/models/vae 裡面。
AnimateDiff 的節點介紹
一開始,我們需要載入圖片或是影片,需要用到 Video Helper Suite 這個模組,用來製作影片的來源。
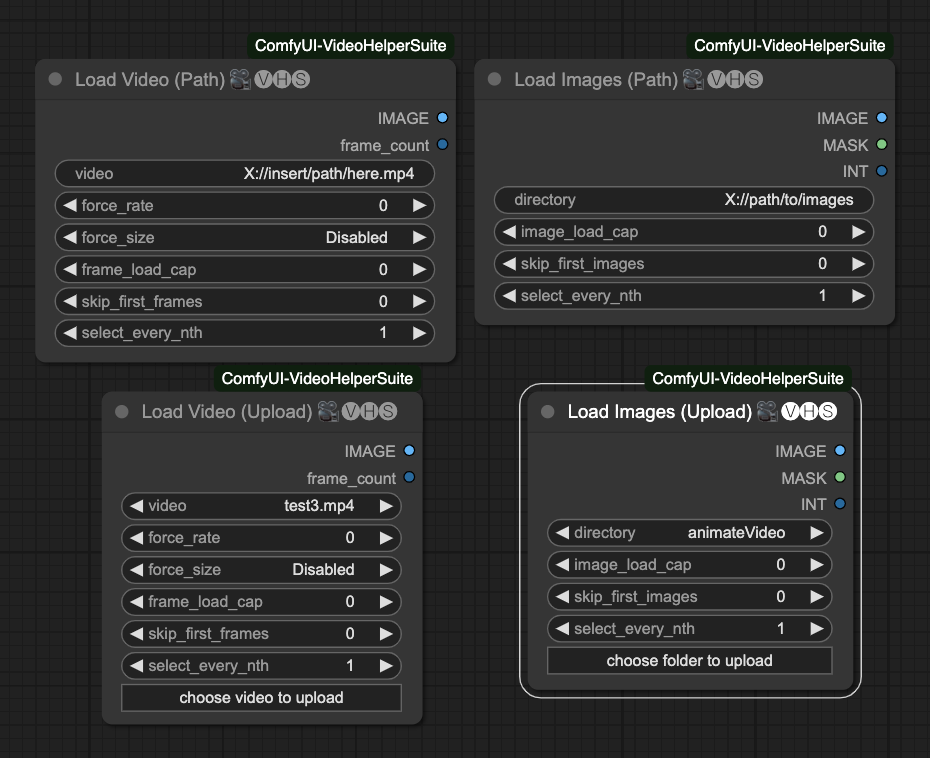
他總共有四種載入方式,
- Load Video (Path) 用路徑載入影片。
- Load Video (Upload) 上傳影片。
- Load Images (Path) 用路徑載入圖片。
- Load Images (Upload) 上傳圖片資料夾。
裡面的參數有這些,
image_load_cap預設0,就是載入所有圖片來當作幀數。你也可以填寫一個數字,來限制載入的圖片數量。他會決定你最後動畫的長度。skip_first_images設定一個批次開始的時候要跳過幾張圖片。force_rate讀取影片時,強迫使用這個 FPS 來提取圖片。force_resize強迫將圖片轉換成這個解析度。frame_load_cap預設0,就是載入所有影片幀數。你也可以填寫一個數字,來限制載入的影片幀數數量。他會決定你最後動畫的長度。skip_first_frames設定一個批次開始的時候要跳過的幀數。select_every_nth設定每隔幾張圖片,選取一張圖片當作幀數,預設1是每張都使用。
接著設定好一些必須節點後,我們還需要設定 AnimateDiff Loader 與 Uniform Context Options 的節點。
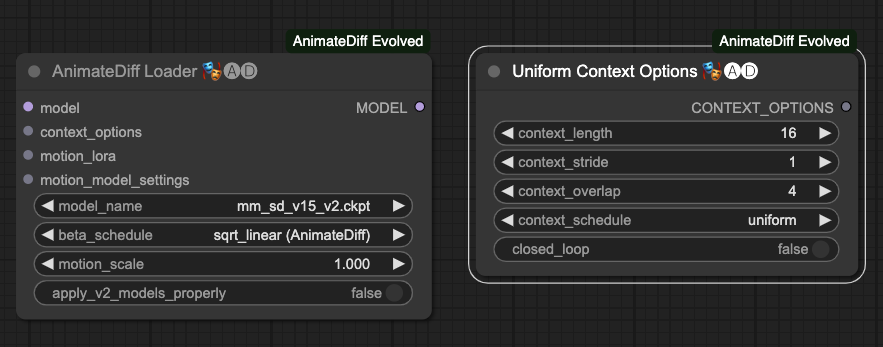
AnimateDiff Loader
AnimateDiff Loader 的參數有這些,
model外部連結過來的模型,主要是把 T2I 的模型載入進來。context_options他的來源是 Uniform Context Options 這個節點的輸出。motion_lora外部連結過來的動作 Lora,主要是把動作 Lora 載入進來。motion_model_settings進階的動作模型設定,在這邊先不贅述。model_name選擇動作模型。beta_schedule選擇排程器,預設使用sqrt_linear (animateDiff),你也可以使用linear (HostshotXL/default),兩者差異這裡暫時先不提。motion_scale動作模型的應用比例,預設1.000。apply_v2_models_properly套用v2模型的屬性,預設False。
Uniform Context Options
Uniform Context Options 的參數有這些,
context_length每一次 AnimateDiff 運作的時候,要處理多少張圖片,預設16,以目前的處理狀況來說,這個數字是不錯的。請注意!不同的動作模型會限制這個數字的最大值。context_stride預設1,這件事情很難說明,主要的目的是用於確保 AnimateDiff 在幀與幀之間能盡量保持時間同步。具體可以參考原作者說明(雖然是 A111 的部分,但差不多) WebUI Parameters。contex_overlap每一次 AnimateDiff 處理圖片時,要預留多少數量的圖片來做為上下內容的重疊,預設4。context_schedule目前僅能使用uniform。closed_loop嘗試著做一個迴圈式的動畫,預設False,在 vid2vid 的情況下不適用。
AnimateDiff LoRA Loader
主要是用來載入動作 Lora 的節點,他的參數有這些,
lora_name選擇動作 Lora 模型。strength動作 Lora 的強度,預設1.000。
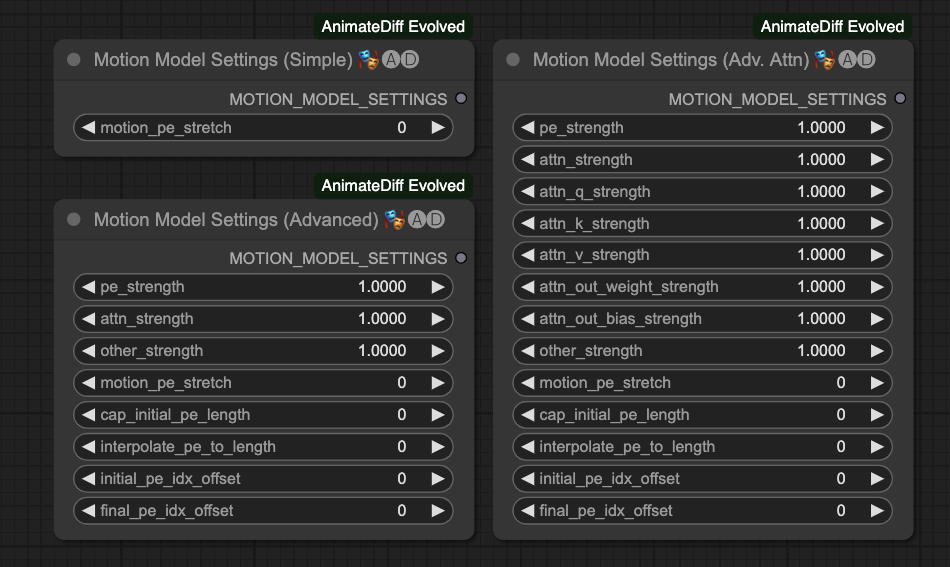
Motion Model Settings
這個節點有三種,分別可以針對動作模型進行更細緻的設定。不過由於作者並沒有對這個區塊作更詳細的描述,所以我這邊就暫時不介紹他。
Video Combine
最後,我們要使用 Video Helper Suite 裡面的 Video Combine 來輸出我們的動畫。
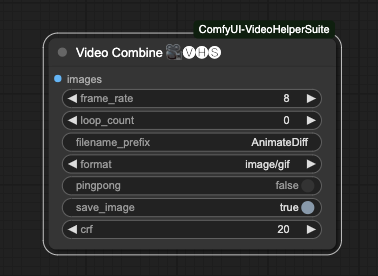
他有以下參數,
frame_rate動畫幀數,如果你輸入的時候有使用force_rate,請設定成一樣的數字。如果你是直接讀取影片,請設定成跟影片一樣的 FPS 數字。這個數字將會決定最後動畫輸出的時間長度。loop_count僅有儲存成圖片時才會生效,在圖片產出後,你的 ComfyUI 會重複播放這個影片的次數。filename_prefix儲存檔案的前綴詞,如果連續產生的話後面會自動編號。format輸出格式,目前有支援以下格式,請注意,如果你需要輸出影片,請確認你的電腦有安裝 FFmpeg,且有支援相關的壓縮、解碼函示庫。image/gifimage/webpvideo/av1-webmvideo/h264-mp4video/h265-mp4video/webm
pingpong預設False,將倒數 1, 2 影格的資料組合回原影格後,再合併所有影格,有種回聲的感覺,主要作法是frames = frames + frames[-2:0:-1]這樣組合後再處理。如果你是影片的話就別打開了吧。save_image預設True,將最後輸出的資料儲存。crf預設20,這是給影片專用的參數,全名是 Constant Rate Factor,有興趣的人請自行研究。
AnimateDiff 與 ControlNet 的結合
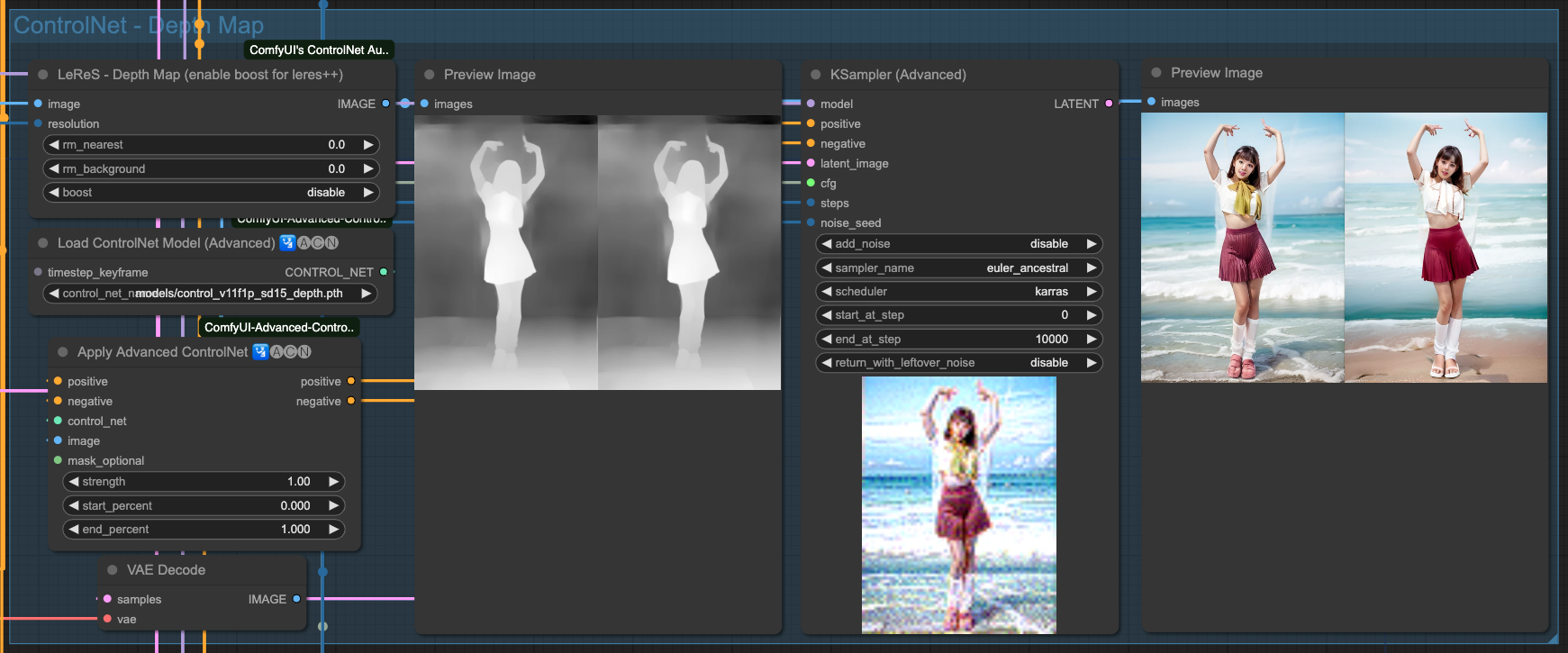
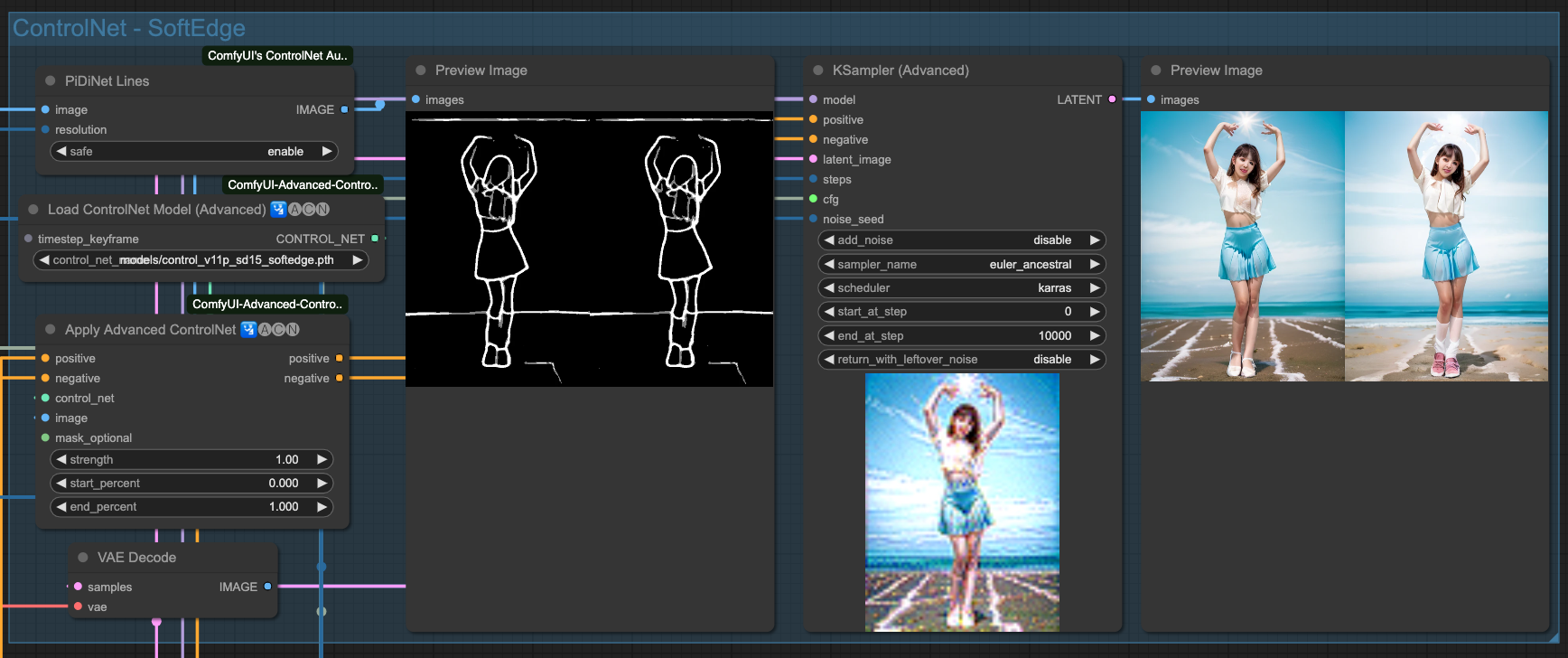
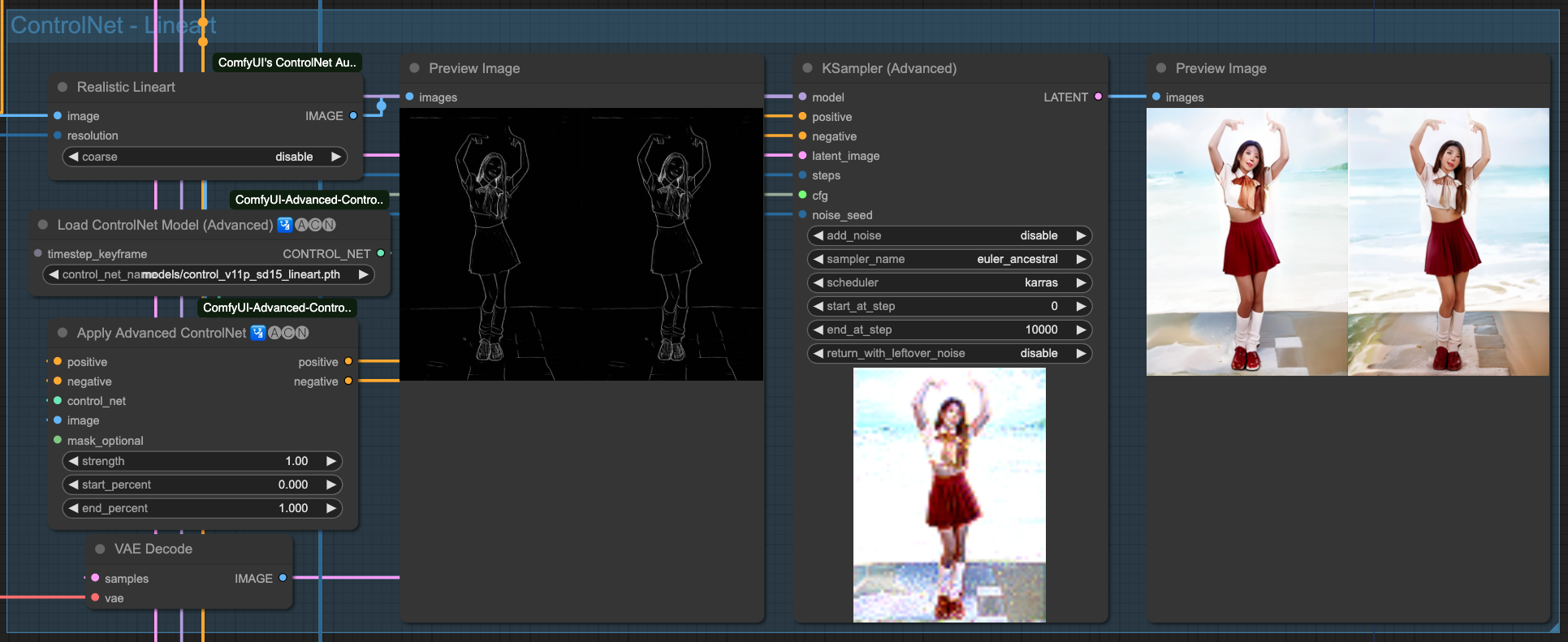
由於我們不是單純的想做 Text-To-Video 這件事情,所以,為了更準確的控制,所以我們會需要使用 ControlNet 來控制整個產出過程,讓他更趨於穩定。我這邊選用了 4 種 ControlNet 來交叉搭配操作,你也可以嘗試其他的。
- Depth 用於取出主體深度圖。
- SoftEdge 用來取出粗略邊緣。
- Lineart 用來取出細緻線稿。
- OpenPose 用來取出主體人物動作,包含手部、臉部與肢體動作。
以上都需要使用以下兩個套件,如果你文章一開始的東西都有安裝,就不需要再安裝一次了,
我這邊簡單的展示一下每一種 ControlNet 所呈現的結果,
Depth
SoftEdge
Lineart
OpenPose
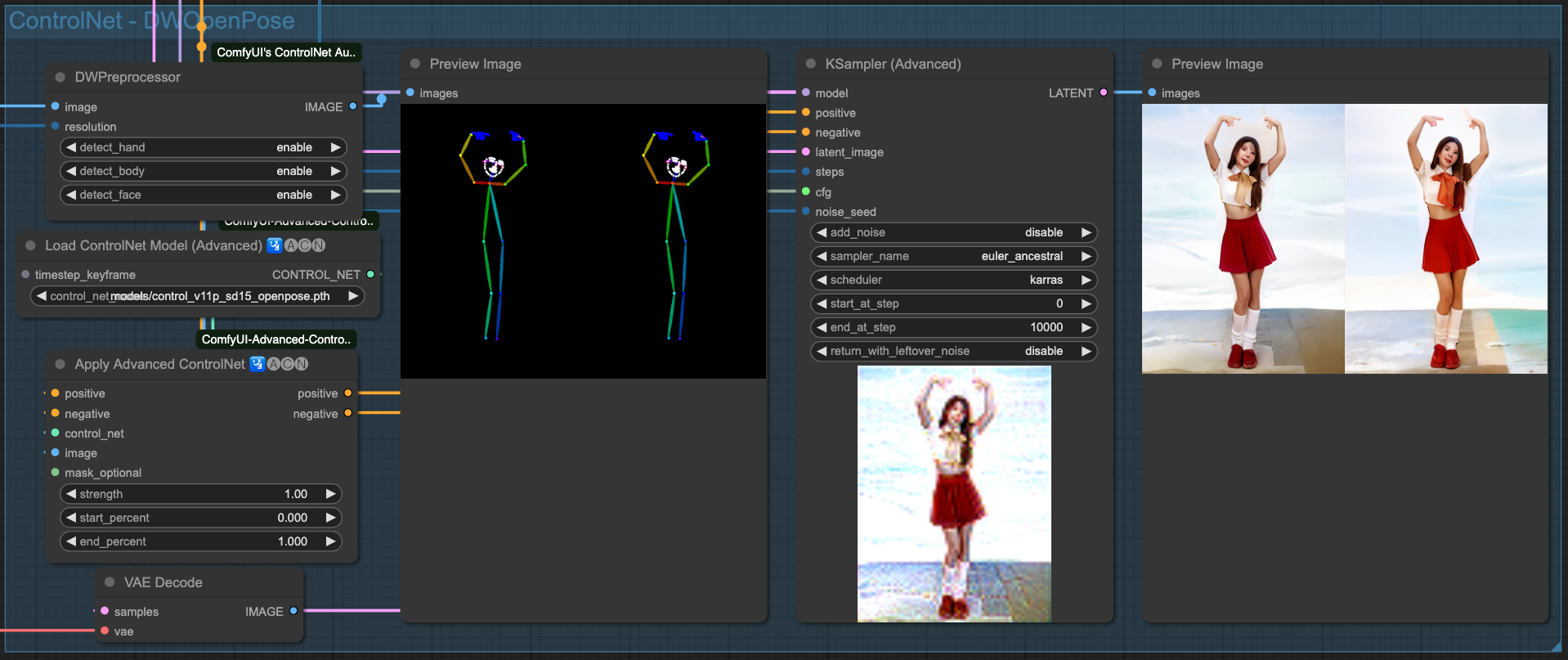
以上是 4 種 ControlNets 單獨的效果,當然,我們要把這幾個 ControlNet 串起來才用,至於要挑哪幾個去串接,沒有一定的規則,只要最後產出的結果不錯,那所使用的組合應該就可以了。
基本準備工作
接下來就是發揮 ComfyUI 創意的時候了。我這邊僅列出一些基本組合方式供大家參考。首先,懶惰的工程師如我,當然就是能不要輸入太多東西,就不要輸入太多東西,所以,利用一些 ComfyUI 的工具,讓他自動的把一些東西算出來,
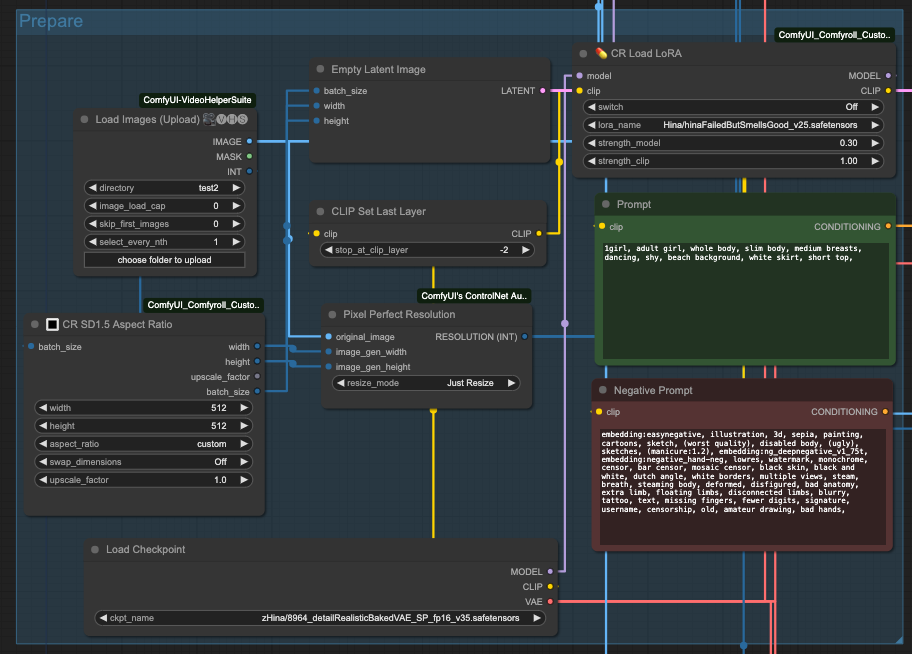
所以,我使用了 CR SD1.5 Aspect Ratio 來拿取圖片尺寸,並將他交給 Empty Latent Image 用來準備空的輸入尺寸,另外 batch_size 也從 Load Images 的 INT 輸出來獲得。
另外,由於 ControlNet 預處理器會需要一個 resolution 的輸入,所以,我使用 Pixel Perfect Resolution 並接入原始圖片(original_image)與從 CR SD1.5 Aspect Ratio 來的尺寸各別接入 image_gen_width 與 image_gen_height,讓他自行計算出一個 RESOLUTION (INT) 去當作預處理器的輸入。
接著你需要準備基底模型,正向、負向提示詞,CLIP 設定等等,然後如果你需要 Lora 就得先做好,請留意!Lora 的載入可能會讓輸出變的很慘烈,目前推測是跟 AnimateDiff 的模型有關,還需要更多的測試跟實驗,所以如果沒必要,先不要使用 Lora,或是換個地方用,大家可以自己實驗,我就不贅述了。
接著,我們需要準備 AnimateDiff 的動作處理器,
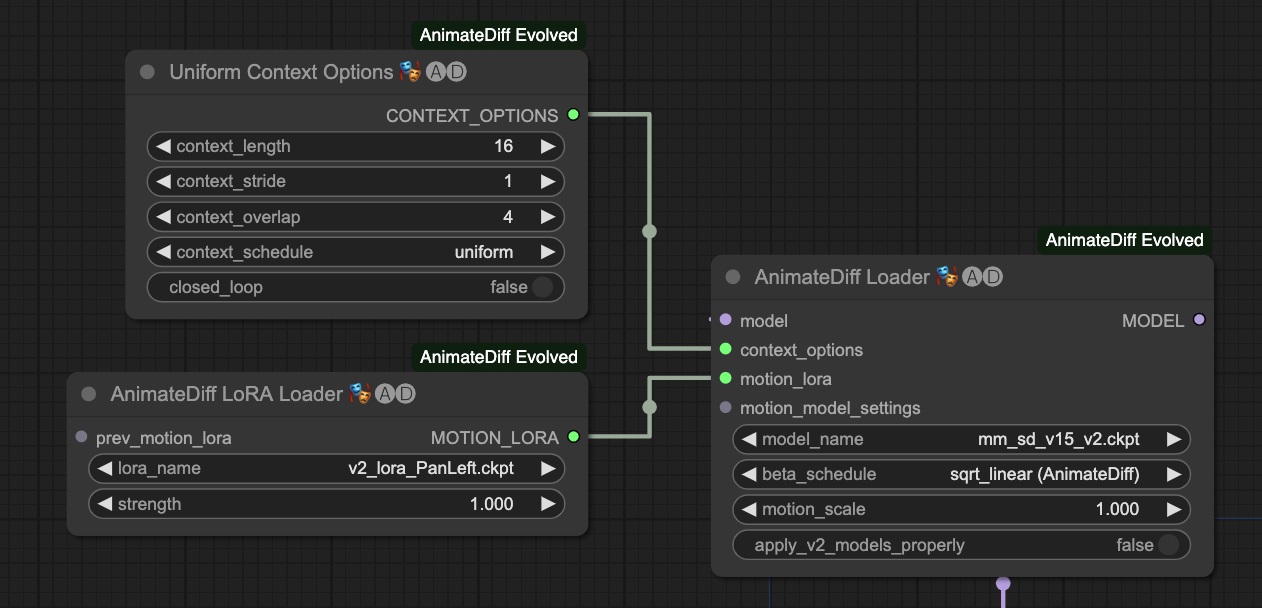
你需要 AnimateDiff Loader,然後接上 Uniform Context Options 這個節點。如果你有使用動作控制 Lora 的話,就把 motion_lora 接上 AnimateDiff LoRA Loader 來使用,如果沒有可以忽略沒關係。
指揮挺組合
有了基礎準備後,我們要把他全部接在一起,順序是這樣,
- 讀取來源(影片或連續圖片)。
- 準備基礎模型,Lora,提示詞,尺寸與解析度預處理等。
- 準備 AnimateDiff Loader。
- 把需要的 ControlNets 串起來。
- 輸出給 Sampler 去處理。
- 最後 VAE Decodes 輸出給 Video Combine 儲存。
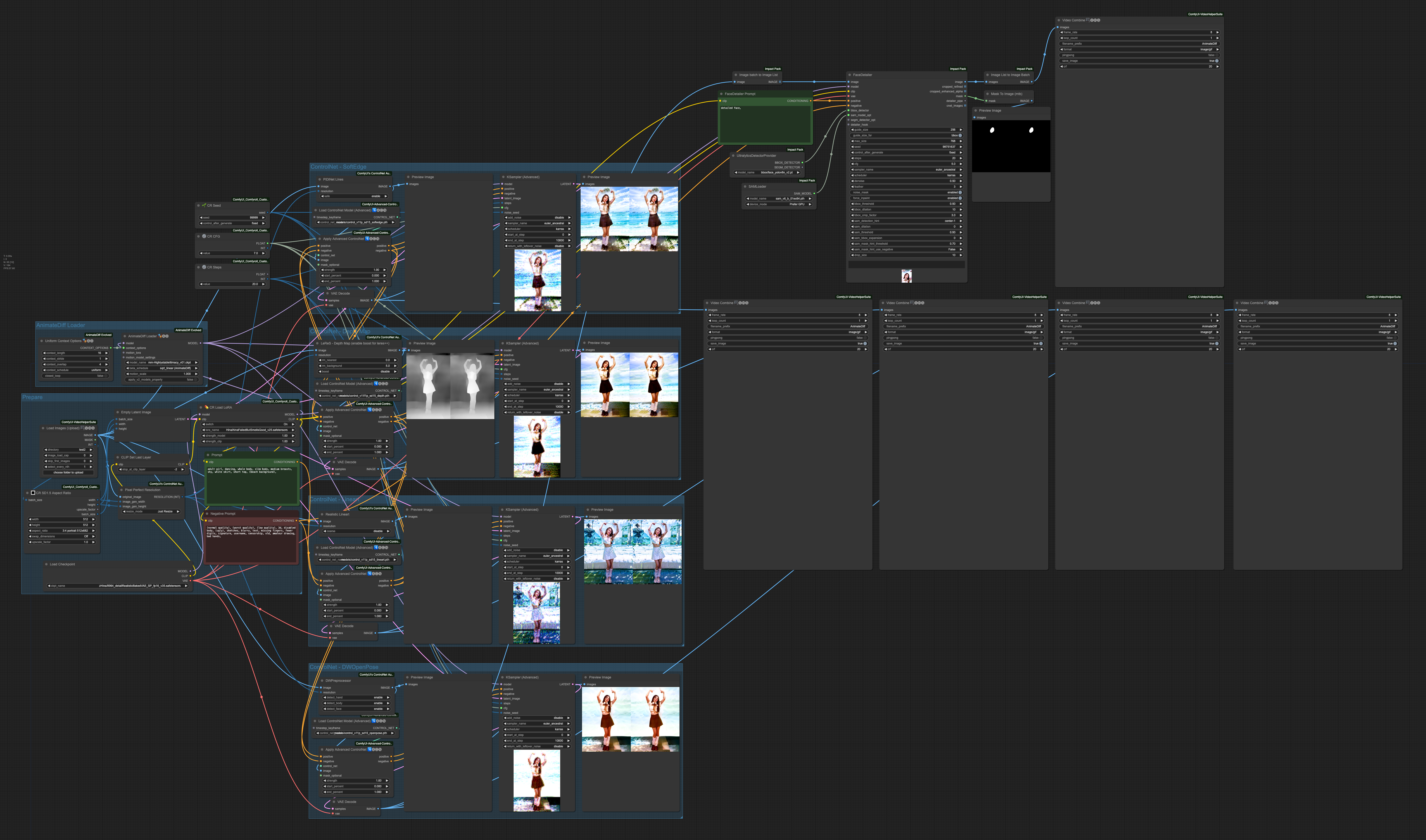
首先我們先看一下剛剛整體組合起來的樣子,
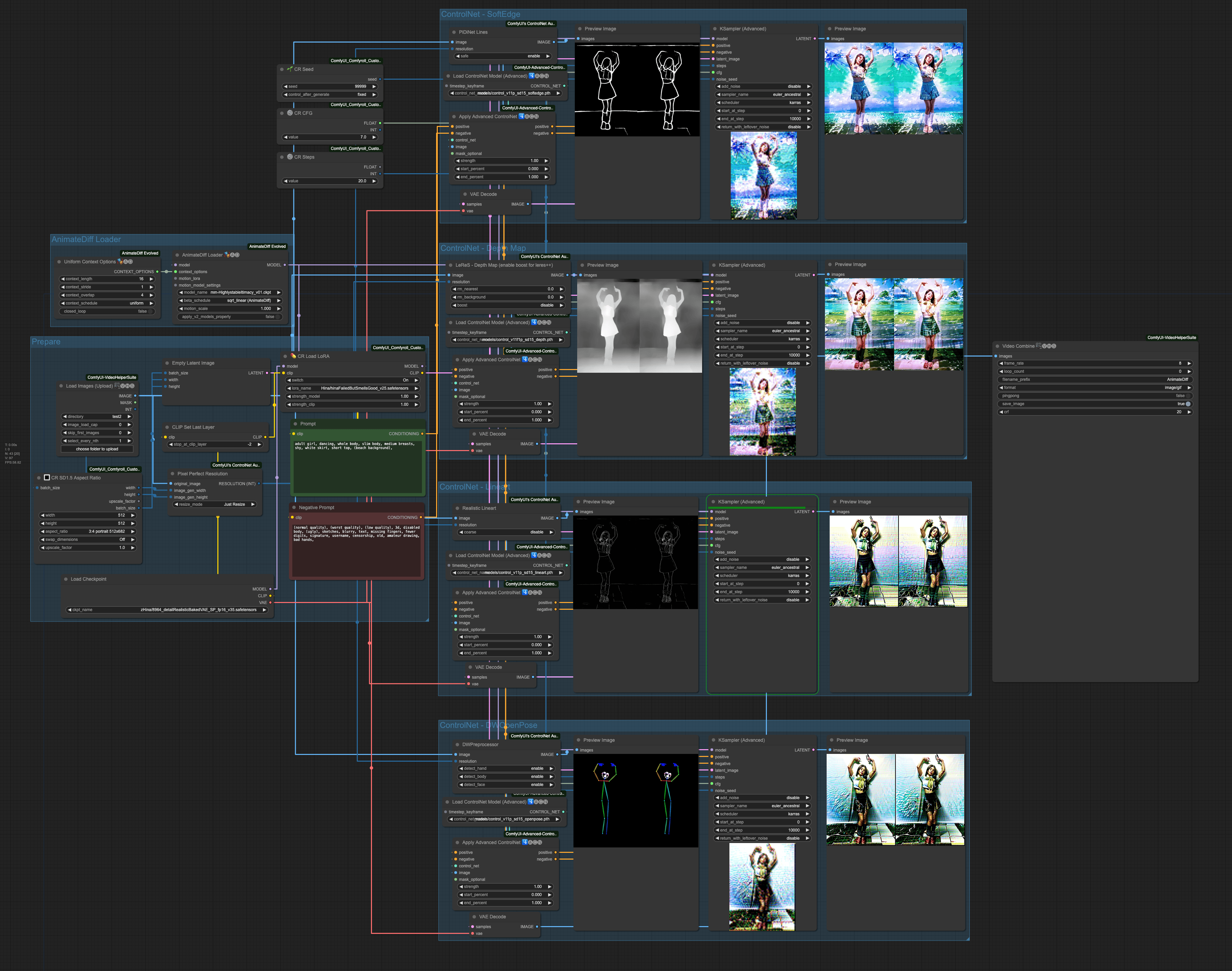
此次我們所使用的正向提詞為,
adult girl, dancing, whole body, slim body, medium breasts, shy, white skirt, short top, (beach background),
負面提詞為,
(normal quality), (worst quality), (low quality), 3d, disabled body, (ugly), sketches, blurry, text, missing fingers, fewer digits, signature, username, censorship, old, amateur drawing, bad hands,
這邊運作 ControlNet 的順序是,
- SoftEdge
- Depth
- Lineart
- OpenPose
每個 ControlNet 的處理結果都會往下個階段送,最後由 OpenPose 輸出成最終結果。我們可以獨立來看一下每次 ControlNet 處理的效果,
SoftEdge
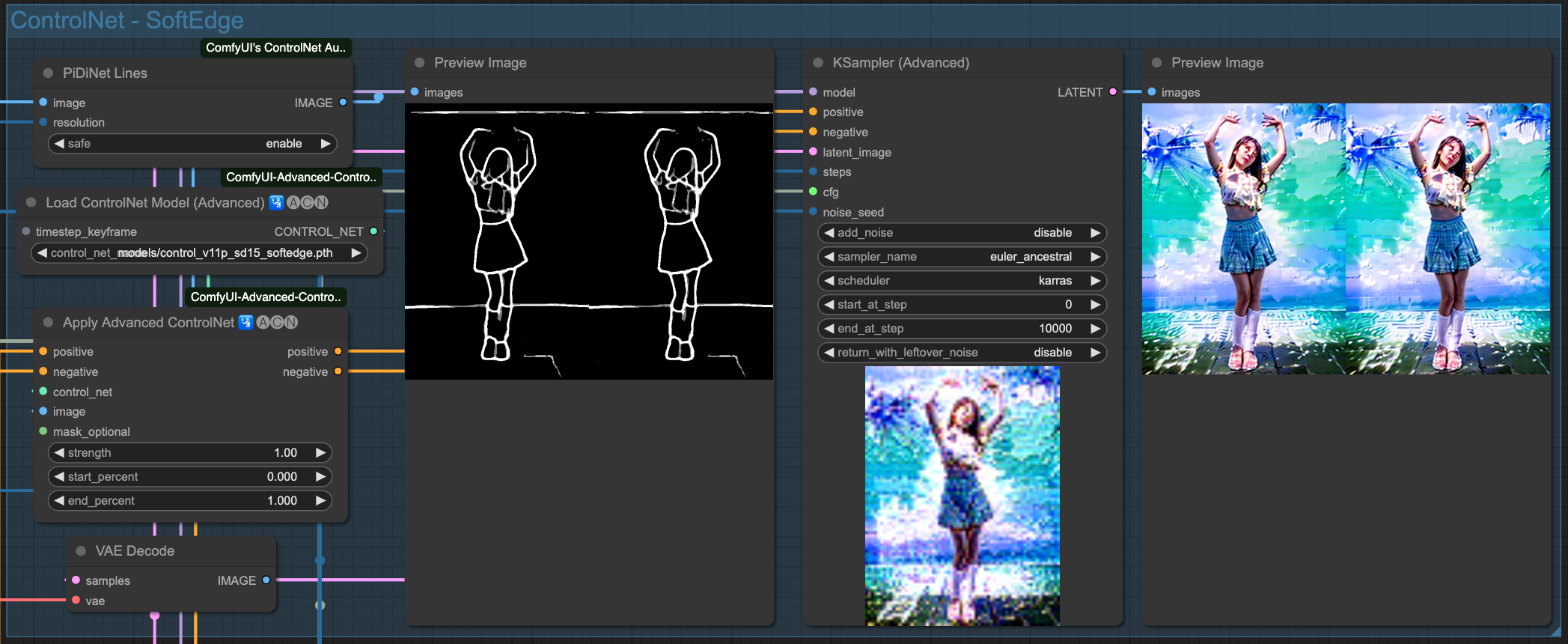
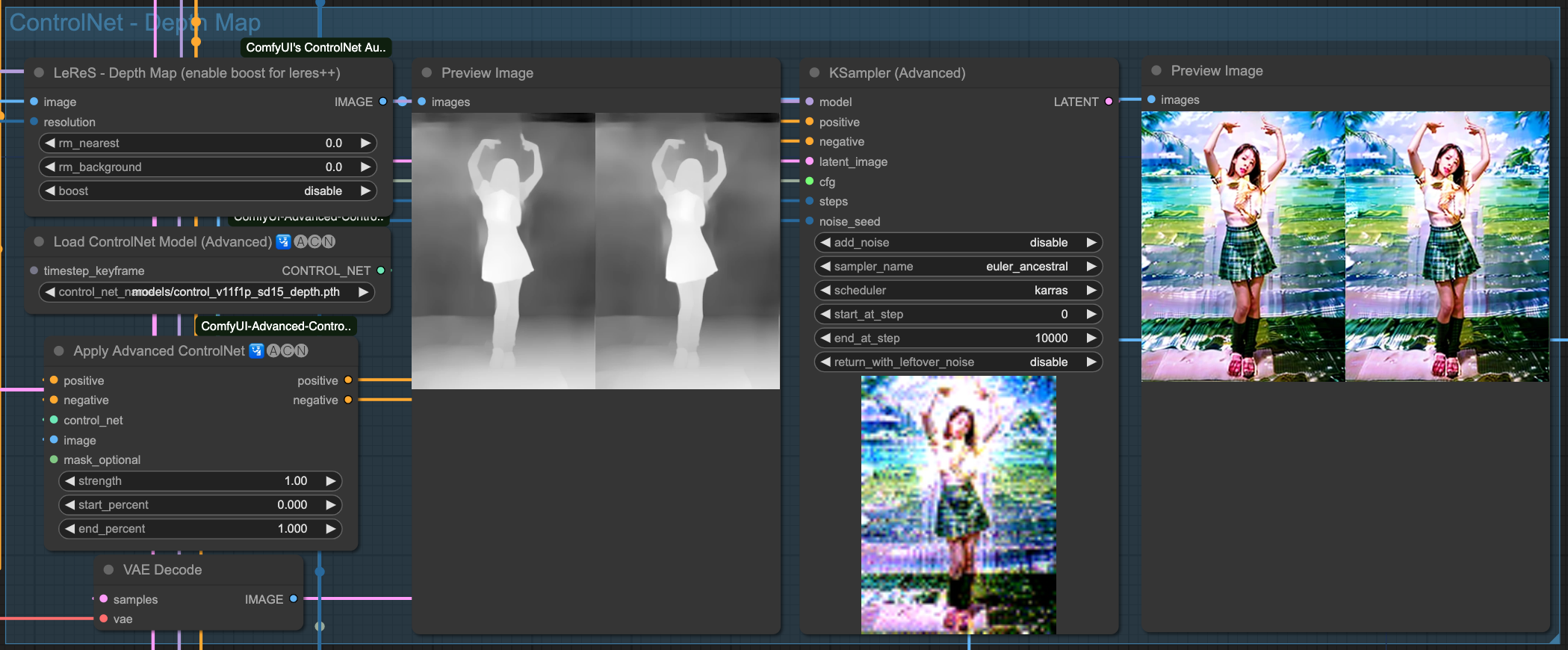
Depth
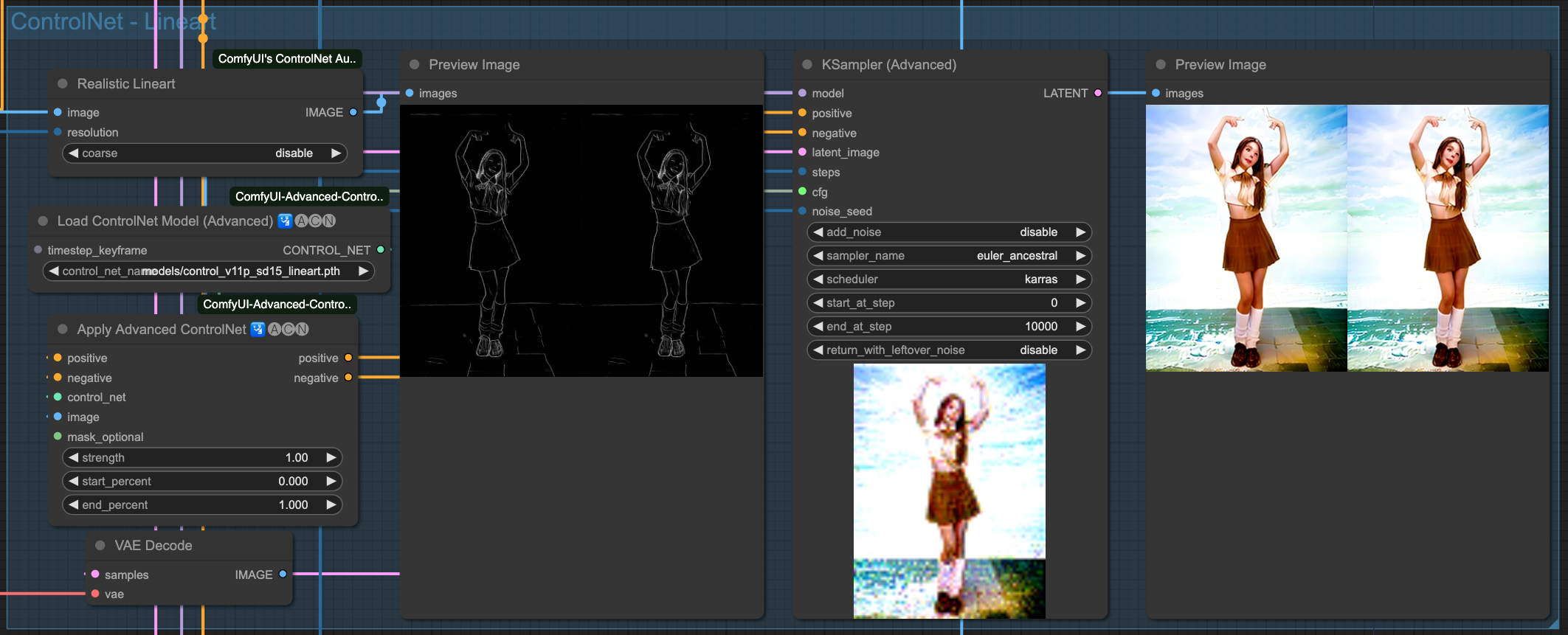
Lineart
OpenPose
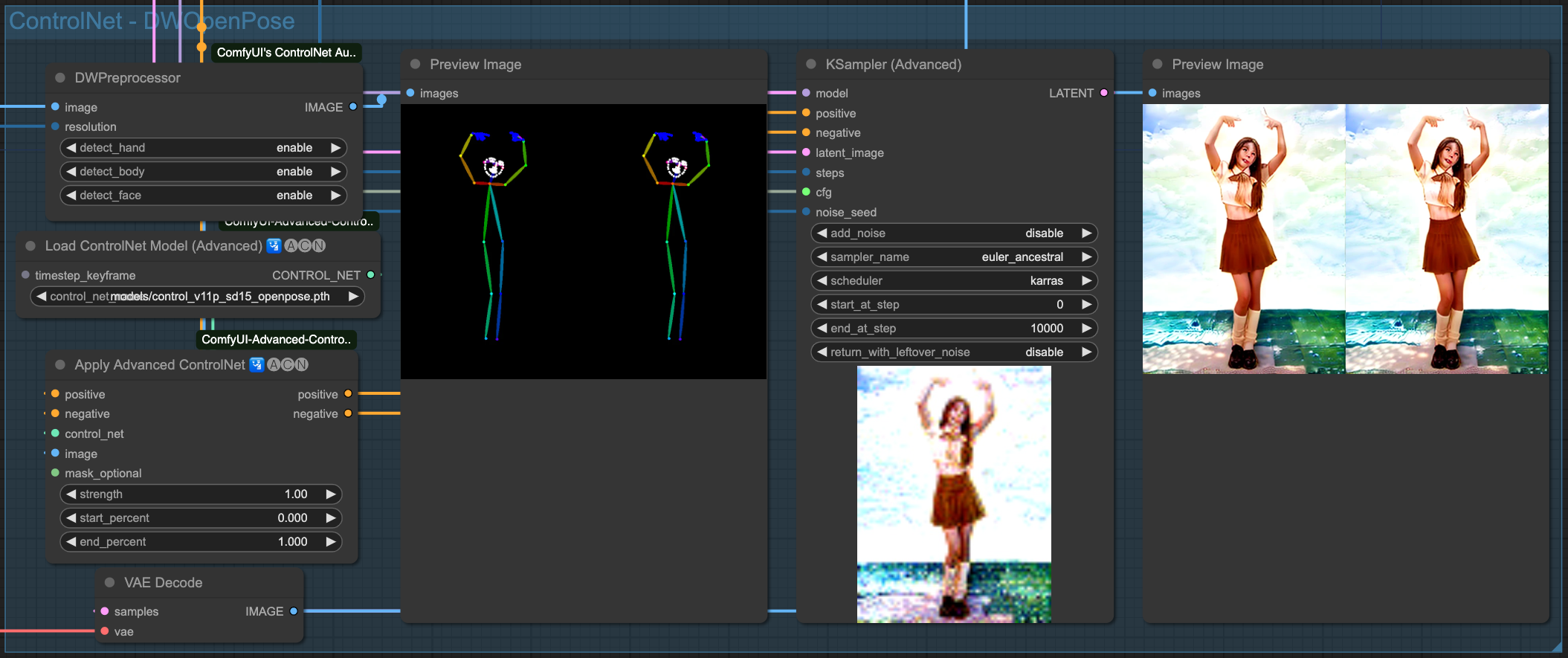
你會發現,雖然我們有強調 (beach background) 這件事情,但是由於來源影像的關係,所以他的繪製程度並沒有特別明顯,你可以回頭往上看還沒套用 AndimateDiff 動作模型的 ControlNet 產出結果來做比對。在整個流程中,對畫面的控制全部都由原始輸入圖檔,經過 ControlNet 來進行描述,最後再交給 Sampiler 去把畫面畫出來。所以,如果你變動 ControlNet 之間的關連順序,輸出的結果就會不同。
舉例來說,下面這四張圖片,是依照剛才的順序 反向 處理,然後在每一次的 ControlNet 都輸出給 Video Combine 元件輸出成動畫。
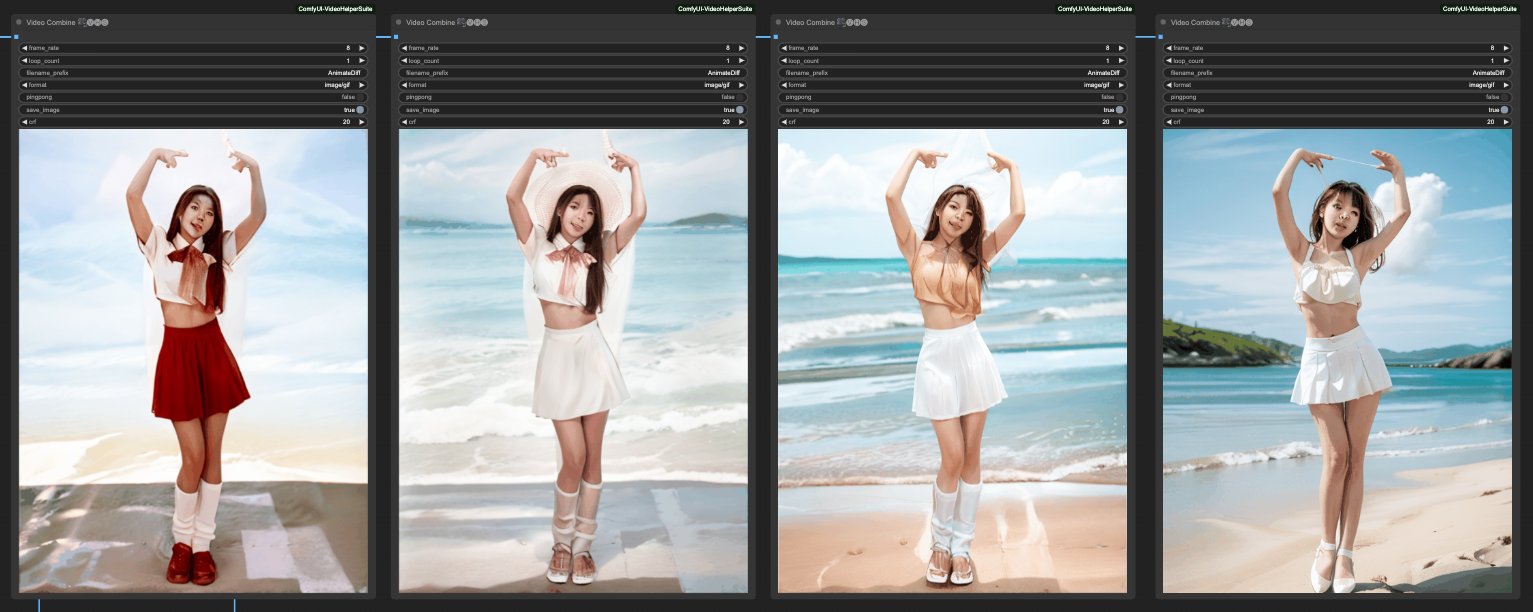
由左至右分別是,
- OpenPose -> Lineart -> Depth -> SofeEdge -> Video Combine
- OpenPose -> Lineart -> Depth -> Video Combine
- OpenPose -> Lineart -> Video Combine
- OpenPose -> Video Combine
乍看之下好像 OpenPose 就能處理得很好,但這也僅是這個例子剛好在 OpenPose 的狀況下比較好而已,實際上還是需要你自己去組合 ControlNet 來拿到比較好的結果。
後續處理
通常來說,我們做完一次 Samplier 之後,還會繼續處理幾件事情,
- 放大影片
- 臉部修復
- 二次重繪
這邊的作法沒有一定,組合的方式就看個人的習慣,並沒有固定形式,在我的 Github 上面有一個現成的作法,有興趣的人可以參考。
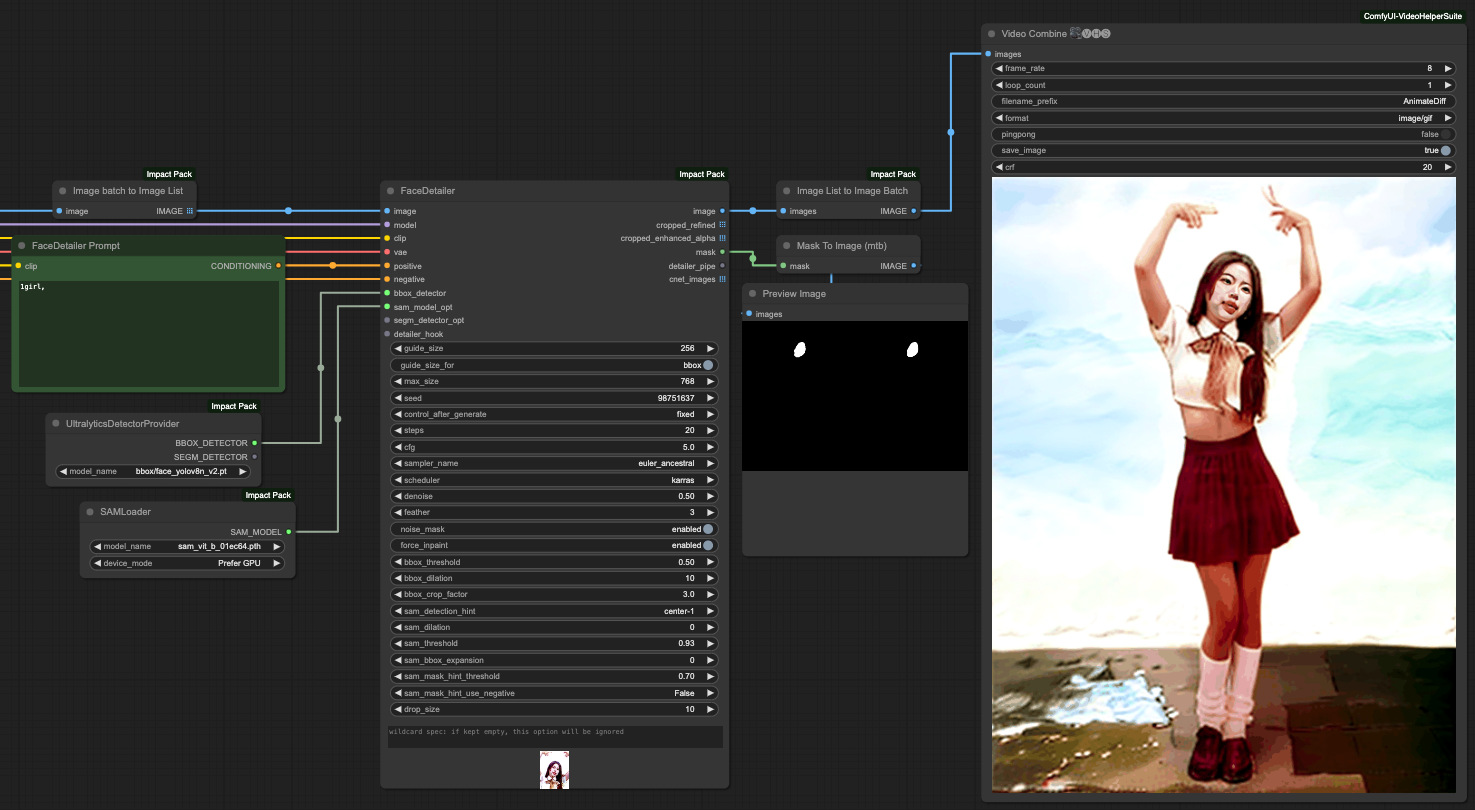
如果要做臉部修復,在這邊有一個要提醒大家的部分,從 VAE Decode 所輸出的 IMAGE 會是一個 Image Batch 的形式,需要轉換成 Image List 才能交給 FaceDetailer 的工具處理。同樣的,要把他從 Image List 轉換回 Image Batch ,才能交給 Video Combine 去儲存。
小結
AnimateDiff 雖然有其限制,不過透過 ComfyUI 可以組合出很多不同的作法。但,我老實說,轉換圖片如果要處理到很細緻,24 秒的影片可能得處理 2 個小時,其實算一算好像不合成本。最後,這邊提供本次文章所用到的 Workflow,有興趣的人可以自己慢慢研究,

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)