
![[Lora] 減法拆分融合 - 製作專屬特徵人物](/content/images/size/w960/2024/02/00125-2027187120.jpg)
說在最前面的,你需要先訓練出一個屬於你自己的人物的 Lora,畢竟拿別人的 Lora 來用可能會有版權的問題,所以盡可能的自己訓練一個會比較好。
關於減法的訓練我在 2023 年的 SD 年會中已經聊過,這邊就不贅述。
關於訓練的減法
2023 SD 年會 - 訓練的減法
如果沒有看過的人可以看一下,這篇文章會用到裡面說的一些方式。
事前準備
訓練的方式就不提了,總之就是準備一個你覺得訓練的不錯的一個人物的 Lora,然後選擇幾個你喜歡的模型。
- 準備好一個人物 Lora,或是多個(如果你有訓練多個的話)
- 基底模型,例如 9527 Detail Realistic XL
- 或是 SD1.5 基底模型,例如 Detail Asian Realistic
我這邊會以 SDXL 的模型來當範例,當然,操作的手法也可以用在 SD1.5 的模型與 Lora 上面,所以並不需要擔心。
另外,我們這邊需要用到 A1111 與這些外掛套件。
準備好了之後,我們就能開始做一些融合的測試工作。
Lora 的模型測試
首先,在開始測試 Lora 之前,請先挑一個你喜歡的基底模型,請注意,我們最終會將 Lora 融合到這個基底模型裡面,所以,你如果只有 1 個 Lora,那麼基底模型你可以多挑幾個。我這邊使用了 2 個 Lora 與一個基底模型做測試。
針對 Lora 的部分,我們每一個 Lora 可以先做一次最基本的 X/Y/Z plot,
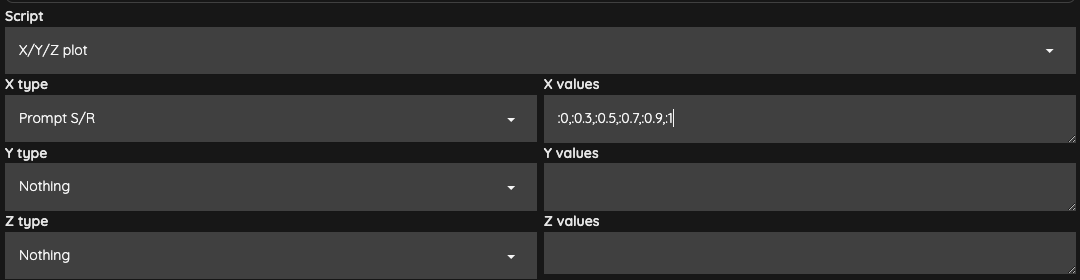
我們這邊就取 0, 0.3, 0.5, 0.7, 0.9, 1 這樣的權重去測試我們的 Lora 在基底模型上的效果。

這是單一個 Lora 的測試結果,我這次選擇了兩組 Lora,所以,我列出了兩組,並且對這兩組做一下交叉測試,看看兩組 Lora 互相疊加的時候的效果。

由於需要做交叉比對,所以設定上就變成這樣,
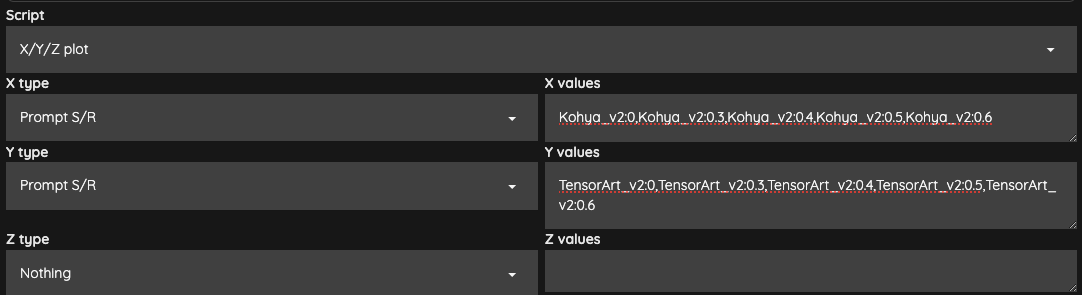

接下來,你可以直接選擇你覺得比較好的權重,來進行後續融合的動作。如果是兩個或以上的 Lora,那麼就挑選一個交叉測試後,你覺得相對順眼的權重即可。
進階的 Lora 分層測試
在融合之前,我們來提一下剛剛所說的 LoRA Block Weight 外掛的事情。上一個段落所測試的是單純的權重,而我們這邊可以使用這個外掛,來進行「分層」的測試,所要用到的是 Effective Block Analyzer 這個功能。
首先,你需要在你的提示詞(Prompt)中,修改 Lora 讀取的寫法,
<lora:你的 Lora 名稱:1:1:lbw=XYZ>
以上是在 A1111 1.5.0 之後需要這樣寫,如果你是之前的版本,請自行參閱 LoRA Block Weight 外掛說明。
Effective Block Analyzer
這個功能主要能夠讓你去比對指定的 Lora 分層,然後做出每一個分層權重所產生的差異變化。主要的設定有以下幾個,在介面上你可以去調整的。
diff image color差異化的顏色表示,有黑色跟白色可以選。change X-Y對調比對 X/Y 軸的呈現資料,通常會把他勾起來。difference threshold權重差異化的閾值,用預設20就可以了。Range比對權重差異,預設是0.5,1,表示你要比對的是0.5與1這兩個權重差異。Blocks (12ALL,17ALL,20ALL,26ALL also can be used)你想要比對哪些分層區塊,預設是全部,如果沒特別想法就不要動他也沒關係。number of seed比對次數(種子數),預設1,表示比對 1 次,他並不是產生圖片的種子,而是比對的次數,如果你寫20表示這個 XYZ Effective 會做20次。
請注意!這個比對的動作,他所計算的數量會是這個公式:
(number of seed) x (Blocks 數量) x (Range 數量)
所以預設會計算 1 x 26 x 2 總共 52 張圖片,然後再加上比對的時間。所以這個動作所需要的時間會比較長,以我本次的範例來說,我做完一次計算需要 10 分鐘左右。
使用 Script 裡面的 LoRA Block Weight
我不知道是不是我自己的問題,我僅能使用 Script 裡面的 LoRA Block Weight 才能啟用 XYZ 的功能。
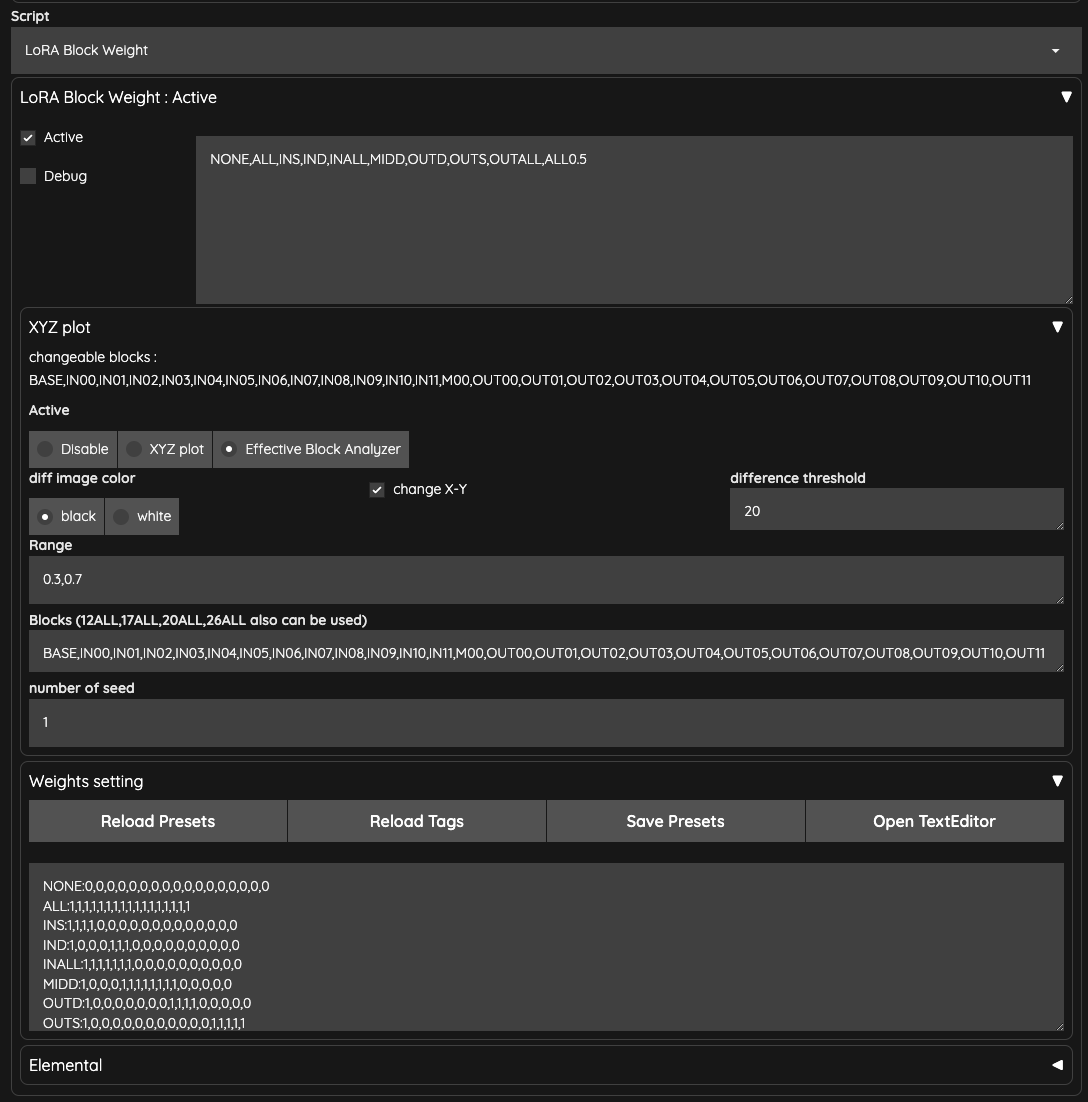
我這邊所使用的 Range 是使用 0.3,0.7,跟預設的不太一樣。之所以會這樣做的原因,在於我們先前已經測試了整個 Lora 的權重,然後我個人比較喜歡的權重區段大概是在 0.3 到 0.7 之間,所以我想知道的是 0.3 與 0.7 之間的區塊差異。
你們進行測試時,可以挑選自己喜歡的區段來做。
另外,如果你也是使用 SDXL 的模型跟 Lora,可以把 Blocks 改為 SDXL Lora 的 12 層,這樣可以加快產生的時間。
LoRA(17)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BASE | IN01 | IN02 | IN04 | IN05 | IN07 | IN08 | MID | OUT03 | OUT04 | OUT05 | OUT06 | OUT07 | OUT08 | OUT09 | OUT10 | OUT11 |
SDXL LoRA(12)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BASE | IN04 | IN05 | IN07 | IN08 | MID00 | OUT00 | OUT01 | OUT02 | OUT03 | OUT04 | OUT05 |

執行結束後,你會獲得一個差異比對的圖片,當中的 source 就是你設定的 Range 的第二個數字,我們這邊則就是 0.7,也就是 Lora 權重套用了 0.7 的結果,而 0.3 則代表 Lora 權重套用了 0.3 的結果。
diff 則表示了在這兩個權重上,畫面的差異用圖像化的方式呈現。而每一個層(Block)上面的百分比數值,則代表了兩個層之間的差異。所以現在我們會知道每一層的 Lora 對於這個模型,在 0.3 與 0.7 之間的差異,或是說「干擾」會是哪個部分。
這樣對於我們之後,若是想製作分層融合時,可以提供一定程度的參考。
融合 Lora 到基底模型
結束了分析之後,我們接下來要使用 Super Merge 來融合我們的 Lora 到模型裡面,去產生一個新的模型。
首先我們先前往 A1111 的 SuperMerge 分頁當中,然後我們需要做幾件事情,
- 在
Checkpoint ACheckpoint Tuned的地方填入你的基底模型路徑。 - 在
filename(option)填入你要儲存的模型路徑與名稱,例如merged_9527_with_lora_Kohya.safetensors,這樣融合完成後,會儲存在 A1111 預設放置 checkpoint 的地方。 - 在
settings的地方,兩個項目都打勾。same to Strength依照原始Strength儲存,勾起來比較不會出錯。overwrite是否要覆寫已經存在的檔案,請先確認一下是否有一樣的檔名存在,若有,請改一下filename(option)的名字。
metadata的部分選擇create new即可。save precision選擇fp16。calc precision(fp16:cuda only)選擇float即可。device選擇cuda,如果有問題,可以選cpu也沒關係。remake dimension選擇no,不要改寫任何 DIM。LoRAname1:ratio1:Blocks1,LoRAname2:ratio2:Blocks2,...(":blocks" is option, not necessary)填入你的 Lora 與權重,如果你要使用分層,則有另外的填寫方式。- 最後,按下
Merge to Checkpoint等他融合完成即可。
融合結束後,你就會獲得一個全新的模型(例如 merged_9527_with_lora_Kohya.safetensors),接著就能用這個模型來產生圖片(此時就不需要再套用任何的 Lora)。
分層融合 Lora 到基底模型
如果要使用分層融合,那麼你需要先將分層資訊放到底下的文字框中,例如:
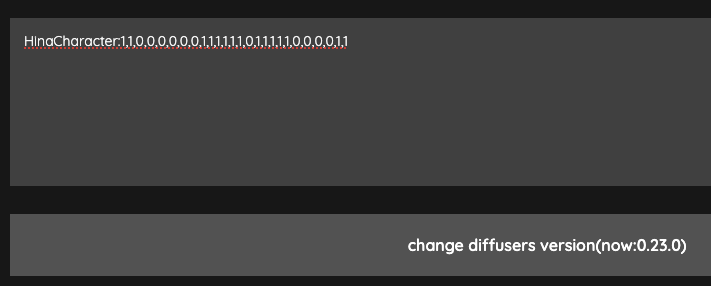
這邊的撰寫方式是,
BlockName:block weights
如果以我們剛剛測試的結果,以我的例子來說,SDXL 總共分了 12 層,我想要每一層給不同的權重,那麼我就可以這樣寫,
HinaBlock:1,0,0,0.3,0.5,1,0.3,0.3,1,1,1,1
接著,在我們剛剛的 LoRAname1:ratio1:Blocks1,LoRAname2:ratio2:Blocks2,...(":blocks" is option, not necessary) 填入以下的字串,
Hina_Lora_Kohya:HinaBlock
這樣在融合時,就會採用分層融合的方式。以上無論是單一權重融合,或是分層融合,在融合到模型,或是多個 Lora 融合成一個全新的 Lora,使用方式都是相同的。
融合模型的減法
融合完成後,你就會獲得一個已經融合了你的 Lora 的新模型,這個時候,我們可以使用 Kohya GUI 所提供的提取 Lora 的工具,來將融合過的結果給提取出來,變成一個全新的 Lora。
這也是我在 SD 年會中所提過的一個方式,
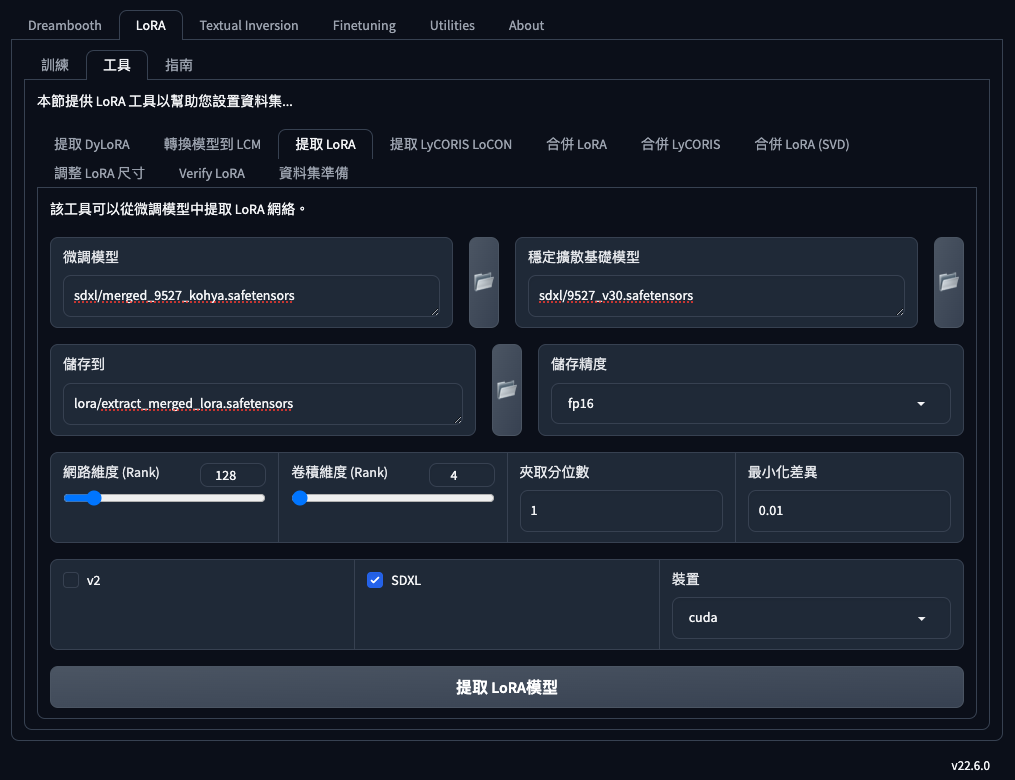
這個作法需要注意的地方,
- 微調模型(Finetuned model)需要選擇你已經融合的模型。
- 穩定擴散基礎模型(Stable Diffusion base model),需要選擇當初把 Lora 融合進去的基底模型。
- 網路維度 Rank(Network Dimension (Rank))的數字沒有一定,你可以從
32,64,128之間去測試提取出來的 Lora 效果。 - 儲存精度(
Save precision)可以選fp16。 - 其餘的數值可以維持預設。
- 如果你是使用 SDXL 或 v2 的模型,記得要打勾。
這樣的提取動作,我來稍微解釋一下會發生什麼事情,
Lora A + 基底模型 A = 融合基底模型 A'
融合基底模型 A' - 基底模型 A = 融合 Lora A'
提取出來的 融合 Lora A' 會帶有融合了 基底模型 A 特徵的一個特殊型 Lora,由於融合了 基底模型 A 的特徵,所以他會與當初的 Lora A 有些微的不同。
我們可以利用這種融合後提取出來,所造成的些微的差異,再次回到 A1111 去測試這個新的 融合 Lora A',然後,這個時候我們置換掉 基底模型 A,改用 基底模型 B 來進行測試。
這樣測試後,你就會獲得 融合 Lora A' 與 基底模型 B 的相關數值,再次進行融合。
融合 Lora A' + 基底模型 B = 融合 基底模型 B'
此時的 融合 基底模型 B' 就會帶有 融合 Lora A' 的融合特徵,這個時候,我們再做一次減法,這個時候我們很單純的使用 A1111 所提供的 Checkpoint Merger 功能,
融合基底模型 B' - (基底模型 B - 基底模型 A) * M = 融合基底模型 B''
Primary model (A)選擇融合基底模型 B'。Secondary model (B)選擇基底模型 B。Tertiary model (C)選擇基底模型 A。Custom Name (Optional)填寫一個你喜歡的模型名稱。Multiplier (M) - set to 0 to get model A可以使用0.7。Interpolation Method選擇Add difference。Checkpoint format選擇safetensors。Save as fp16打勾。Copy config from選擇A, B or C。Bake in VAE維持None。
這樣,你會獲得一個 融合基底模型 B' 加上 (基底模型 B - 基底模型 A) 差異化後乘上某個倍率的 融合基底模型 B-B-A。
請注意!如果
基底模型 B與基底模型 A差異甚大,相減後可能不如預期。並不是任何的模型都能做這樣的「相減」的動作,請自行留意。
最後,你可以將 融合基底模型 B-B-A 再次使用提取 Lora 取出特殊 Lora 來使用,或者是直接使用這個 融合基底模型 B-B-A 來當作你的模型。
結語
依照上述的流程,可以不斷重複直到你覺得拆出來的 Lora 或是融合出來的模型,是符合你的需求的。這樣可以不斷調整同一個 Lora 直到你覺得滿意為止。
以下是這次實驗的 SDXL 的特製模型,所產生出來的結果,這樣的模型,人臉都會固定式同一個人,除非特別針對五官做特殊描述,不然基本上不會有太大的變化。


![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)