
![[TensorArt] Lora 訓練筆記](/content/images/size/w960/2024/01/20240115_feature_image.jpg)
對於硬體需求比較高的訓練,利用第三方平台算是一個不錯的選擇。當然,若你是有一些工程背景知識,使用 Colab 或是 Runpod 也是一個選項。但倘若是訓練入門的人,使用 TensorArt 所提供的工具也是不錯。
TensorArt
TensorArt 是一個線上產圖的平台,跟 Civitai 是類似的。前些日子他們推出了訓練工具,所以,我們現在可以在 TensorArt 上面訓練我們自己的 Lora 模型。
如果你沒有註冊過帳號的話,先去註冊一個帳號再來看看如何使用訓練方式吧。
TensorArt 訓練介面說明
首先我們先熟悉一下介面,在登入後右上角選單中,會有一個 Training 的選項,
進入之後,會看到一個空的訓練清單,這個時候我們點一下 Online Training 就會進入訓練設定。
進入訓練設定後,分成兩個區域,一個是放置你的訓練資料集的地方,另一個則是關於訓練方面的設定。
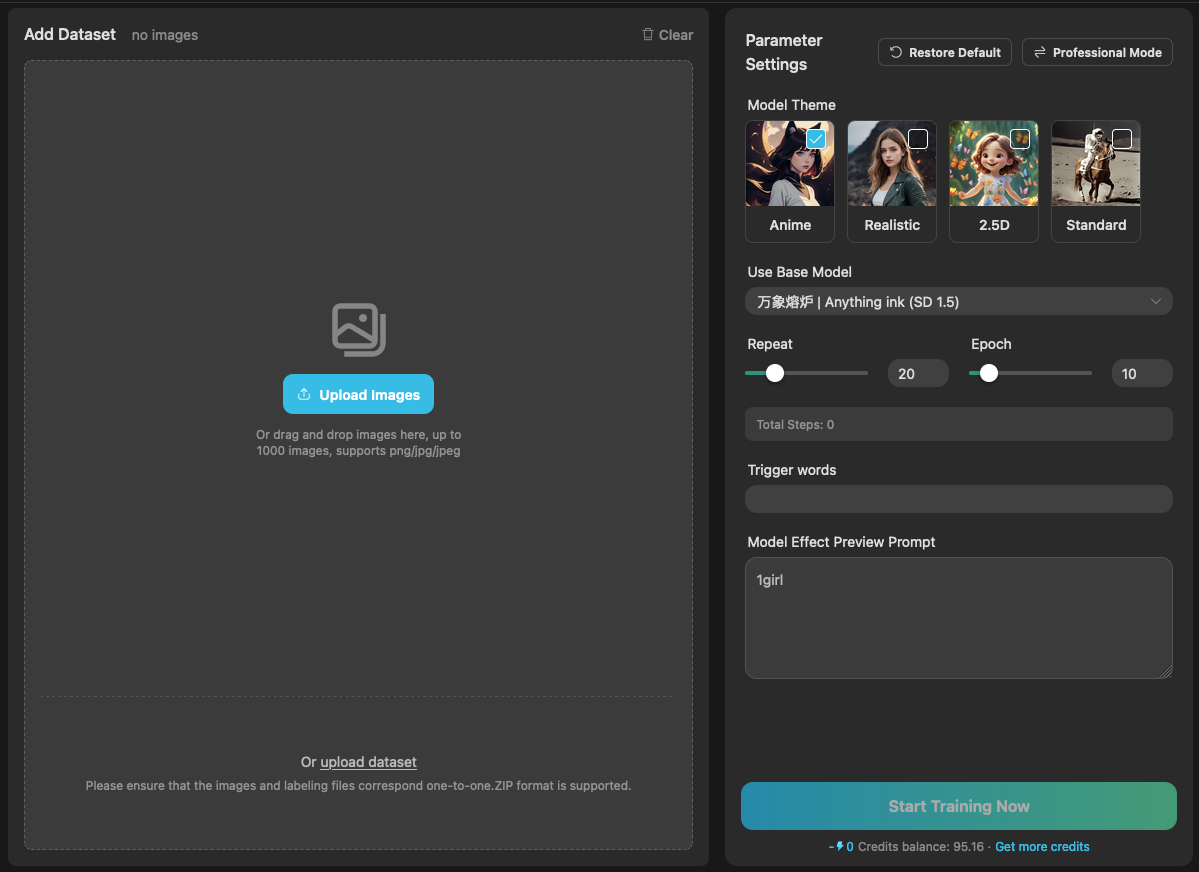
左邊就是上傳資料集的部分,我們這邊暫時先跳過,我後面會再補充說明。右邊則是訓練參數設定,跟常用的 Kohya-ss 比起來,他的設定參數就少了很多。
在介面的右上角,有一個 Professional Mode 可以切換,上面圖片所顯示的是 Basic Mode 也就是基礎模式。
在基礎模式的狀態下,我們有幾件事情可以做,
- 選擇訓練的基礎模型。
- 設定 Repeat 與 Epoch 數量。
- 設定這個 Lora 模型的觸發詞(Trigger words)。
- 設定模型訓練時,用來產出範例圖片的提示詞(Preview Prompt)。
全部設定好之後就能開始訓練,夠簡單吧!
進階模式 Professional Mode
如果你切換到進階模式(Professional Mode),那麼你可以設定的東西會多很多。
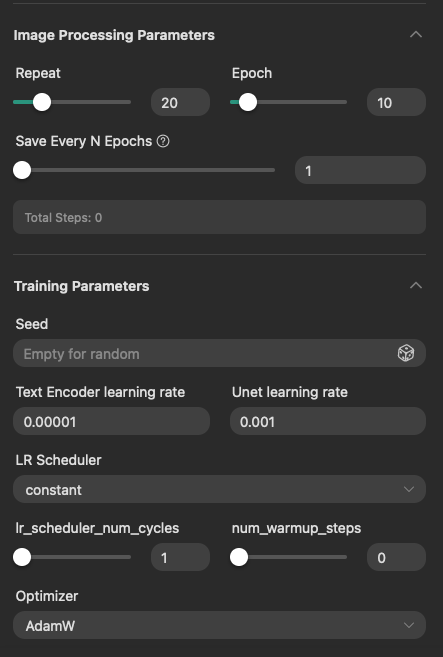
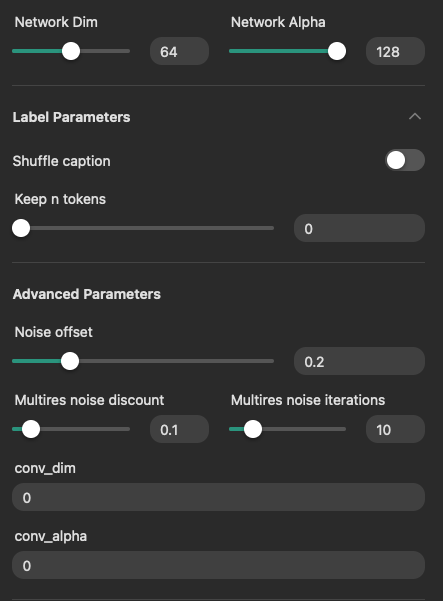
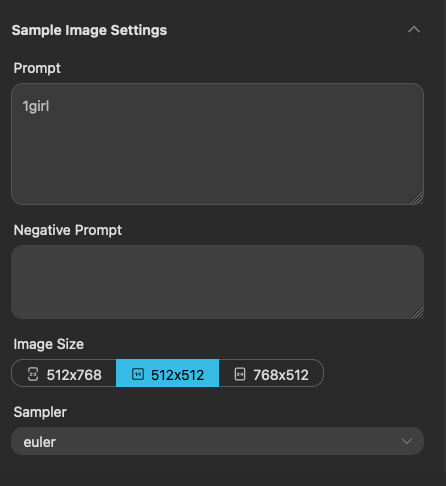
在進階模式下,你可以設定的項目有,
- 選擇模型與設定觸發詞的部分,與基本模式相同。
- 設定 Repeat 與 Epoch 數量,並且設定多少個 Epoch 要儲存一次訓練結果模型。
- 設定採樣種子(這個種子說明請參考我 之前的文章)。
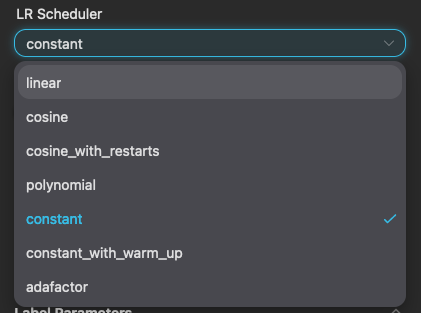
- 設定 Text Encoder 學習率,UNet 學習率與學習率排程(LR Scheduler)。
- 設定排程重起次數與預熱步數。
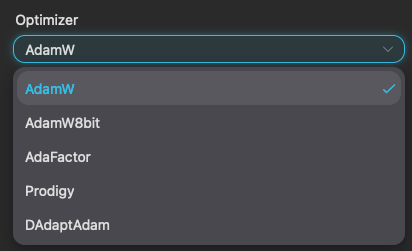
- 設定優化器(_Optimizer)。
- 設定 DIM(Rank) 與 Alpha。
- 可以決定是否開啟打亂標籤(Shuffle caption)。
- 可以設定保持幾個標籤不被打亂(Keep n tokens)。
- 設定噪聲偏移(Noise offset),或多重噪聲偏移參數(Multries noise)。
- 設定卷積(Conv)的 DIM(Rank) 與 Alpha。
- 設定模型訓練時,用來產出範例圖片的提示詞(Prompt)與負面提示詞(Negative Prompt)。
- 選擇產出範例圖片的圖片尺寸與採樣(Sampler)方式。
根據之前測試的結果,目前可以確定優化器的部分,僅有 AdamW 與 AdamW8bit 會比較順利,其他的優化器我全部都跑過一次,全部都失敗收場(笑)。
至於學習率排程(LR Scheduler)的選擇,基本上跟學習率、優化器方式比較相關。如果你不確定的話,可以先用常用的 constant 來做訓練。
如果你真的不理解上面那些設定,你先試試看基本模式就好了。或者,你可以去看看我之前所寫的關於 Kohya_ss GUI 的介紹文章。
資料集的準備
要訓練總是要準備資料集,在 TensorArt 的訓練介面上,他允許你直接上傳圖片,或是上傳一個壓縮檔(zip)。
在直接上傳圖片的部分,由於是直接上傳,所以他會自動幫你把圖片的標籤做好。
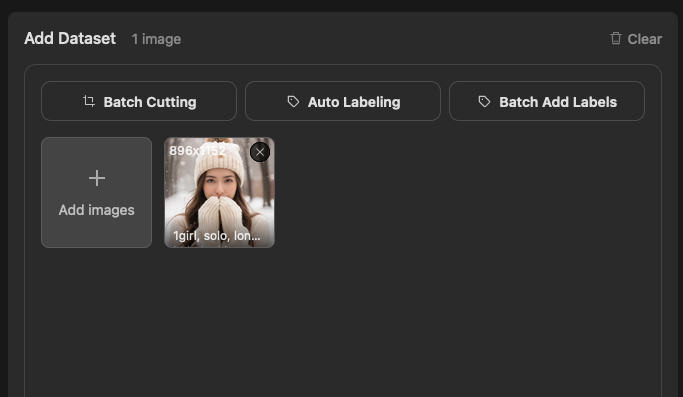
你的圖片上傳後,他就會自動幫圖片下好標籤,你可以點擊那張圖片來查看他加入了哪些標籤。另,圖片打開後,如果你發現會破圖(圖片無法顯示),這個時候你重新整理一下瀏覽器應該就會正常。
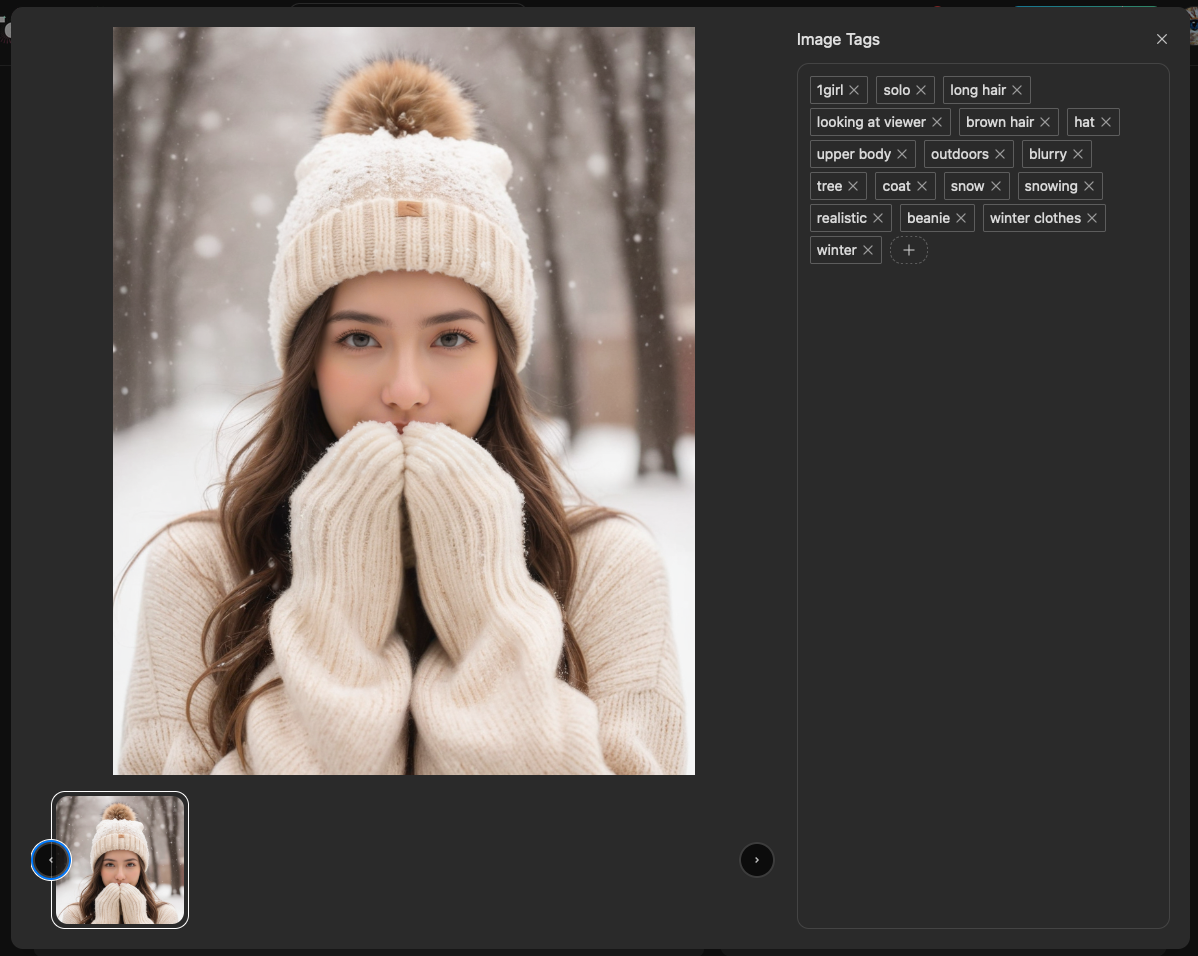
打開後你可以在這邊編輯這張圖片的標籤,看你是要刪除,或是要新增都可以。
上傳壓縮檔案
一張一張上傳實在太慢,那麼你可以把圖片壓縮後上傳,建議的作法如下:
- 利用流水號編排圖片檔案名稱,例如
img_0001.png,img_0002.png依此類推。 - 如果有標記檔案,請跟圖片檔名對齊,例如
img_0001.txt,img_0002.txt依此類推。
將上述檔案打包成一個壓縮檔案(zip),請勿包含任何資料夾,把壓縮檔案上傳上去即可。
回到圖片清單介面上,你還有三個功能可以使用。
- 批次裁切圖片(_Batch Cutting)。
- 自動標籤(Auto Labeling)。
- 批次加入標籤(Batch Add Labes)。
批次裁切圖片(_Batch Cutting)
在批次裁切圖片的功能裡,你可以針對訓練模型的版本(SD 1.5 或 SDXL)來選擇裁切的尺寸。
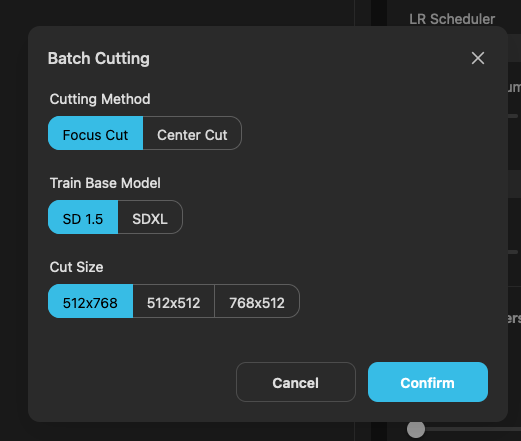
其中裁切模式(Cutting Method)有兩種可以選擇,官方並沒有特別說明兩者的差異,但依據常見訓練方式的裁切方法來看,個人猜測可能是這樣的裁切方式:
- Focus Cut 針對臉部做裁切。
- Center Cut 直接由圖片中央裁切。
確定之後他就會依據你設定好的尺寸來裁切你的圖片。
自動標籤(Auto Labeling)
在自動標籤的功能中,你可以選擇哪一種語言演算法來標籤你的圖片。
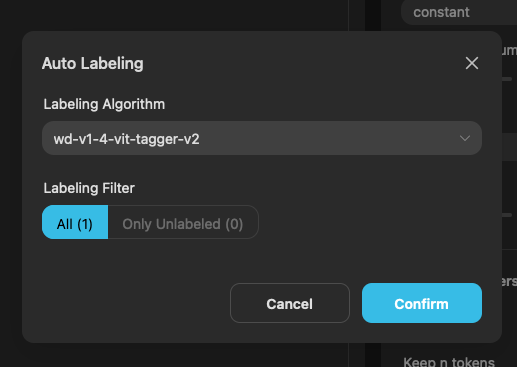
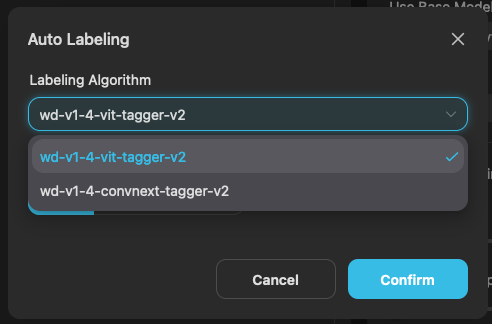
底下的標籤過濾基本上沒有什麼功用,除非你上傳的是壓縮檔,檔案內沒有附帶標籤文件的話,這邊就能選擇要自動標籤的對象是誰。
批次加入標籤(Batch Add Labes)
最後一個是可以針對圖片作批次加入標籤的功能。
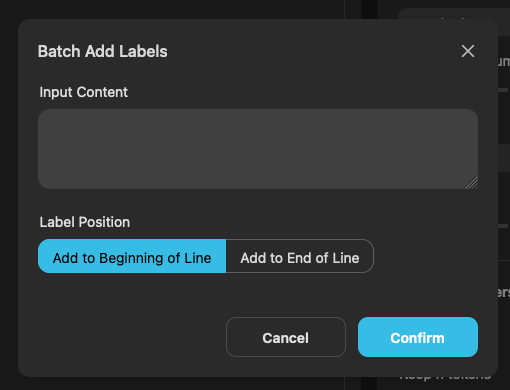
你可以輸入你想要加入的標籤,並選擇要加在開頭(Beginning of Line)還是結尾(End of Line)。
請注意!在這邊不要輸入你的觸發詞(Trigger word),觸發詞在這個訓練器當中,會自動加在所有訓練提示詞的最前面。
開始訓練
請留意 TensorArt 會依照你的訓練集、訓練參數設定,而有不同的點數(Credits)需求。
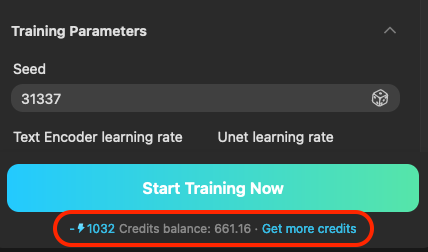
如果你的點數(Credits)不夠的話,可能會需要額外購買。一切的數據都設定好之後,就可以開始跑訓練了。
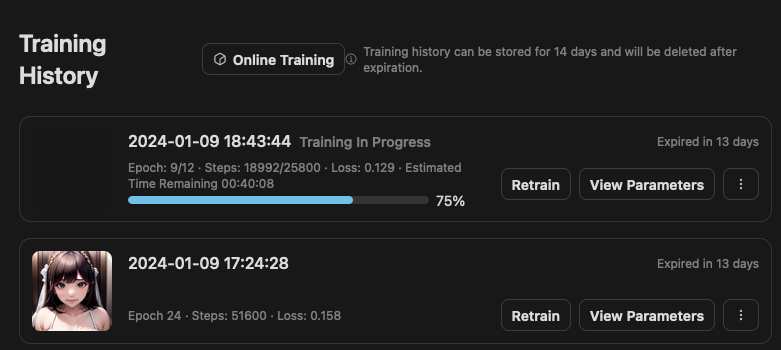
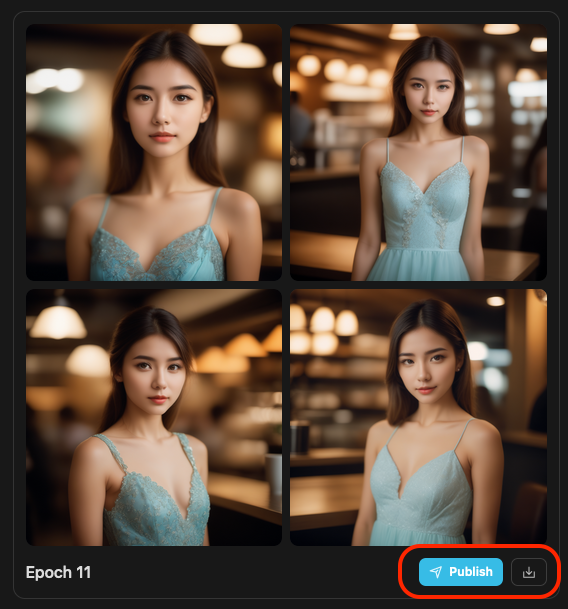
當你訓練完成後,你就能點進去看看訓練的結果。由於我當初使用的是進階模式,所以會儲存每次 Epoch 的結果,而這四張圖片就是當初所設定的範例圖片提示詞,所產出的結果。
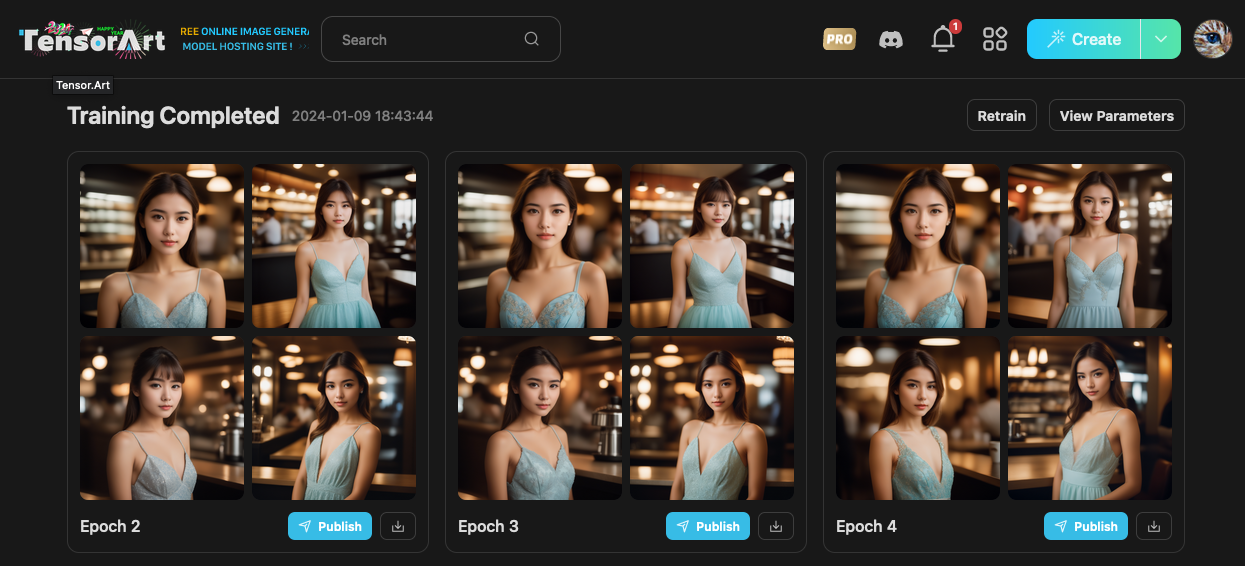
你可以挑選你覺得結果比較好的 Epoch 的模型來下載使用。
請注意!在我測試的期間,TensorArt 官方表示,僅會儲存 10 個 Epoch 結果,而我此次的測試 Epochs 是 12 個,所以最終只會儲存 3~12 個 Epoch 而已。
上面的圖片從 2 開始,是官方的 Bug,因為他幫我儲存了 2~11,並不是 3~12,已經回報給 TensorArt 官方,後續他們會修復這個問題。
訓練失敗?
跑訓練總是會失敗的,
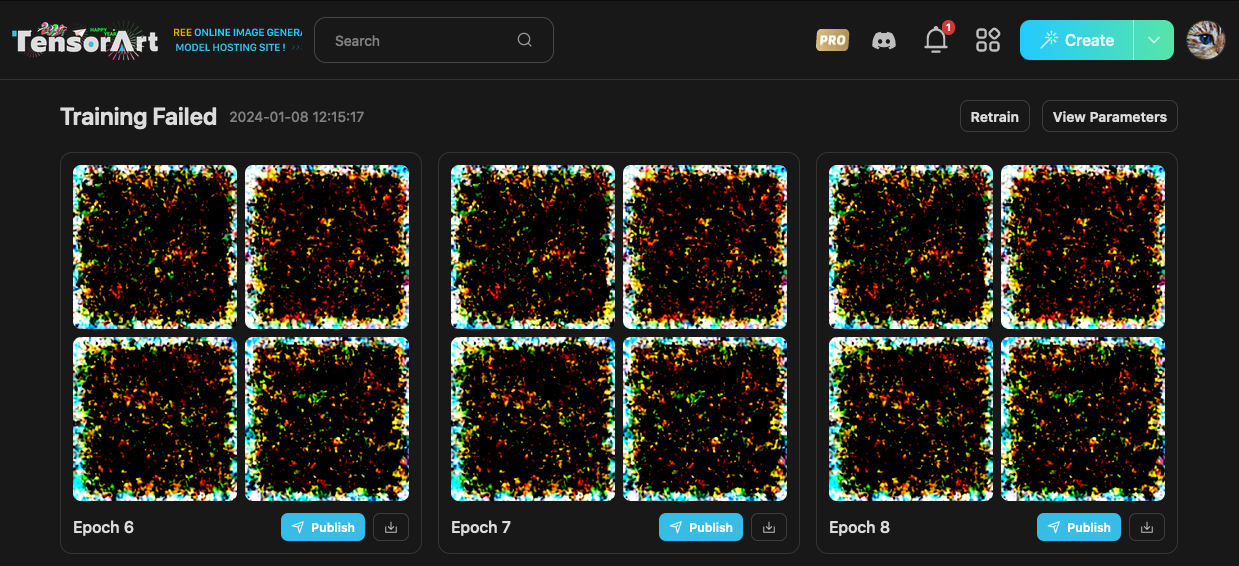
失敗的部分我就不多說了,大抵上就是超參數錯誤之類的,詳細的資訊你也無法得知就是。
重新訓練
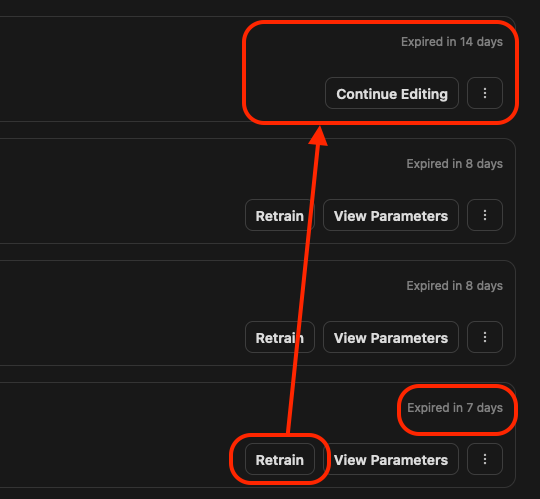
在訓練記錄的清單中,可以利用 Retrain 按鈕來重新訓練相同的資料集。
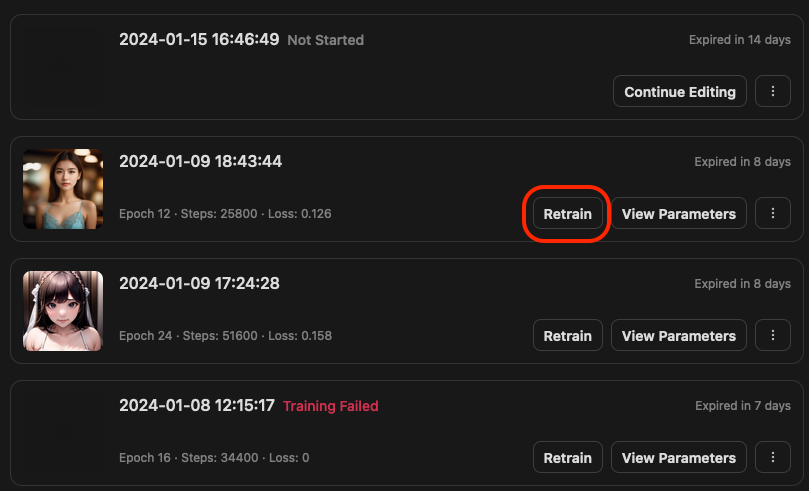
當你點擊 Retrain 的時候,如果你當初的資料集很多,就稍等他一下,他會把所有的資料都讀取進來。接著你就重複設定,或是增加、刪減你的資料集圖片,然後進行重新訓練。
介面上的 View Parameters 則是可以察看該次訓練的參數,
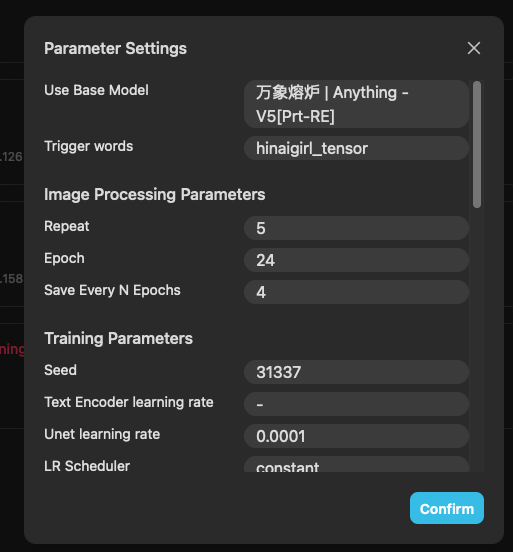
訓練完成之後
你的訓練記錄會保留 15 天,如果你想要繼續保留,那麼你就按一下 Retrain 讓他複製一份新的出來。
當你挑選好你覺得不錯的訓練結果(通常會是最後一個),你可以選擇發佈到 TensorArt 上面,或是下載他。
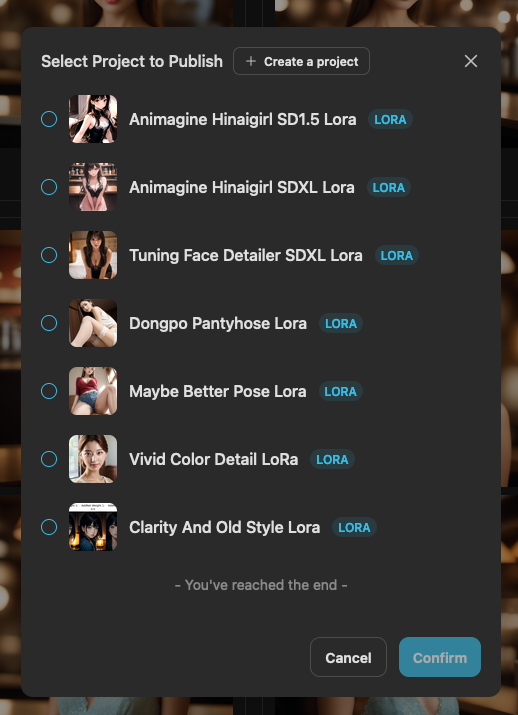
當你選擇發佈時,如果你已經發佈過其他的 Lora 專案,他會要你選擇你想要發佈到哪一個專案下,或者是,你可以選擇建立一個全新的專案(Create a project)。
結語
其實 TensorArt 這樣的工具算是相當方便,對於手邊沒有足夠的硬體資源的人來說,想要訓練一些小的模型來練練手感,又不想要設定那些複雜的超參數,這確實是一個入門的好工具。
最後,希望官方能把 Prodigy 優化器修好,畢竟這個東西在本地端要跑起來難度很高啊(笑)。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)