
![[Kohya_ss] 分層訓練與參數筆記](/content/images/size/w960/2023/06/00188-b47a69fc.jpg)
說在最前面的,這個分層訓練僅是針對分層的概念作的實驗,若想瞭解更多關於分層的設定,可以參考 b 站或是其他學習資源。這裡僅記錄過程,每個分層的設定都必須自己慢慢實驗才知道怎樣才合適。
Kohya_ss 的分層訓練
我這裡所使用的 Kohya_ss 版本是 v21.7.7,所以若你想要參考這篇文章使用分層訓練,請先確認你的版本是否為 v21.7.7。
分層權重
分層的概念是從 SD WebUI Lora Block Weight 來的,主要的目的是可以針對 Lora/LoCon 來指定層的權重,用以降低過擬合,或是減少 Lora 之間的互相干擾問題。
關於分層權重的部分,可以參考這一位大佬的文章:
WebUIのLoRA Block Weight拡張で、LoRAの適用具合を調整するチュートリアルを公開しました。
— Zuntan (@Zuntan03) April 11, 2023
12枚の画像で学習した「ゴブ姫LoRA」の各階層に重みを適用します。
調整を手助けするツールも紹介しています。
おまけには「階層別学習率」や「重みづけプロンプト」も。https://t.co/XkqEwNrsbM pic.twitter.com/KCtTMXhTmn
他做了一個分層計算機,並分享到 https://github.com/Zuntan03/LoraBlockWeightPlotHelper 上面,有興趣的人強烈推薦閱讀。
關於分層權重的設定,可以參考這裡:Weights Setting。每一個層(Block)會發生什麼作用,請自行參考上個區段分層權重的資料。或者你可參考 Effective Block Analyzer 的作法,自行使用 X/Y/Z plot,去找出比較適合的參數來使用。
Kohya_ss 的分層訓練
目前在 Kohya_ss 上面,僅有 Standard (Lora), Kohya LoCon 及 Kohya DyLoRa 支援分層訓練。
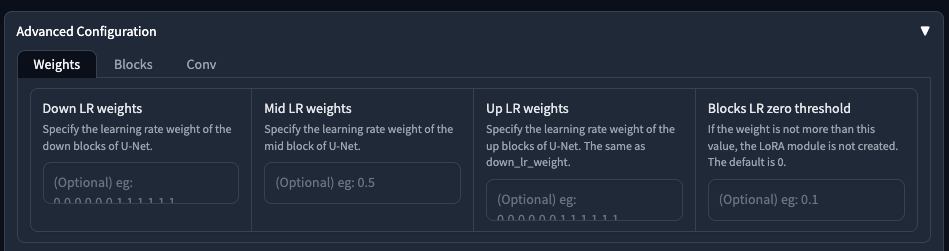
分層訓練區分為,
Down LR Weights淺層至深層。Mid LR Weights中間層。Up LR Weights深層至淺層。
預設是都不設定,就是全訓練,也就是每一層的參數都會是 1 的情況下去做訓練。
另外 Blocks LR zero threshold 請不要亂寫,他的意思是訓練權重若沒有大於此設定,則會捨棄該 Lora 的訓練建立,換句話說,你若是設定的數值,你訓練出來的 Lora 等於沒有訓練。
請注意,這個欄位所謂的 weight 是指跟學習率相乘後的結果,並不是前面幾個欄位的設定值,所以,當你的學習率是 0.0001 的話,這邊的數字如果寫 0.0001,其實也等於沒有訓練,因為全面的預設全訓練是 1,乘上學習率之後還是 0.0001,並沒有比 Blocks LR zero threshold 來得大,所以訓練會被捨棄。
保持 Blocks LR zero threshold 為 0 是個明智的選擇。
分層訓練設定
根據 Kohya-ss #PR355 的說法,每個分層學習率都需要填寫 12 組數字,這是 LoCon 的最大數字(共 25 + 1 層)。所以當你在分層訓練 Lora/LoCon 時,請留意你的分層數字是否設定正確。關於分層權重的區塊,可以參考這裡:Weights Setting。
在分層設定中,除了填寫 12 個數字之外,從 Kohya_ss 的原始碼中,還有幾個特殊參數可以使用,
# 層別学習率用に層ごとの学習率に対する倍率を定義する、外部から呼び出される可能性を考慮しておく
def get_block_lr_weight(
down_lr_weight, mid_lr_weight, up_lr_weight, zero_threshold
) -> Tuple[List[float], List[float], List[float]]:
# パラメータ未指定時は何もせず、今までと同じ動作とする
if up_lr_weight is None and mid_lr_weight is None and down_lr_weight is None:
return None, None, None
max_len = LoRANetwork.NUM_OF_BLOCKS # フルモデル相当でのup,downの層の数
def get_list(name_with_suffix) -> List[float]:
import math
tokens = name_with_suffix.split("+")
name = tokens[0]
base_lr = float(tokens[1]) if len(tokens) > 1 else 0.0
if name == "cosine":
return [math.sin(math.pi * (i / (max_len - 1)) / 2) + base_lr for i in reversed(range(max_len))]
elif name == "sine":
return [math.sin(math.pi * (i / (max_len - 1)) / 2) + base_lr for i in range(max_len)]
elif name == "linear":
return [i / (max_len - 1) + base_lr for i in range(max_len)]
elif name == "reverse_linear":
return [i / (max_len - 1) + base_lr for i in reversed(range(max_len))]
elif name == "zeros":
return [0.0 + base_lr] * max_len
else:
print(
"Unknown lr_weight argument %s is used. Valid arguments: / 不明なlr_weightの引数 %s が使われました。有効な引数:\n\tcosine, sine, linear, reverse_linear, zeros"
% (name)
)
return None
所以 Down/Up LR Weights 可以設定,
cosine使用餘弦函數。sine使用正弦函數。linear使用線性函數。reverse_linear使用線性函數(反向)。zeros使用常數0.0加上指定數字base_lr。
所以,如果我在 Down LR Weights 設定為 sine+0.25,那麼最終你會獲得這樣的數字,
down_lr_weight (shallower -> deeper, 浅い層->深い層): [0.25, 0.39231483827328517, 0.5317325568414297, 0.6654150130018863, 0.7906408174555976, 0.904860733945285, 1.0057495743542582, 1.091253532831181, 1.1596319953545184, 1.2094929736144975, 1.2398214418809328, 1.25]
他會自己幫你展開成 12 個數字,分別從 0.25 到 1.25,這幾個數字是由 sine(n) + 0.25 計算而來。所以,當你開始跑訓練時,你會看到每一個層(Block)會依據你所設定的 UNet 學習率,乘上這個數字,來獲得每一層不同的學習率。
分層訓練的效果好嗎?
這個問題講真的我不知道。
以下測試皆使用相同 Prompt,
(8k, RAW photo, best quality, masterpiece:1.2),
(realistic, photo-realistic:1.2), ultra-detailed,
a girl wearing a hat with ears on it's head and a teddy bear,
relax face, black eyes, smile, facing viewer, upper body,
the high-key lighting with a soft bokeh and ethereal feel,
負面提示詞皆使用,
easyNegative, illustration, 3d, sepia, painting,
cartoons, sketch, (worst quality), disabled body,
(ugly), sketches, manicure:1.2,
ng_deepnegative_v1_75t, negative_hand-neg


v188, v191 使用預設全訓練,v189, v190 使用以下訓練參數:
Down LR Weights設定sine+.25。Mid LR Weights設定1。Up LR Weights設定cosine+.25。
訓練集與其餘訓練參數皆相同,
- 使用
Lion,超參數weight_decay=0.02 betas="0.95,0.98"。 - UNet 學習率
0.0001。 - 總步數
3,150,訓練 12 個 Epoch。 Total Batch Size為2。Gradient accumulate steps為2。

v187 為全訓練,v186 使用常數分層訓練,訓練參數為:
Down LR Weights設定0,0.5,1,0.5,0.5,0.5,0,1,1,0,0,0。Mid LR Weights設定1。Up LR Weights設定0.5,0.5,1,1,1,1,0.5,0.5,0.5,0.5,0,0.5。
訓練集與其餘訓練參數皆相同。
結語
如果需要更好的泛型,或是訓練風格,可以考慮分層,人物的話就必需要做更多測試,才會抓到比較好的分層訓練的設定數值。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)