
![[Lora] 權重調配與訓練記錄](/content/images/size/w960/2023/04/00001.png)
主要是要記錄一下一些實驗性的東西,失敗的過程也是過程,雖然沒辦法完全理解,但是總是可以大概知道這些東西是怎麼組成的。前些日子跟一樣是在玩 Stable Diffusion 的朋友聊,其實市面上不管是模型也好,理論也好,背後都是靠超多錢(一大堆 A100 運算好幾千個小時)堆出來的成果。
Lora Block Weight, Block?
我上次的訓練文章 有提到這個東西,後來在 Facebook 社團有人分享了他的訓練記錄,
中間也提到了關於 Domain Adaptation 與 Lora 可以對應到 Stable Diffusion 的 16 層 Attention Blocks 的結構(加上文字就有 17 層)。如果單純看 SD 的介紹,其實對我們這些門外漢而言,挺難理解,
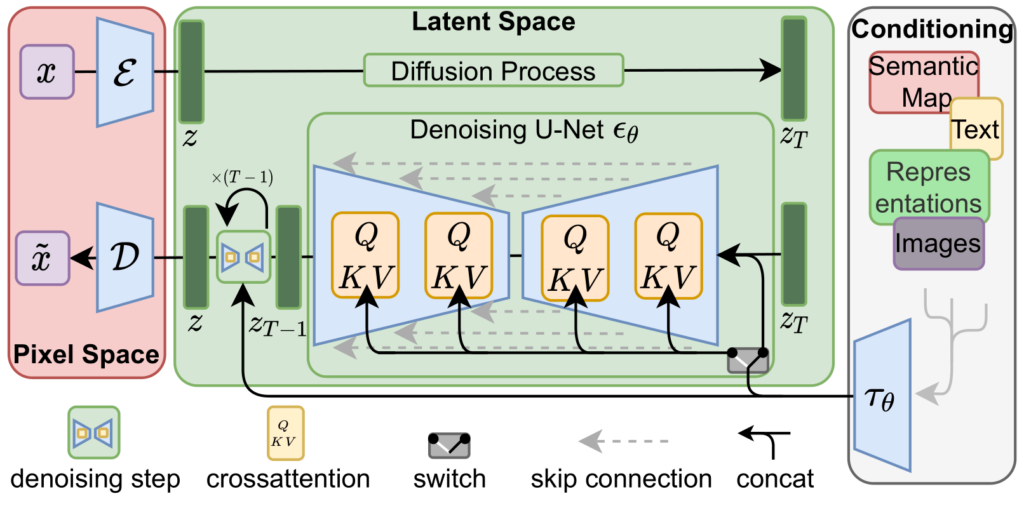
中間在做的事情這邊有個 Twitter 有一些說明。
To turn pure noise into an HD image, just apply f several times!
— AI Pub (@ai__pub) August 21, 2022
The output of a diffusion model really is just
f(f(f(f(....f(N, T), T-1), T-2)..., 2, 1)
where N is pure noise, and T is the number of diffusion steps.
The neural net f is typically implemented as a U-net.
4/15 pic.twitter.com/lxYvucaCGt
U-Net: Convolutional Networks for Biomedical Image Segmentation
Stable Diffusion を基礎から理解したい人向け論文攻略ガイド【無料記事】
所以,根據 LoRA Block Weight 作者的說明,關於 Lora 對應到這 17 層的分布,
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BASE | IN01 | IN02 | IN04 | IN05 | IN07 | IN08 | MID | OUT03 | OUT04 | OUT05 | OUT06 | OUT07 | OUT08 | OUT09 | OUT10 | OUT11 |
而 LyCORIS 可以做到更細,這邊就不說明了。
其中第一層 BASE 是屬於 Text Encoder 的部分,後面就是 U-NET 在做事情,上面那些文章都可以看一下 U-NET 的具體做法,我並不是專業,所以這邊只針對這個套件所提供的部分來做實驗。
那麼 Lora 透過這些權重能影響什麼地方,比較簡易的理解是(若下述有任何錯誤,麻煩請通知我改正,感謝),
- BASE 主要是 Prompt 轉化成 Text Embedding 處理的部分。
- IN01, IN02, IN04, IN05, IN07, IN08 則是關於 Downsample 的處理。
- MID 可以看做是 Conditional Block,表示 IN 的部分已經到達最低分辨率(或最大深度),此時會開始將 IN 的區塊進行條件處理,並準備把他交去給 OUT 去做事情。
- OUT03 - OUT11 則是關於 Upsample 的處理。
- 上述有包含 ResnetBlock 跟 Cross Attention 的部分就不說明了。
這裡有一個 SD 外掛可以把模型的 UNET 給弄出來,有興趣的人可以自行研究,
所以,當我們在使用 Lora 的時候,就可以在 Lora 後面加上分層權重,來進行微調控制。
# 這邊故意把 MID 寫成 1.5,方便讓大家知道他是中間。
<lora:hinaLora:0.75:1,1,1,1,1,1,1,1.5,1,1,1,1,1,1,1,1,1>
由於每個模型不同,所以這些參數只能自己慢慢實驗,並沒有一個非常標準的數字可以做出一定的結果。如果你對於融合模型有興趣的話,可以慢慢嘗試。
不過我這裡有一包從推特上看來的,
よし LoRA Block Weight の使い方は把握した
— さがわたつや (@t_sagawa) March 19, 2023
(チェックポイント、LoRA、BASE、IN01、...、OUT11) パラメータの組み合わせパターンが爆発して自分の手に負えないことが分かった
わからんがなんか良い感じになったところで撤退 pic.twitter.com/BGJ271trEg
我幫各位整理一下,雖然說是二次元可能比較適用,不過有興趣的人可以自行嘗試。
face:1,0,0,0,0,0,0,0,0.8,1,1,0.2,0,0,0,0,0
Nface:1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,1,1
ware:1,1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0
pose:1,0,0,0,0,0,0.2,1,1,1,0,0,0,0,0,0,0
paint:1,0,0,0,0,0,0,0,0,0,0,0.8,1,1,1,1,1
char:1,1,1,1,1,0,0,0,1,1,1,1,1,1,1,0,0
back:1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,0,0
soft:1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1
訓練 Lora
我上次的訓練文章 就講個大概,這邊僅列出一些訓練過程中,遇到的參數,跟設定上的考量。
Network Alpha在一開頭的文章中有提到,如果太大可能會有神機錯亂的狀況。所以如果是訓練很特定的人物、風格等,把他限縮在Network Rank (Dimension)的一半,或更小(需要是 4 的倍數)比較好。但是,這個數字設定太小的話,你的學習次數就得提高一點。Text Encoder learning rate可以用1e-5。Max num workers for DataLoader如果你主機記憶體少,設定成0比較好。他的用意是降低每次 Epoch 的延遲,就是 worker 會把資料集放在記憶裡。Gradient accumulate steps通常來說Train Batch Size越大模型會越趨穩定,但是沒那麼多錢去買顯卡,所以可以利用這個數字來有效降低Train Batch Size的數字,但 Epoch 次數會乘以這個倍數上去。
以下則是需要使用 Additional parameters 額外加,
keep_tokens如果你訓練相當特定的 token,而且那個 token 都在最前面,可以設定1,不然就0就好了。Don't upscale bucket resolution沒開的情況下,以下兩個參數才有效,--min_bucket_reso=256最小 bucket 解析度。--max_bucket_reso=1536最高 bucket 解析度。
--face_crop_aug_range臉部訓練的放大倍率,可以用"2.0,3.0"之類,看你需要放到多大(一般來說訓練圖集臉都不會太小才對)。--vae可以在訓練集中加入 VAE。--prior_loss_weight如果是新手,用0產出的資料會讓你比較有信心。
詳細的參數其實很多,我沒有每一個都去挖出來實驗,畢竟跑一次訓練挺久的。不過,雖然前幾次使用 runwayml/stable-diffusion-v1-5 都沒什麼太大的問題,但最近的一次訓練當中卻翻車了。


其實總共訓練了 8 個輪次,然後在第一次 sample 出來的時候,就有點不太妙的預感,不過因為還在趕著其他的專案,就沒有繼續關注,讓他默默的跑完。這一次的訓練時間大概是 6.5 個小時左右,訓練圖集有增加了一點,然後把正規化圖片全數刪除,使用比較正確(貼近真人)的照片。
但我覺得翻車的部分有兩個,
- 我提供了大量高解析度圖片,最大約
1536x1536。 - 我的
Max resolution設定為1024。 - 承上,這讓我訓練過程中的 VRAM 吃到 16GB。
Network Alpha以為設定64不會出事(同一批訓練資料,上次是48)。--prior_loss_weight我使用1。
根據外媒(?)的說法,把 prior_loss_weight 設定成 1 會讓訓練出來的模型更趨近於泛型,不太確定是否是這個緣故?總之,之後會再找時間用小模型來測試這件事情。
最後,就放一點這個失敗的 Lora 所產出的圖...












結語
我都不知道這個 Lora 到底是不是練壞掉,對我原本的目標來說,他確實不是我要的結果。除了已經 Overfitting 到超越了之外,他更偏向於把既有模型中類似 2.5D 的風格融會進來了。
講真的讓我想起桂正和。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)