
![[Lora] SDXL 真實系訓練手稿](/content/images/size/w960/2024/05/00364-1167181870.jpg)
這個筆記是最近大概兩個多月來訓練的總結,是特別針對 SDXL 真實系列訓練的所有過程。包含訓練集圖片處理、提示詞、Kohya 參數調整,基本上可以算是一個稍微進階一點的懶人包。如果是第一次練 SDXL 真人系列的話,可以做為參考。
前言
本次訓練是使用 Kohya GUI 24.1.4 版本進行,你的版本沒有那麼新也沒關係。但是,由於本次訓練使用到了 --enable_wildcard 的功能,所以請確保你的 Kohya 裡面所使用的 sd-script 是 0.8.6 版本以上,他才有支援 --enable_wildcard 的功能。
另外,本次的提示詞標記,有使用到 Google Colab,所以如果你沒用過的話,請稍微研究一下他的使用方法。
訓練圖片準備
首先,由於我們是要訓練 SDXL 的 Lora,所以基本上你的訓練集的品質不能太差。訓練是這樣,garbage in garbage out,所以基本上最好都是準備 1024x1024 以上尺寸的高品質圖片。數量的話,以我目前所做的幾次訓練來說,約莫整理 150 張照片就足夠。照片的需求大概是以下幾點:
- 盡可能高畫質,如果真的不行,用 SD 的工具做低度重繪放大也可以。
- 寬與高的尺寸維持 32 的倍數,因為我們要使用
Bucket resolution steps = 32。 - 人臉盡可能保持在畫面中央,沒有也沒關係,例如全身可能無法,但不要太多,我們會用提詞解決。
- 人臉、半身、全身的比例約為
5:3:2,大概就好。 - 特殊角度、特殊鏡頭效果,例如魚眼、超廣角人物特殊取角,會讓臉部產生過度變形的請剔除。
圖片的尺寸我們會使用 ARB 分桶處理,所以你沒有必要裁切成 1024x1024,唯獨要保持 32 的倍數。另外,如果你對分桶比例有一定堅持的話,可以試試看我所寫的分桶計算工具。
使用的方式請參考我之前的文章 [Lora] 切臉訓練設定誤區。準備好照片之後,我們要使用 Colab 來幫我們做提詞的動作。這邊要大力感謝 @gesen2egee 所撰寫的工具!
提示詞準備
首先,請先登入你自己的 Google Drive。
警告!
請不要在你的 Google Drive 上傳違反使用規則(例如暴力、色情等)的資料,不然你的帳號消失了不要跑來怪我。
先在你的 Google Drive 中建立一個資料夾,這個資料夾會用來放置你剛剛準備好的圖片,資料夾的命名規則為 X_triggerWord,就跟在 Kohya 訓練時很像,但這邊並不會採用你的重複數量,只是方便切出觸發詞而已。舉例來說,我們可以命名為 6_hinaigirl 這樣的資料夾來放置圖片。
接著,打開這個 Notebook,
打開之後,這個 Notebook 分為兩個區塊,上面那個區塊是前置作業,請先運行上面那個區塊,等他結束之後,第二個區塊有個地方要修改,
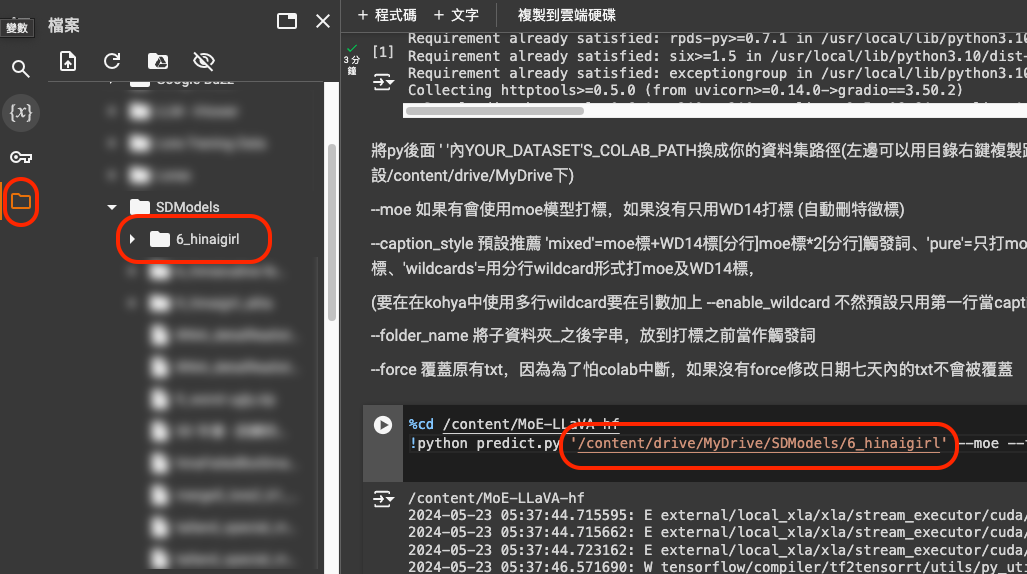
資料夾的位置要從左邊的資料夾中複製過來,你在資料夾上按右鍵就會有一個「複製路徑」可以用,把他貼到第二個區塊的那個位置。然後按下第二個區塊的執行,慢慢等他跑完。
如果你是免費用戶,以 T4 的運算速度,算 150 張大概要 1 小時左右,請勿關閉瀏覽器,放著讓他算完就好。算完之後,你回到你的 Google Drive 會發現有已經算好的提示詞檔案。
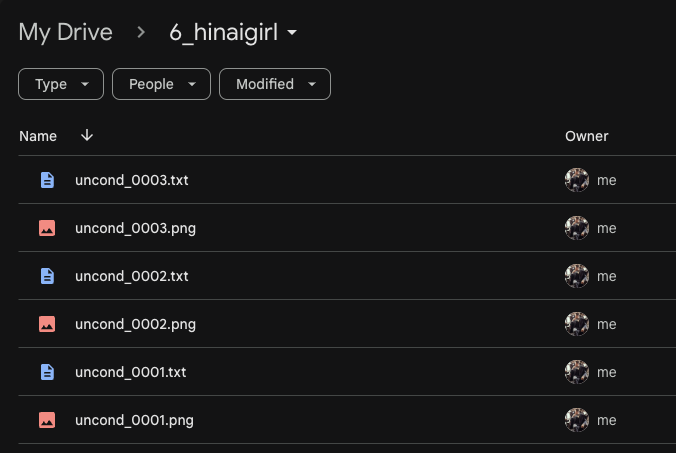
你可以打開提示詞檔案,以我所使用的圖片為例:

a character hinaigirl in this image, rating:sensitive, realistic, the whole image consists of the following: |||solo, 1girl, brown hair, long hair, looking at viewer, cleavage, brown eyes, large breasts, lips, shadow, shoes, covered navel, detached sleeves, full body, bare shoulders, white leotard, loose socks, standing, mecha, highleg leotard, closed mouth, collarbone, arms at sides, beam saber, thigh gap, science fiction, white socks|||, in the image, a woman is walking past a large, mechanical structure, possibly a robot or a machine. she is wearing a white outfit and appears to be posing for the camera. the scene seems to be a creative or artistic representation, possibly a photoshoot or a display, as the woman is not interacting with the mechanical structure in any way. the image appears to be a blend of fashion and technology, with the woman's attire contrasting with the mechanical nature of the background.
a character hinaigirl in this image, rating:sensitive, realistic, in the image, a woman is walking past a large, mechanical structure, possibly a robot or a machine. she is wearing a white outfit and appears to be posing for the camera. the scene seems to be a creative or artistic representation, possibly a photoshoot or a display, as the woman is not interacting with the mechanical structure in any way. the image appears to be a blend of fashion and technology, with the woman's attire contrasting with the mechanical nature of the background.
a character hinaigirl in this image, rating:sensitive, realistic, in the image, a woman is walking past a large, mechanical structure, possibly a robot or a machine. she is wearing a white outfit and appears to be posing for the camera. the scene seems to be a creative or artistic representation, possibly a photoshoot or a display, as the woman is not interacting with the mechanical structure in any way. the image appears to be a blend of fashion and technology, with the woman's attire contrasting with the mechanical nature of the background.
a character hinaigirl in this image, rating:sensitive, realistic,
a character hinaigirl in this image, rating:sensitive, realistic,
這個提示詞結構我們所使用的是,
- 長提示詞 +
|||+ 短提示詞 +|||+ 長提示詞。 - 長提示詞
- 長提示詞(同上)
- 觸發關鍵詞
- 觸發關鍵詞(同上)
這邊會使用到 Kohya 的一個功能,叫做 keep_tokens_separator,這也同樣是 0.8.6 之後才支援的新功能。他在提示詞裡的用意是,將打亂提示詞或拋棄提示詞的作用範圍限制住。換句話說,以上述的結構來看,前後的長提示詞會被固定,而被 ||| 包裝起來的短提示詞會被隨機打亂或是拋棄。
這樣做的好處在於,我們可以避免短提示詞在訓練的過程中,過度的強化而造成特徵的過擬合,或是受到基底模型的相關提示詞污染。
整份提示詞總共有五個段落,這五個段落將會在啟用 --enable_wildcard 的時候,隨機的挑選一組來做訓練。也由於這樣的隨機性,整體訓練過程中,就能保證會產生一定程度以上的泛化程度,對於特徵本身,也能適度的削減產生過擬合的現象。
提示詞是否要手動修正則看需求,若你發現文字裡面有圖片所沒有的描述,你可以適度的刪減他。
Kohya 訓練設定
我們這邊所採用的是 LyCORIS/LoCon 作為目標 Lora 格式,關於設定檔案的部分,你可以直接照抄我的設定:
關於我的設定有幾點要額外說明一下:
- 我使用的是總步數限制,設定檔案中是使用
6,000步。 - 我的訓練集圖片張數是
150張,每張重複次數是6次。 - 我有使用正規化圖片訓練集,正規化的圖片是
100張,每張重複次數是9次。 - 設定檔案中的 Network Dim 使用
128,你可以縮減成64或96。 - 我有使用
module_dropout為0.05,你可以關閉。 - 我沒有使用 Keep n Token,你如果有需要可以寫
1。 - 我的 Total Batch Sizes 設定為
4,如果你的 VRAM 吃緊,可以使用2。 - 我有開啟
fp8 base使用 fp8 訓練,可以比較省 VRAM,如果你使用上有問題,可以取消。 - 基底模型使用的是真實係模型 LEOSAM's HelloWorld XL v6.0。
- 我有使用 Original Noise Offset,並設定為
0.0357,如果你覺得不必要可以設定成0將他關閉。
以上是整體的訓練參數,你可以視你的情況略做調整。訓練所使用的優化器,我目前測試過以下幾種,
Lion8bitAdamW8bitProdigyAdafactorDAdaptaionDAdapAdamPreprint
而本次所使用的就是 DAdapAdamPreprint,當然如果你有慣用的參數,你也可以使用其他的。
訓練結果
就看圖說故事就好了。





訓練結果
結語
整體來說,這樣的提詞方式在訓練上面對於泛型的幫助很大,整體的特徵也不會走偏或是被基底模型帶偏,總結來說,這應該是目前測試了 60 幾爐,在 SDXL 上面效果算是非常好的提詞方式了,也因為 Kohya 提供了 --enable_wildcard 與 keep_tokens_separator 這樣的功能,所以對於整個學習過程來說,就能帶入更多元的提詞方式,對於訓練結果來說,著實是相當不錯。
SDXL 煉上一爐最少都得花上 5 小時,我是不是該學一下 @furusu,明天開始去販賣機底下撿銅板,一定有哪一天可以買一張 A6000 才對!

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)