
![[ComfyUI] ControlNet, IPAdapter, AnimateDiff 目標與背景處理](/content/images/size/w960/2023/11/ComfyUI_temp_snpmj_00013_.png)
這篇文章的主題,主要是來自於 ControlNet 之間的角力。就單純論 ControlNet 而言,某些組合的情況下,很難針對畫面中的目標進行更換,例如服裝、背景等等。我在這裡提出幾個討論的方向,希望對大家有所幫助。
Prompt & ControlNet
如同我之前文章 [ComfyUI] AnimateDiff 影像流程 提到的所使用的 ControlNets 來說,這次我們會著墨在這三個 ControlNets 的控制,
- OpenPose
- Lineart
- Depth
我們使用 ControlNet 來提取完影像資料,接著要去做描述的時候,透過 ControlNet 的處理,理論上會貼合我們想要的結果,但實際上,在 ControlNet 各別單獨使用的情況下,狀況並不會那麼理想。
這個情況並不只是應用在 AnimateDiff,一般情況下,或是搭配 IP-Adapter 的狀況就會更加明顯。我們以實際的例子來操作說明。底下是我目前所使用的提示詞,
adult girl, (extreme detail face),
(white bikini), bikini, short top,
indoor, in front of sofa, bed, window, (bedroom),
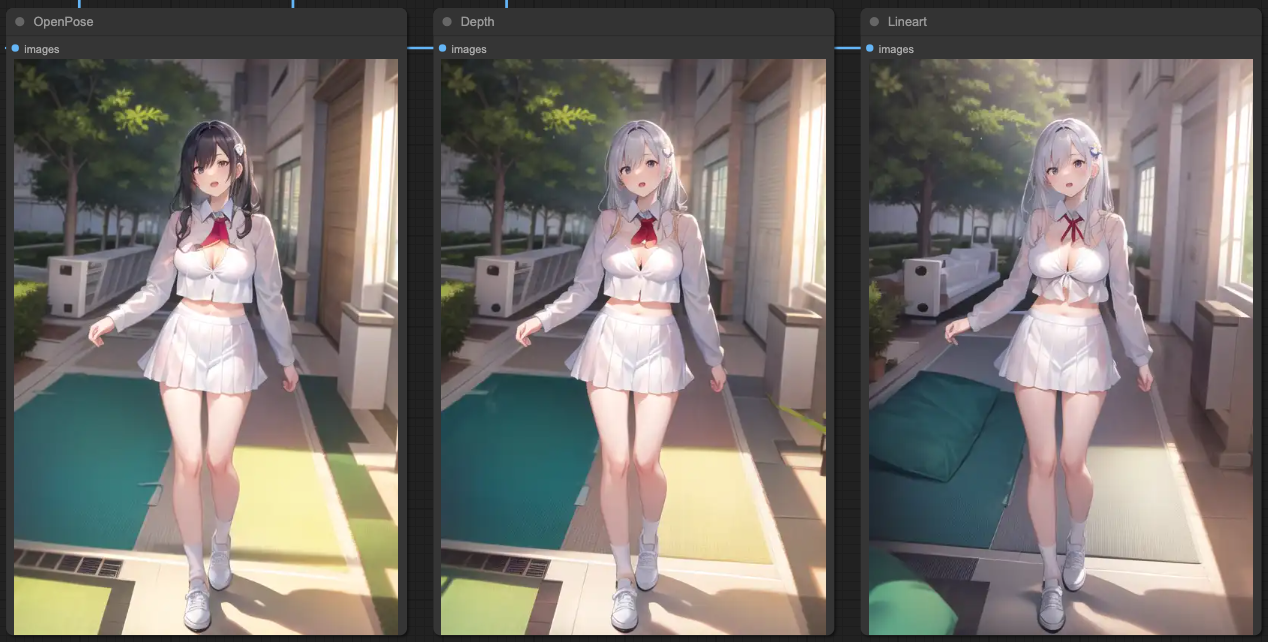
然後我們來看看三個 ControlNets 的產出,
OpenPose
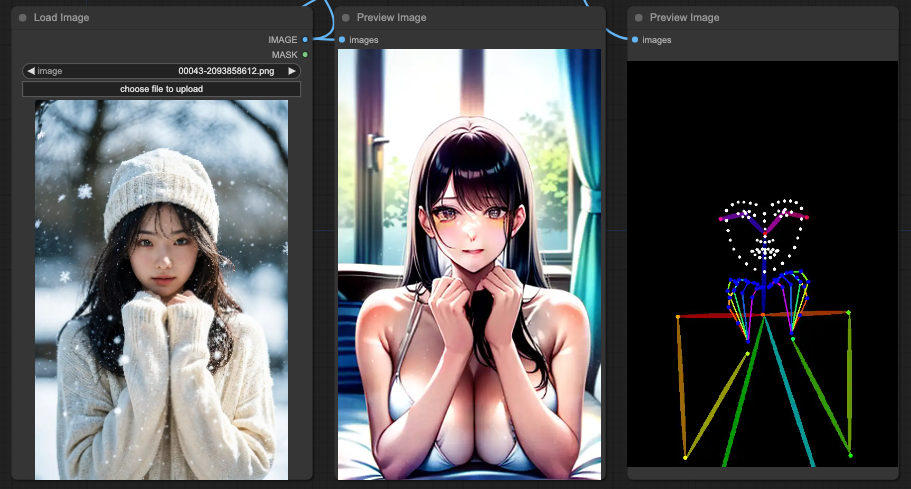
Depth
Lineart
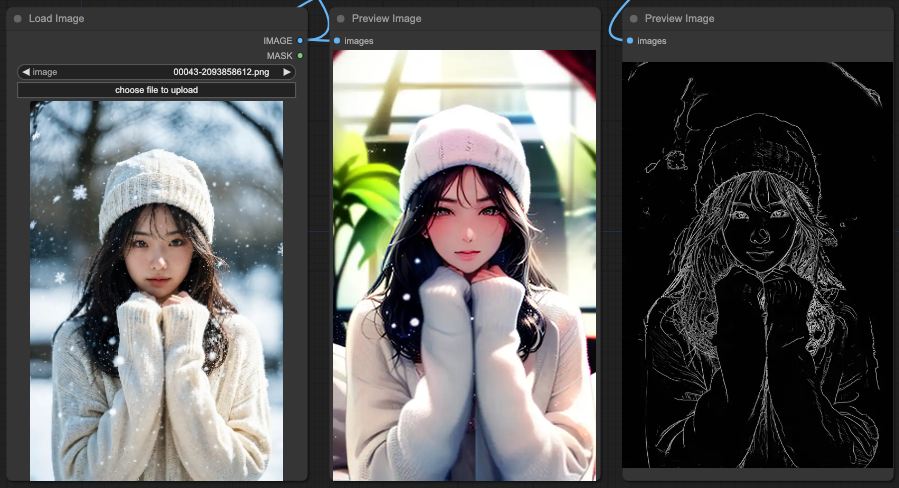
你會看到 OpenPose 對於整體的提示詞表現是最合理的,接著是 Depth 只剩下背景部分還算合理,而最後的 Lineart 也只剩下背景還算合理。
如果我們把這幾個 ControlNets 接起來會發生什麼事情?
OpenPose + Depth + Lineart
把所有 ControlNets 接起來的結果,幾乎是完全偏離了提示詞內容了。
OpenPose + Depth
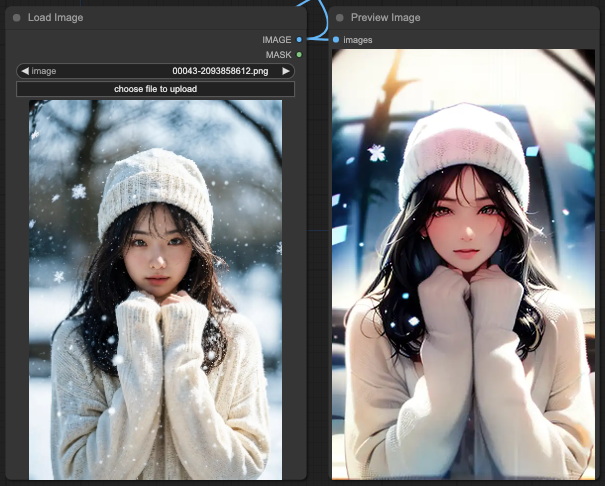
僅接上 OpenPose 與 Depth 的狀況,你會發現背景的窗戶還算比較貼合提示詞。
OpenPose + Lineart
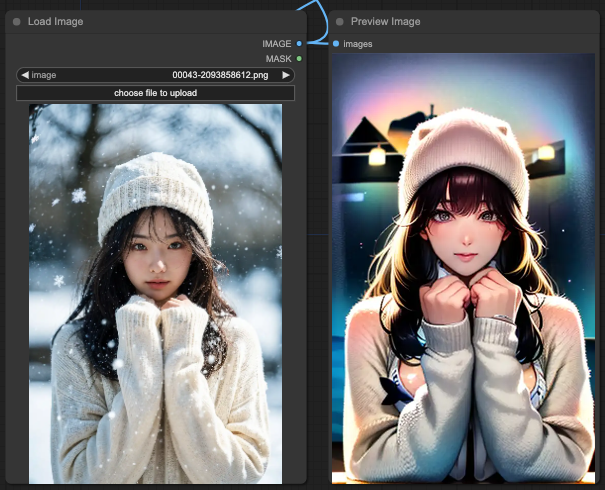
上面這個組合就更怪了,你會發現泳裝跟毛衣同時出現,但是背景變得不知所云。
Depth + Lineart
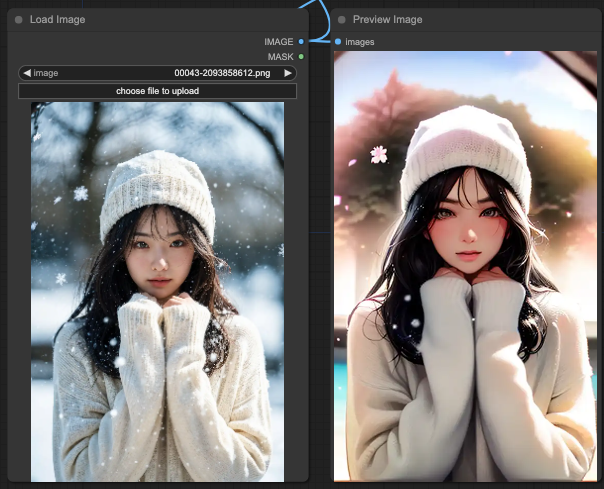
而最後 Depth + Lineart 則完全忽略了提示詞的所有概念,只是把畫面重新繪製一遍。
為何要著墨於這三組 ControlNets
我換一個參考資料來源,讓大家先看一下為何要使用組合的 ControlNets。
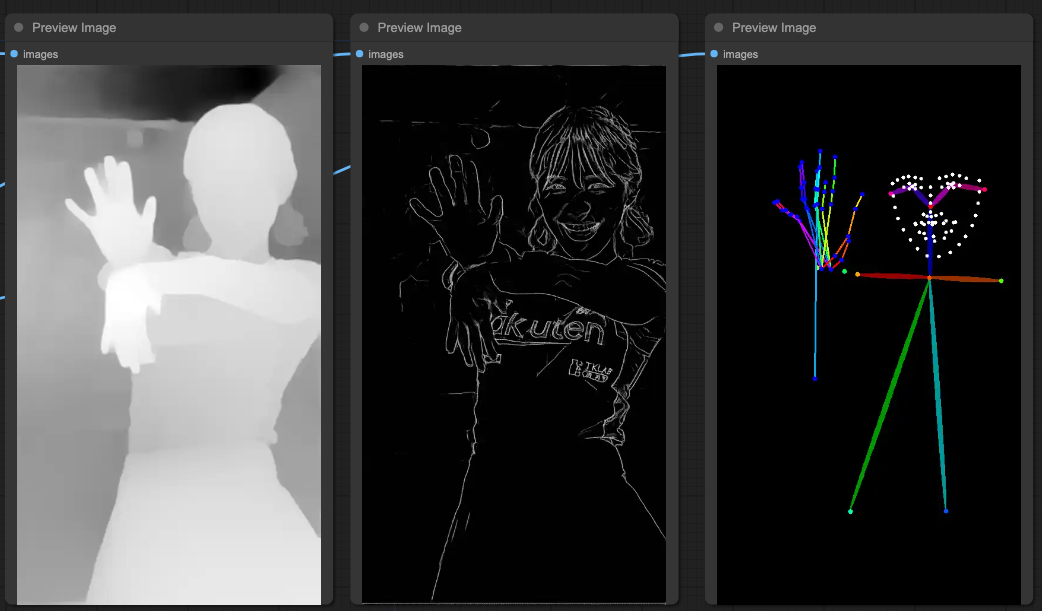
你可以看到最右邊的 OpenPose 其實並不是那麼準確,他雖然很明確的定義出了臉部,但是手部的動作基本上幾乎是無法使用。所以,我們還是會需要使用其他的 ControlNets 來明確的決定出肢體動作,與其肢體的前後關係。
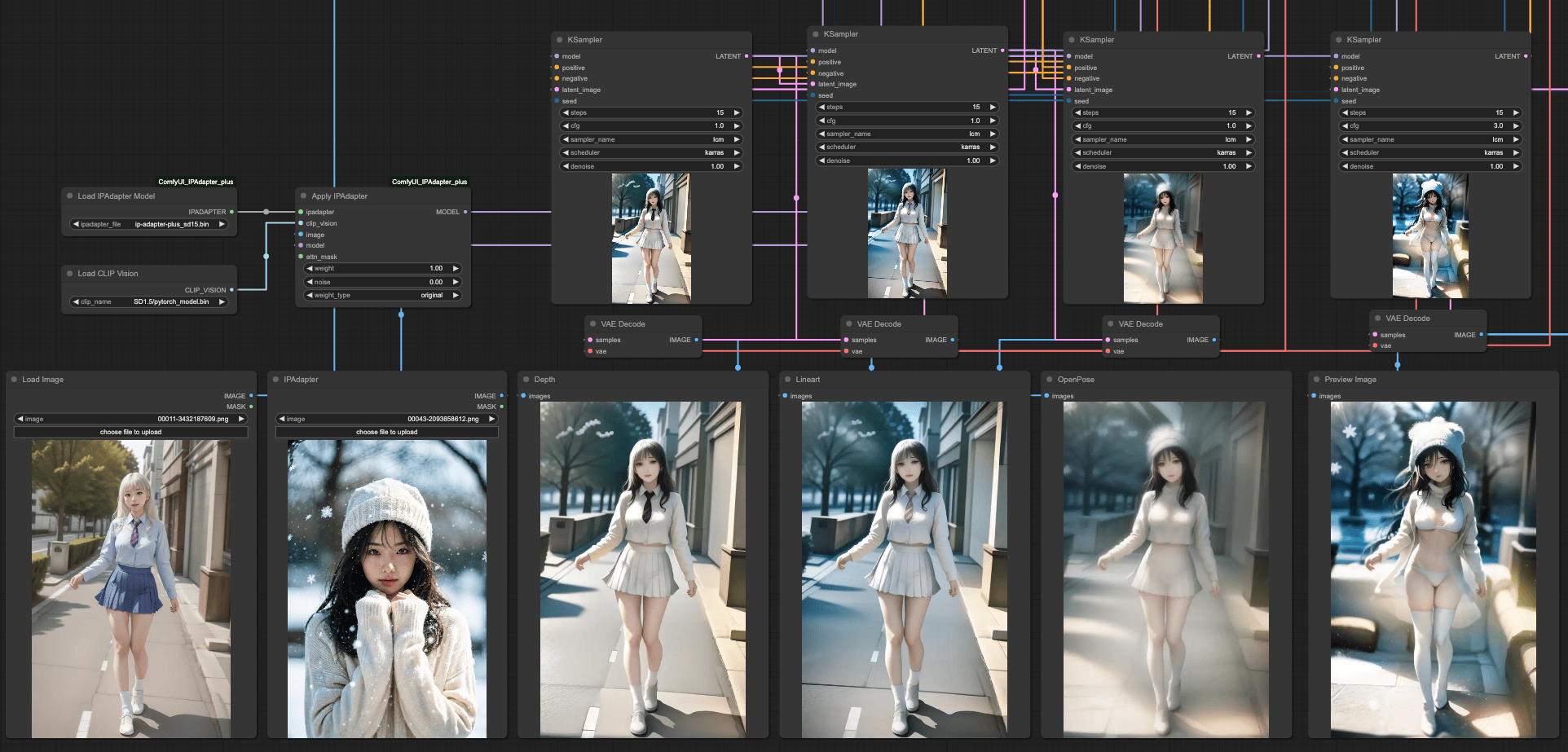
如果依照上面三組 ControlNets 直接取樣出圖的話,結果會是這樣,
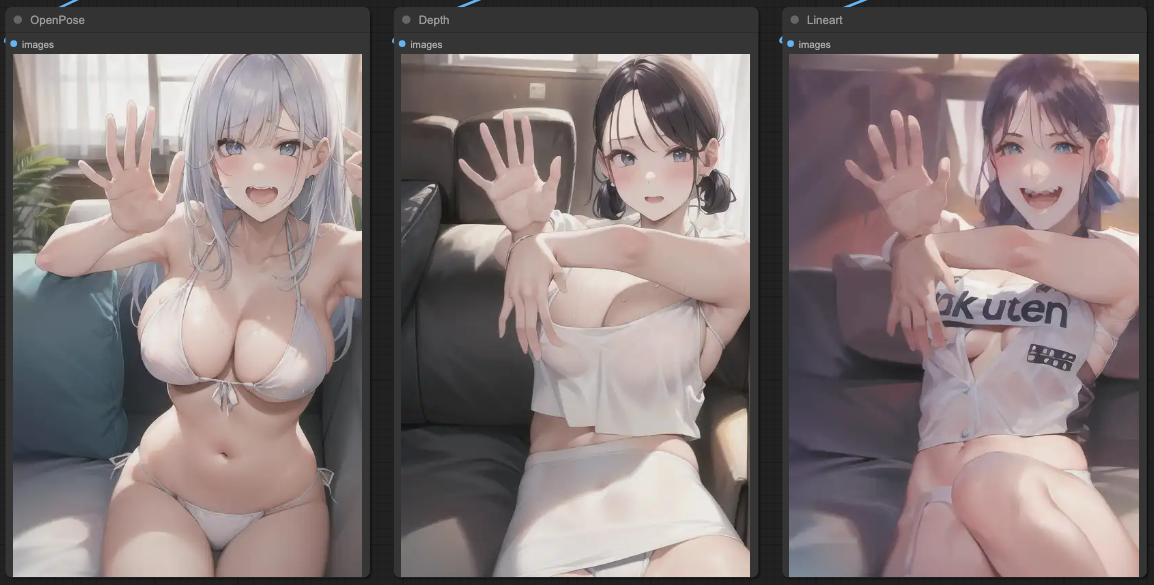
單獨取樣的狀況跟文章一開始的說明是一樣的,接著,我們需要把 ControlNets 串起來,用來達到符合我們的提示詞的狀況。我這邊連接的順序為,
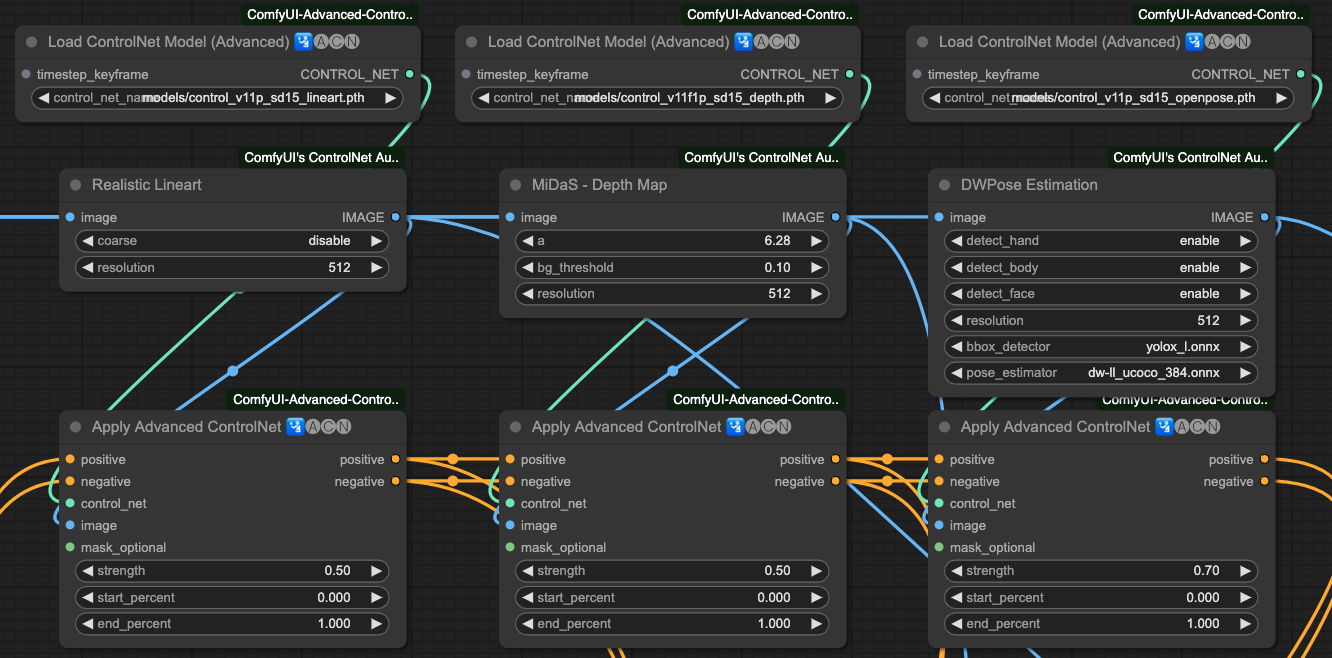
Lineart x 0.5 > Depth x 0.5 > OpenPost x 0.7
這樣我們會如果將每一個連接步驟做個別輸出,會得到這樣的結果,
如果,我們將 KSampler 依照我們的 ControlNets 順序作輸出串接,那麼我們會得到這樣的結果,
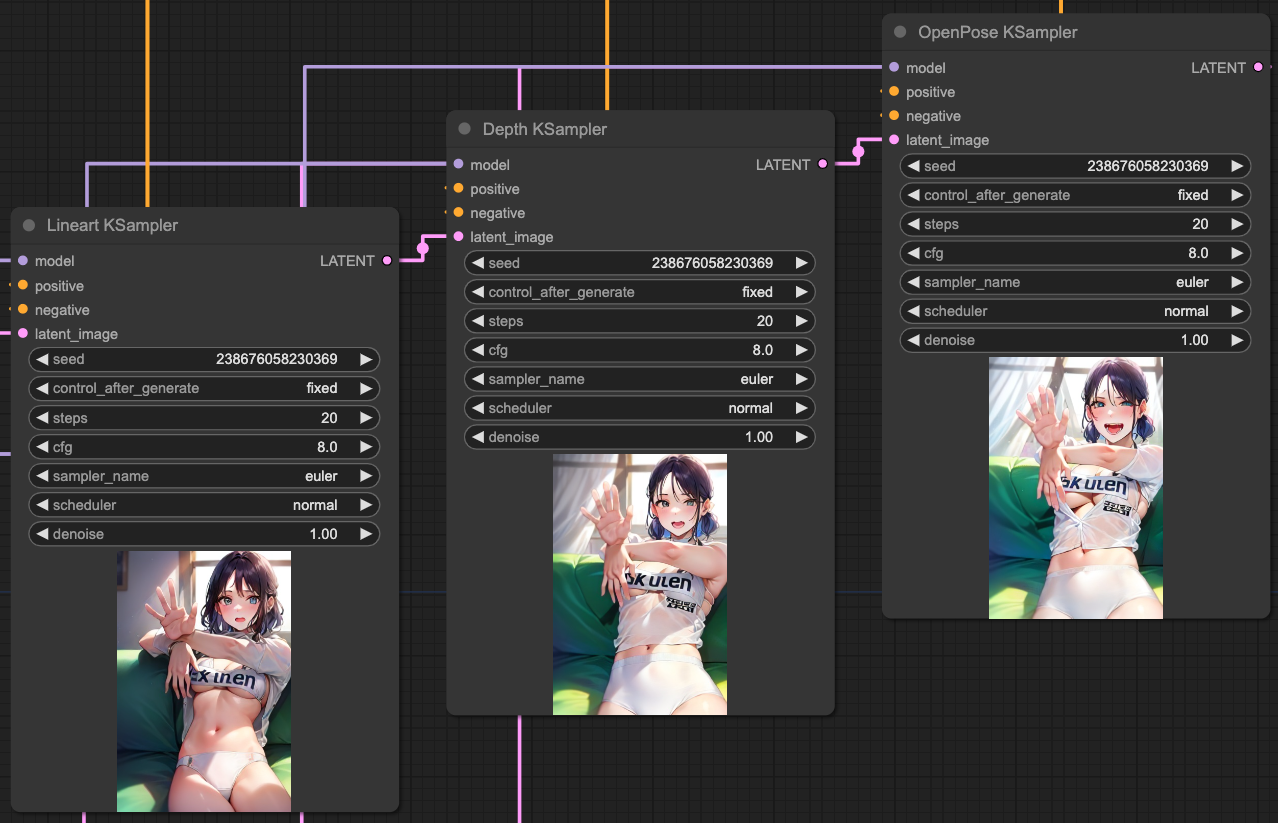
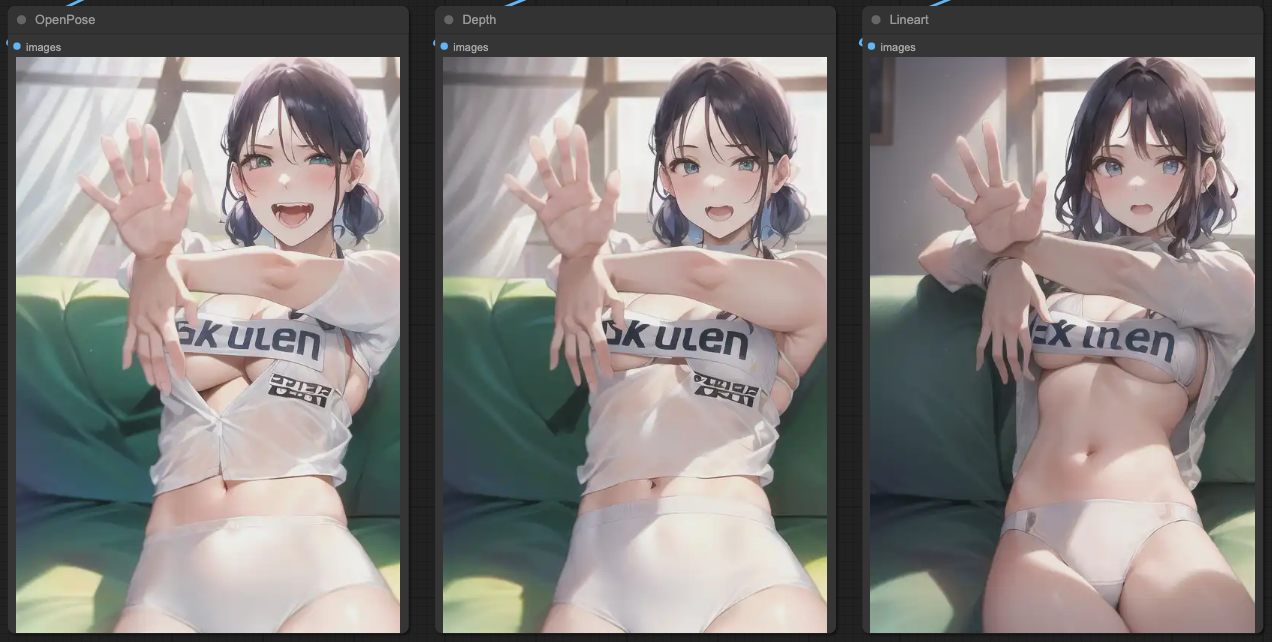
所以,根據這樣的結果,你可以連接 ControlNets 並且根據 KSampler 的結果,再次的把 KSampler 連接起來,這樣就能獲得更準確的輸出。
Mask & ControlNet
根據上述的結果,如果我們來測試其他的輸入來源,你會發現並不如預期中的美好。我們換一個來源來測試,你還是會發生特徵並不明顯的狀況。
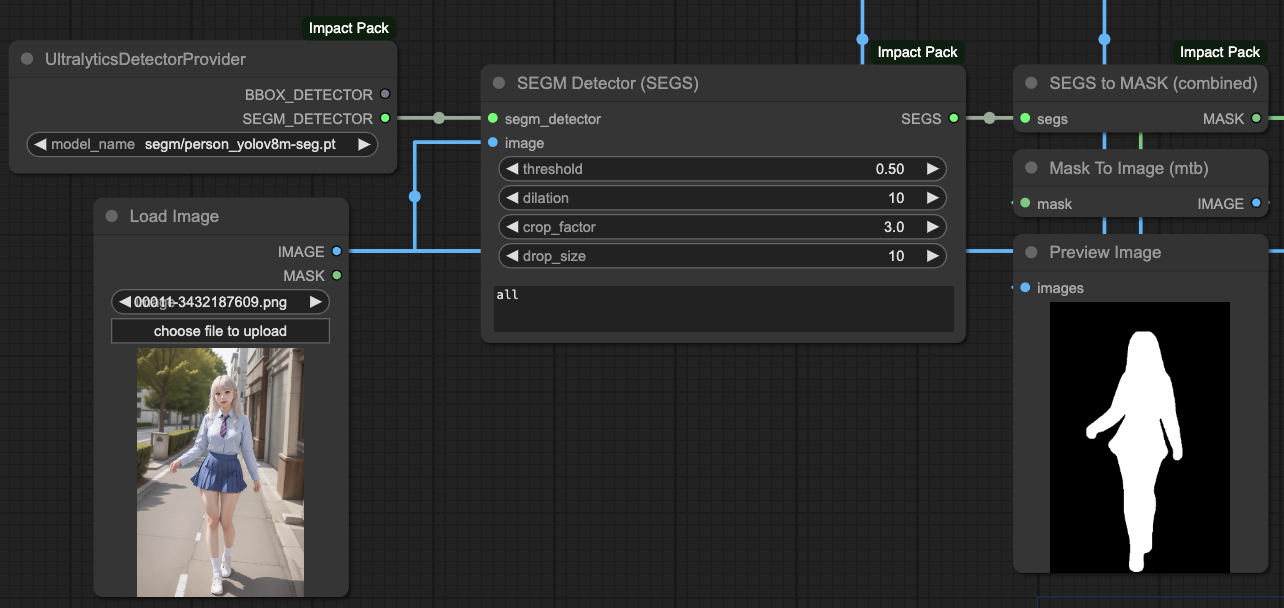
你會發現以同樣的步驟,在最後 OpenPose 輸出時,基本上還是參考了來源內容,整個背景與服裝並不是我們想要輸出的樣子。在這個時候,我們需要針對 ControlNet 的 MASK 動手腳,換句話說,我們讓 ControlNet 讀取人物的 MASK 進行處理,並且將原有 ControlNets 之間的 CONDITIONING 分開處理。
我們在這邊的處理方式是,
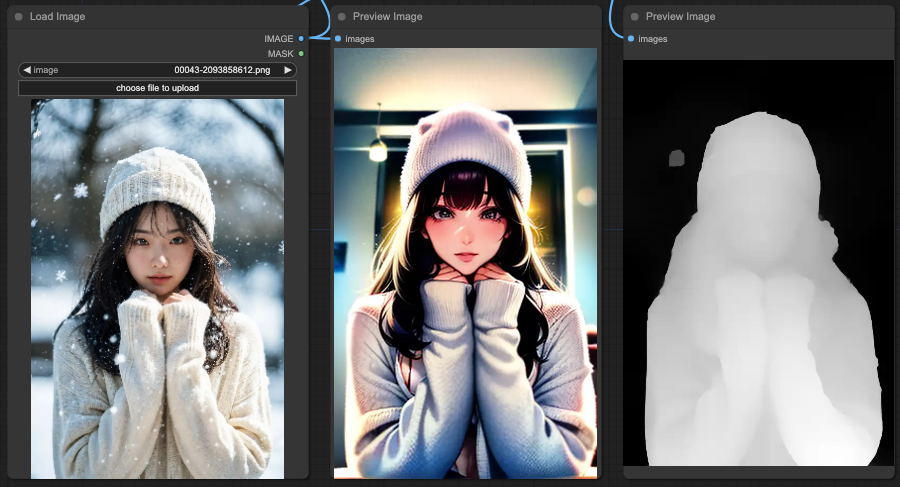
- 先針對目標物取得 MASK。
- 將 MASK 放到 ControlNets 裡面。
- 將 OpenPose 的 CONDITIONING 分離處理。
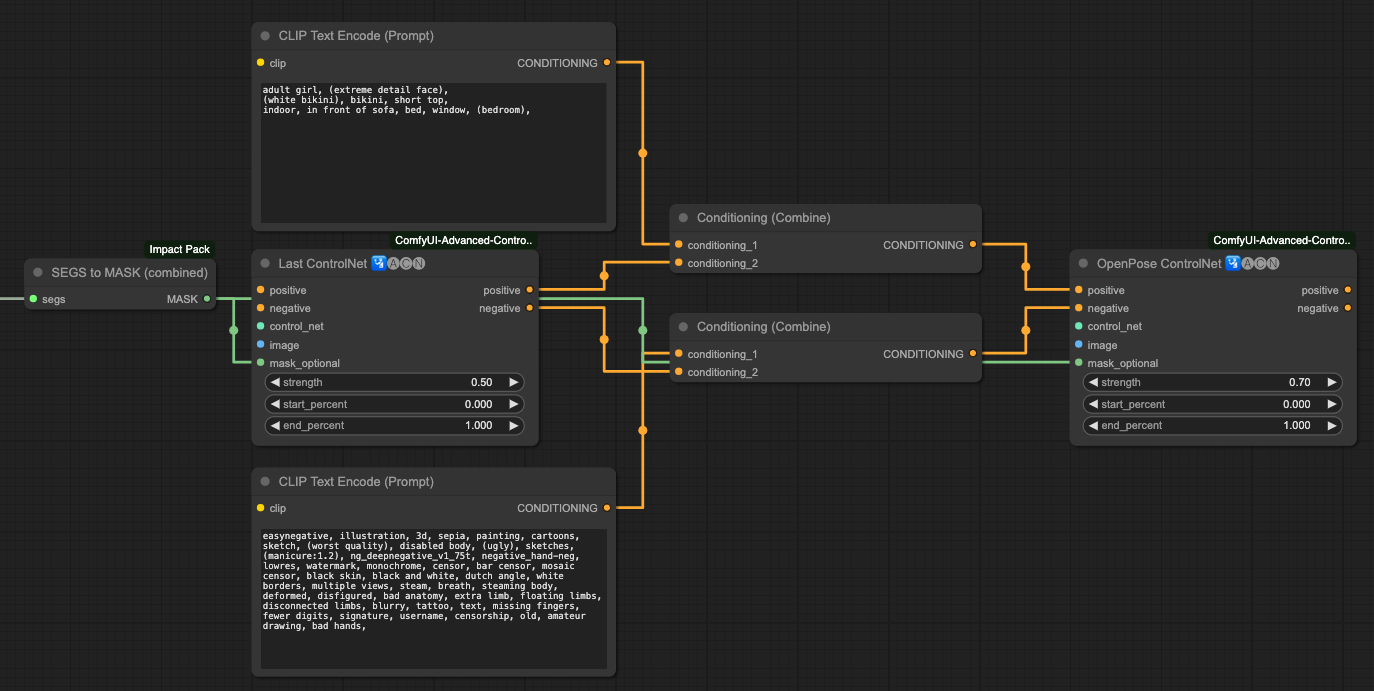
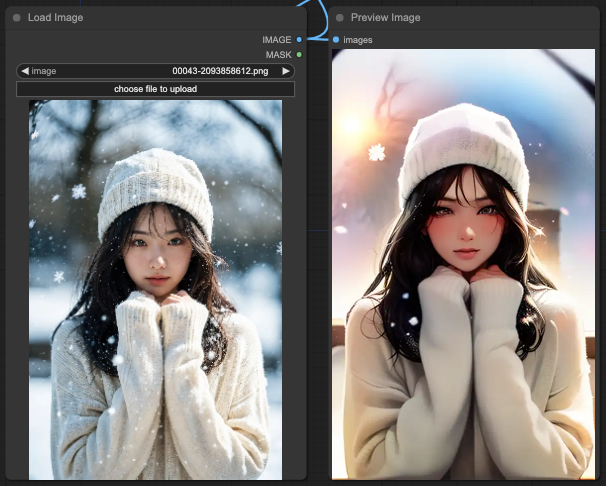
這樣分離處理之後,你就會拿到一個很符合你的提示詞的輸出結果。
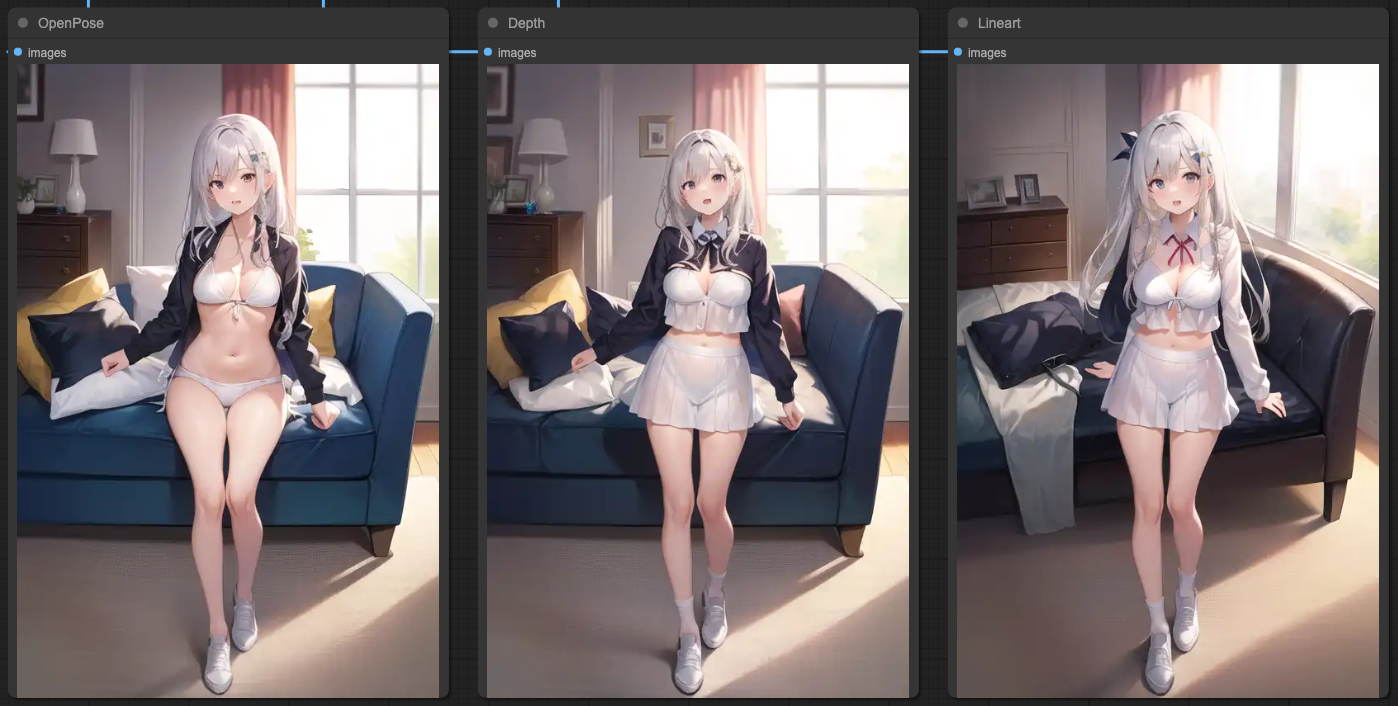
每一種圖形來源所搭配的 ControlNets 與其內容所產生的遮罩,並不是我這樣的組合是最佳解,你可以嘗試不同的組合方式,來達到最佳的輸出結果。這邊只是提供一個使用遮罩的方式,讓輸出的結果能夠最接近我們提示詞所想要描述的畫面。
請注意!並不是所有的來源圖像都適合使用 MASK 或是組合 CONDITIONING 的操作方式,你需要自己去測試怎麼樣組合會拿到比較好的輸出。
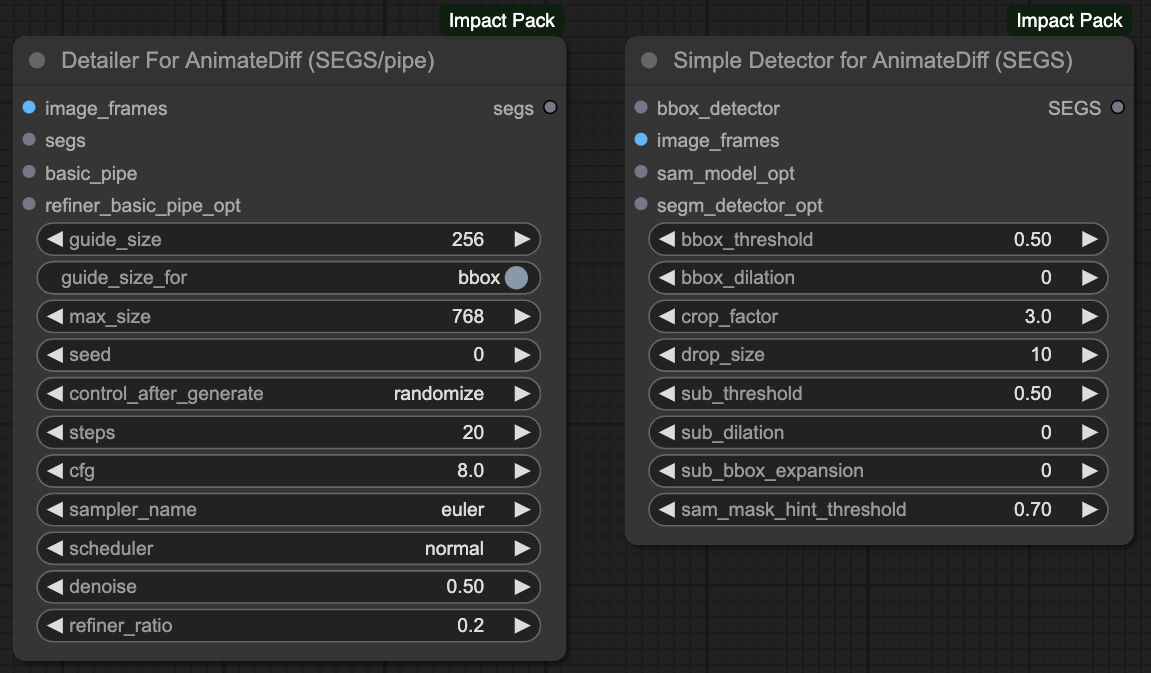
SEGs Detailer & ControlNets
跟上述使用 MASK 的方式很類似,不過這邊是更偏向於後處理(postprocessor)的一個作法。換句話說,我們是在所有的 ControlNets 都處理完畢之後,再針對我們所獲得的影像做一次後處理。
他的好處是,不太需要考慮 ControlNets 與 MASK 之間的相對應關係,也不需要調整 ControlNets 的順序與提示詞的分離處理。但是,這樣的效果並不一定會比較好,你需要自行比較這兩者的差異,選一個你覺得比較好的來使用。
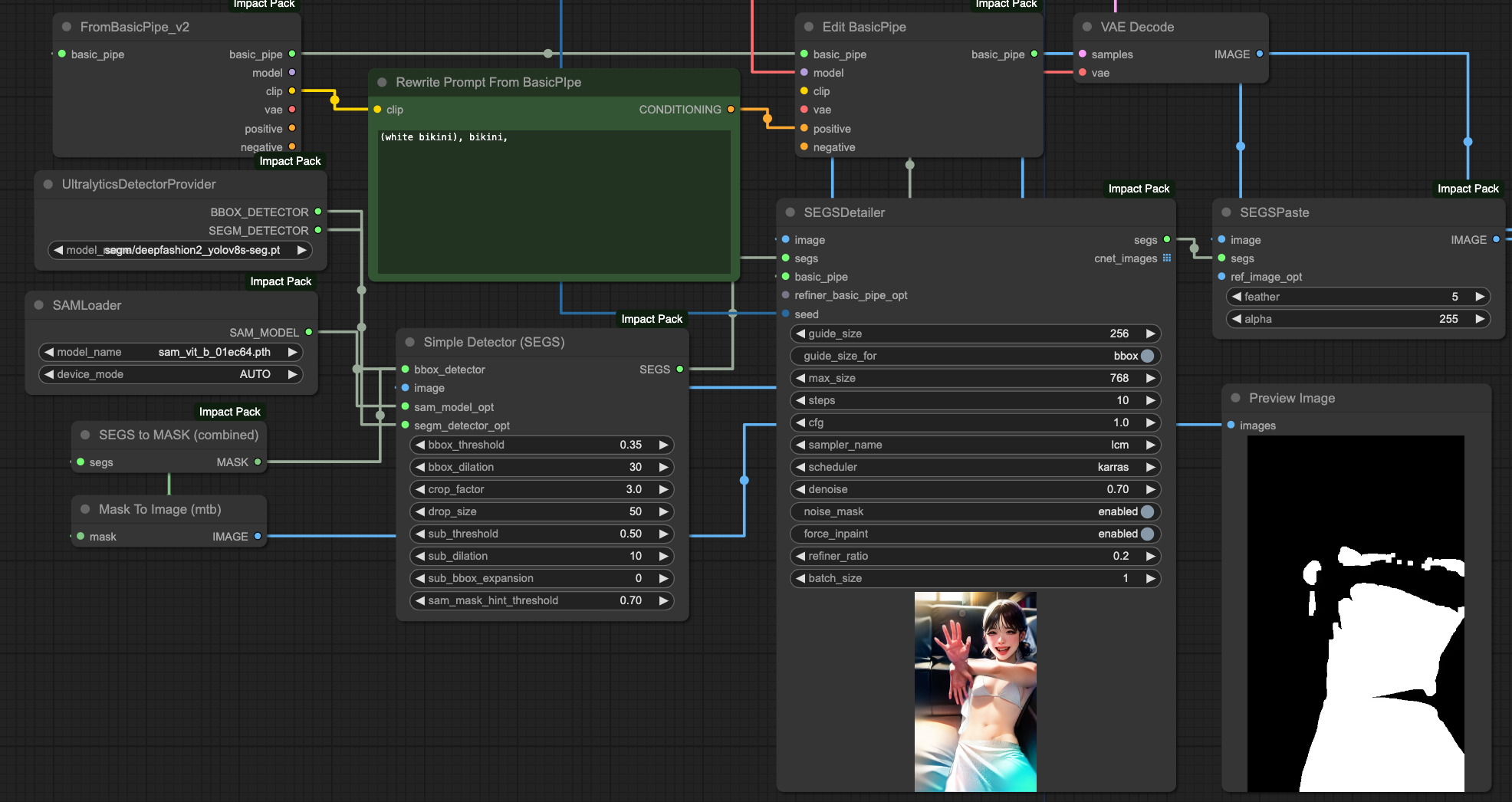
使用 SEGS Detailer 的流程,是在我們的 VAE Decode 輸出最終結果之後,針對最終結果利用 SEGS Detector 來幫我們圈出想要重繪的區塊,這裡的應用方式其實跟 MASK 很類似。
- 從 VAR Decode 拿到最後輸出的圖片。
- 把原有的 Pipe 當中的
positive的部分,利用 Edit BasicPipe 改寫。 - 使用 SEGM DETECTOR 並選用
deepfashion2_volov8s-seg.pt模型,這是一個 識別服裝 的模型。 - 接入 Simple Detector 後測試裡面的各種參數。
- 送去給 SEGSDetailer,並且確定
force_inpaint要啟用(enabled)。 - 最後送去給 SEGSPaste 將原有的輸出與 SEGS 合併。
在使用 SEGS Detailer 的部分,我們的 ControlNets 並不一定要上一段文章那樣測試整個遮罩流程,我們只需要在最後 VAE Decode 處理完成後,再做一次後處理即可。當然,這樣的效果是不是比較好,就見仁見智。
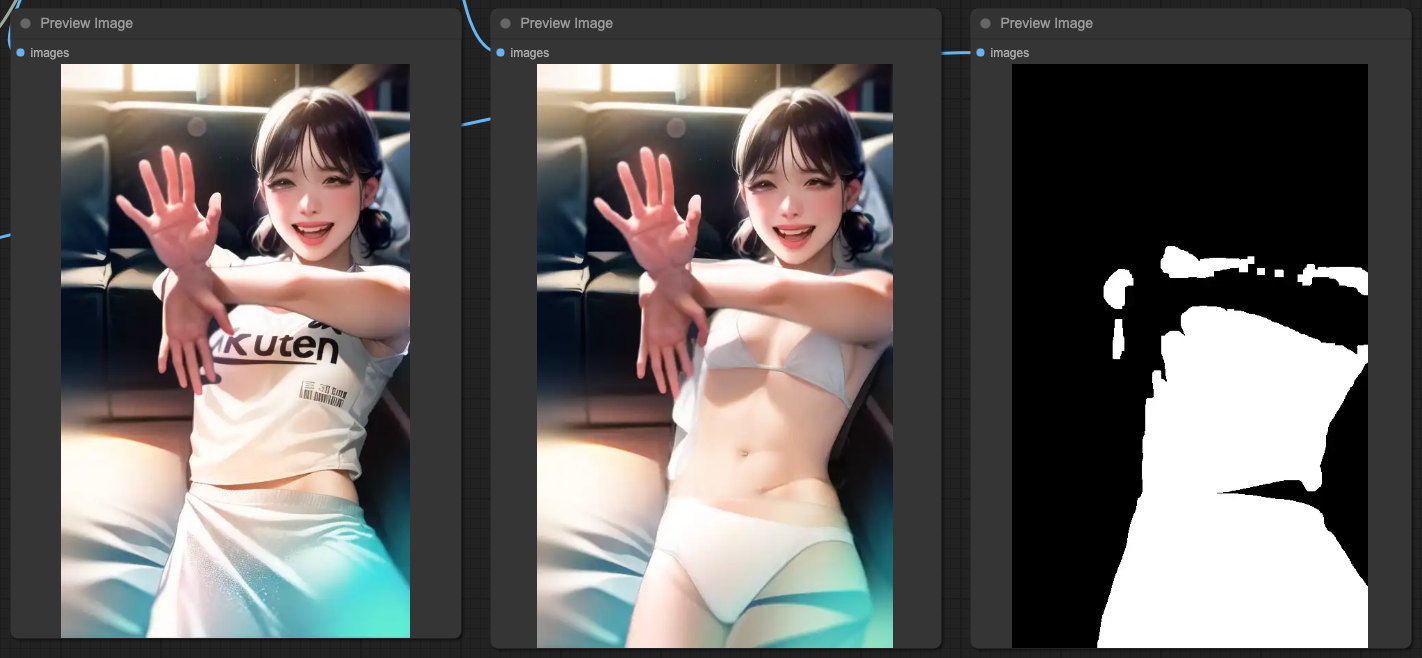
IPApater & ControlNets
首先,我們需要釐清當你使用 IPAdpater 想要在整個工作流程中帶來什麼效果。一般來說 IPAdapter 是參考整個輸入影像圖面,或是你只想參考臉部。我們這邊以 整個影像 來當作說明,這個部分與 ControlNets 的設計會有比較複雜的狀況跟干涉。
如果你想要使用 MASK 與 ControlNets 來達成干涉 IPAdapter 的結果,實際上的操作會非常的複雜。我們這邊先單純的來看 IPAdapter 與三種 ControlNets 結合後,各自的效果。
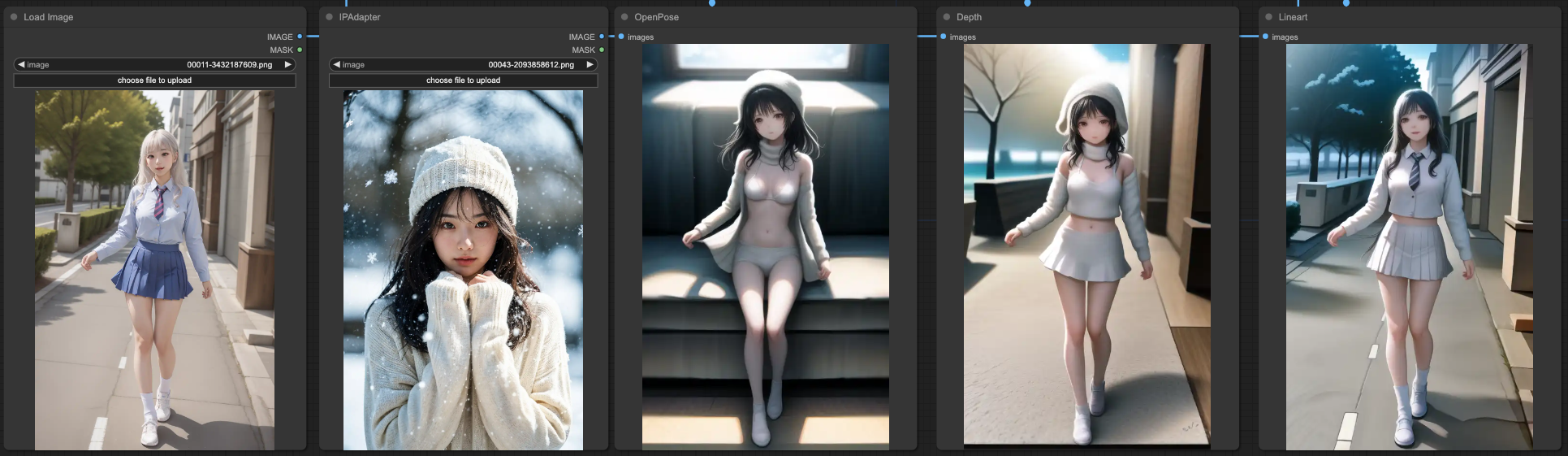
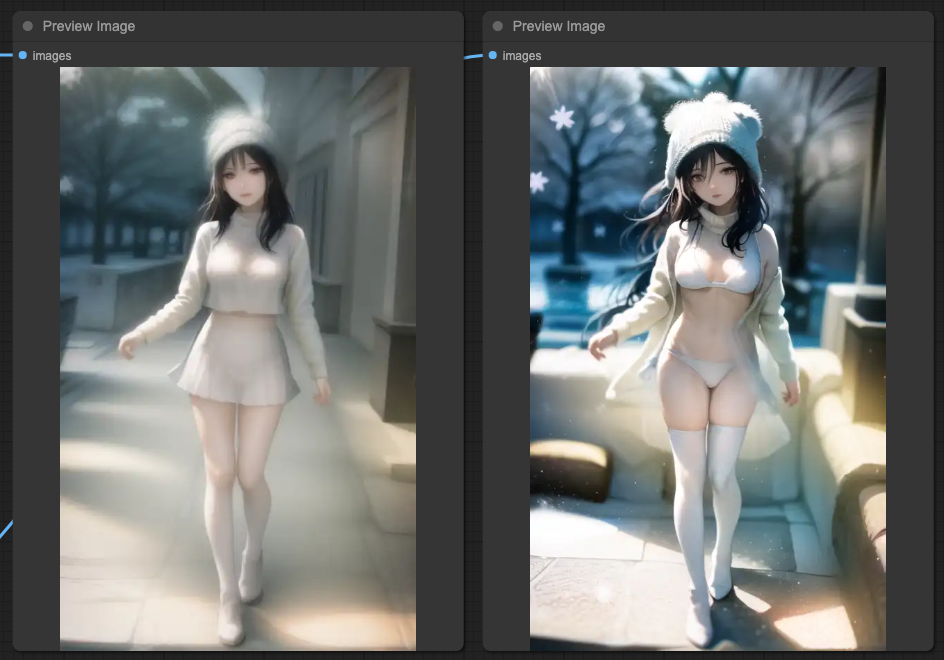
我們的基本提示詞還是相同,而出現的結果還是 OpenPose 會最接近提示詞,而其他兩個則會比較貼近原始的輸入圖片。在這個情況下,無論你怎麼組合這些 ControlNets,最終都會得到一個融合 IPAdapter 與原始圖片的結果,畢竟這是 IPAdapter 的本意,他的強度會遠高過你的提示詞所描述的內容,進而產生融合的畫面。
所以,我們根據最後一次的 KSampler 輸出結果再做一次,這樣就能獲得比較好的結果,其作法跟 ControlNets 的個別 KSampler 串接起來的動作類似,只是最後輸出時,再做一次而已。
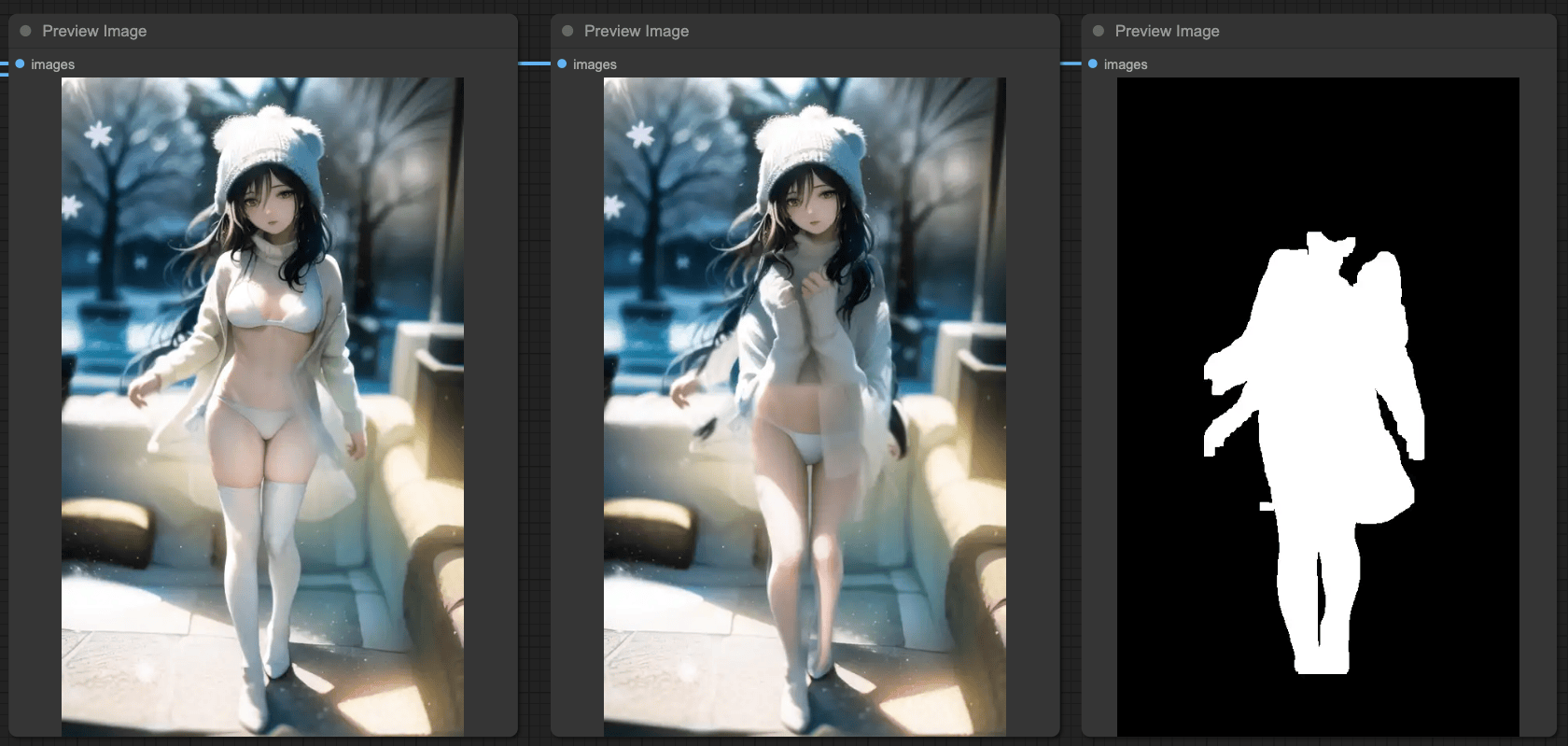
SEGs 與 IPAdapter
IPAdapter 與 Simple Detector 之間其實存在一個問題,由於 IPAdapter 是接入整個 model 來做處理,當你使用 SEGM DETECTOR 的時候,你會偵測到兩組資料,一個是原始輸入的圖片,另一個是 IPAdapter 的參考圖片。
所以,當你想要使用 SEGSDetailer 的時候,你的 BasicPipe 的 model 來源請使用原本的模型來源,如果你接上的是 IPAdapter 的輸出 MODEL 來當作來源的話,最終輸出的處理結果可能不會是你想要的。
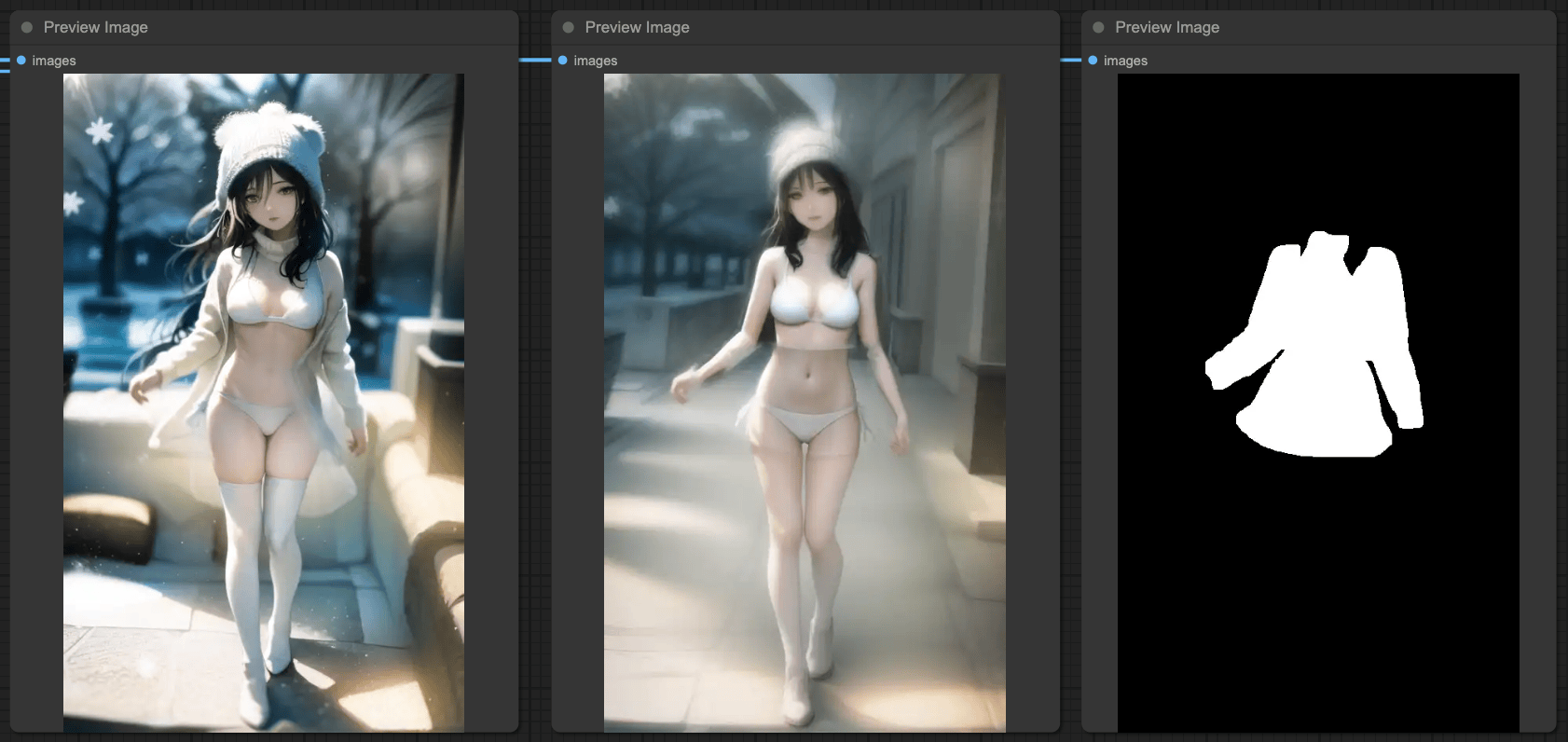
你在這邊會發現 SEGSDetailer 存在一個問題,就是會有 MASK 分塊的明顯色差,這是因為使用了產出結果進行重新繪製的問題,這個情況在單純的去使用 ControlNets 互相連接測試的時候並不會存在。
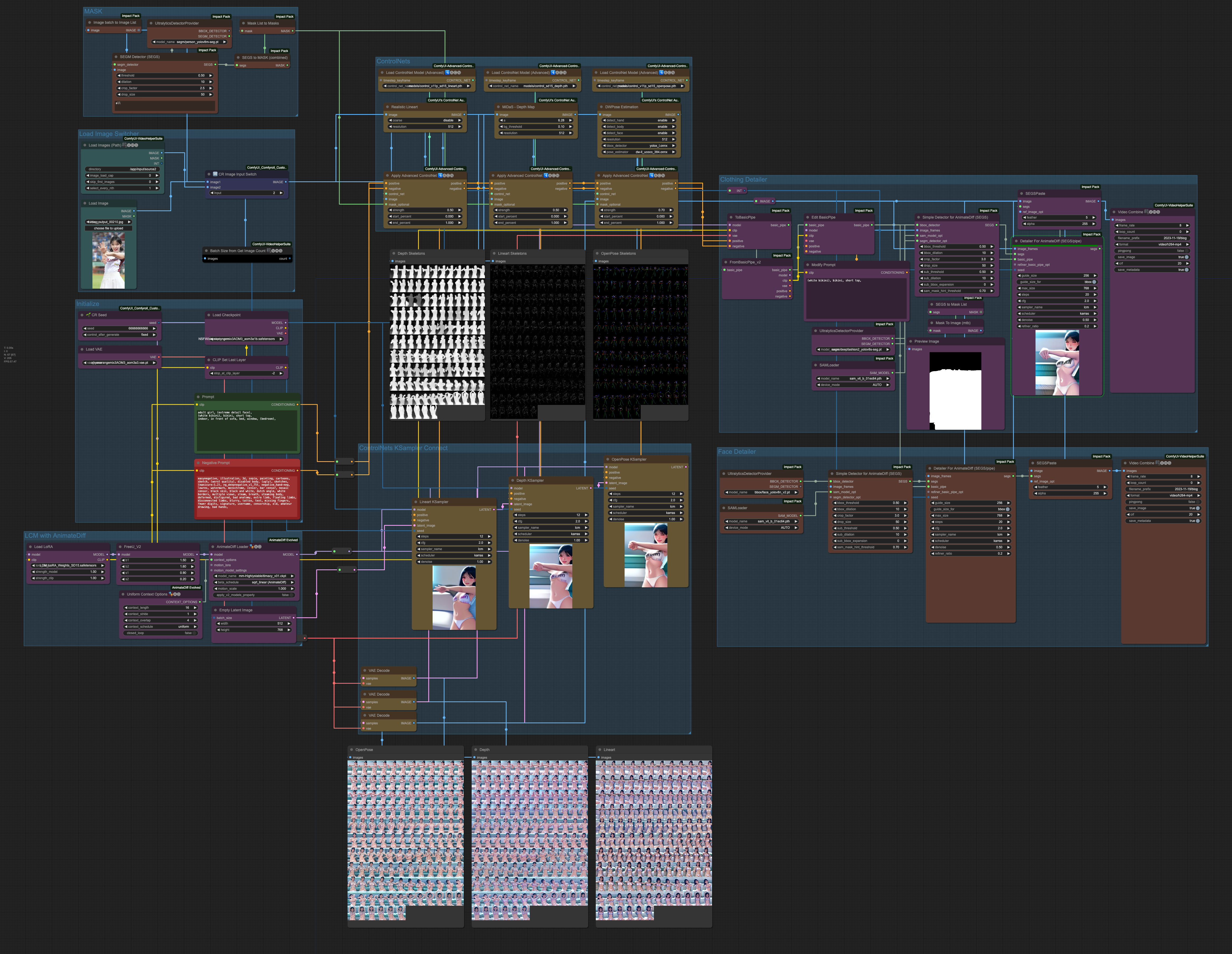
AnimateDiff & ControlNets
最後,整合上面所有的 ControlNets 的操作,我們大概可以期待在 AnimateDiff 的處理上,我們可以做到以下這些效果,
- 服裝、背景穩定性。
- 肢體動作的合理與連續性。
- 臉部表情優化。
在開始這個部分之前,請先確認你的 ComfyUI 關於 ComfyUI Impact Pack 有更新到最新版本,因為我們需要裡面的兩個新的功能。
我在之前的文章 [ComfyUI] IPAdapter + OpenPose + AnimateDiff 穩定影像 當中有提到關於 AnimateDiff 穩定影像的部分,如果有興趣的人可以先去看看。
而在 ComfyUI Impact Pack 更新之後,我們對於臉部修復、服裝控制等行為,可以有新的操作方式。這個方式會比我之前的文章更為有效,在產出速度上也能有所提升。
你可以參考作者所提供的 Workflow 來理解整個流程的製作方式,
作者也提供了一個影片讓大家參考,這個作者的影片都沒聲音,感覺很奇妙,
Detailer for animateDiff
接下來,我們就參考原作者的製作方式,來調整我們的輸出。
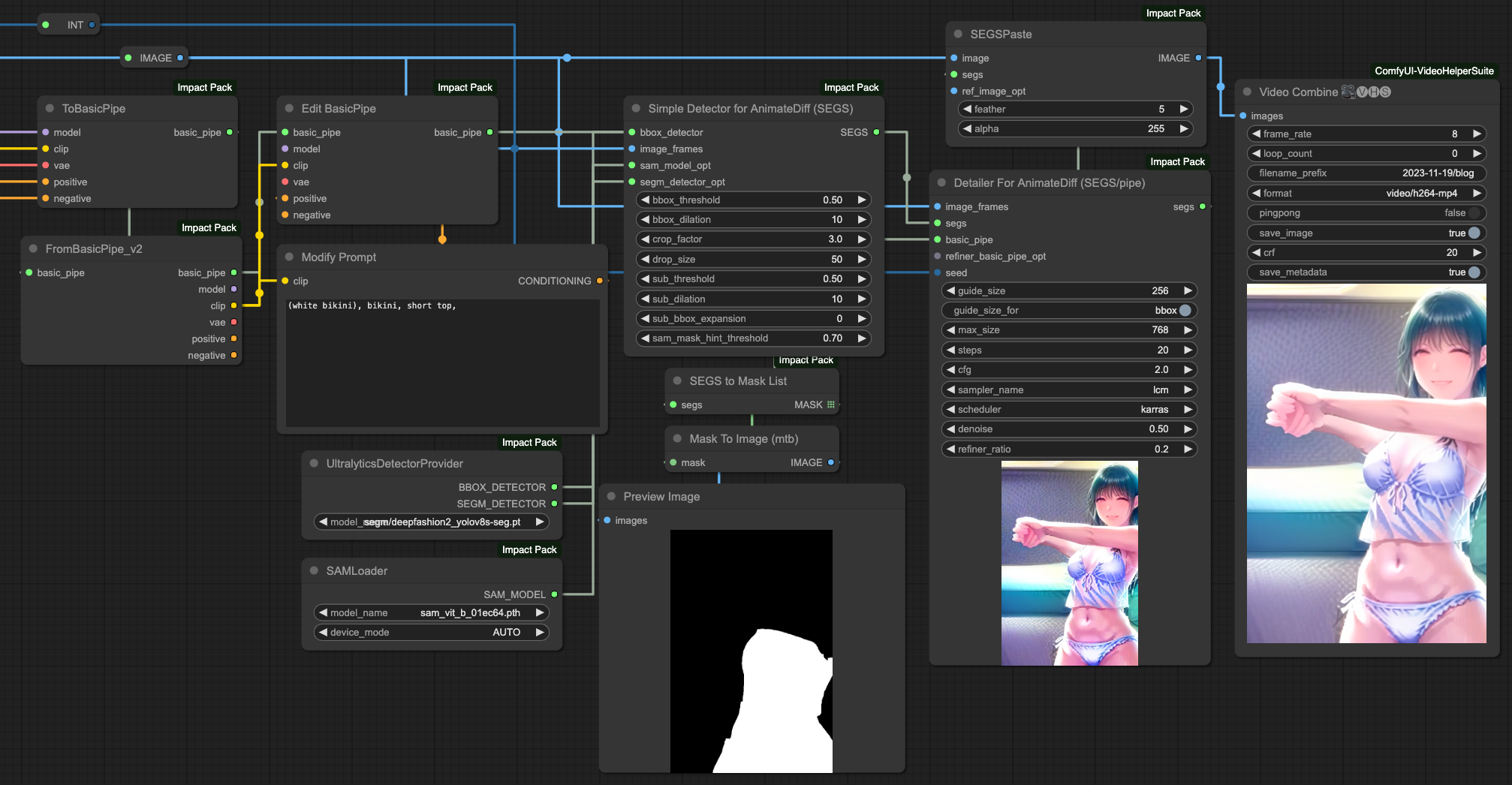
我們這邊僅用服裝的部分來做說明,他對於臉部修復的部分也是有不錯的效果,有興趣的人可以參考上面那個作者的 Workflow 來製作臉部調整的流程。
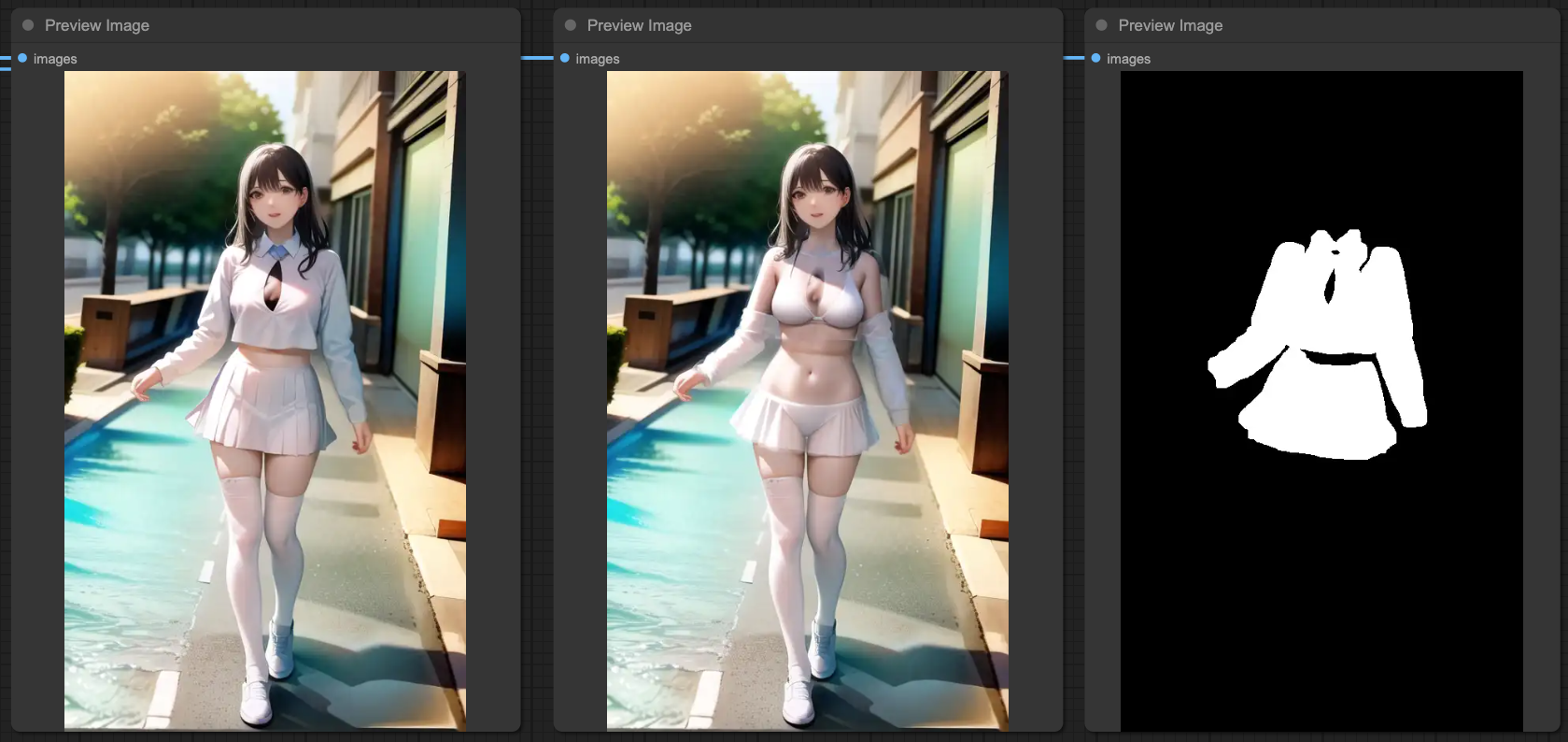
當然,我們的目的是要修改服裝,也就是說不希望更動到其他的部分,根據原作者的作法,他是利用 MASK 的方式將某個區塊做重繪並變更服飾,但因為我們這邊是讀取影格幀數進來處理,所以不可能手動去做這件事情。因此,根據我們文章上半部所提到的 SEGs 的作法,我們利用 deepfashion2_volov8s-seg.pt 模型來做服裝的偵測,並且將 BasicPipe 的提示詞做改寫的動作。
這個操作流程跟臉部修復非常類似,只是我們利用臉部修復的概念來做服裝的控制。
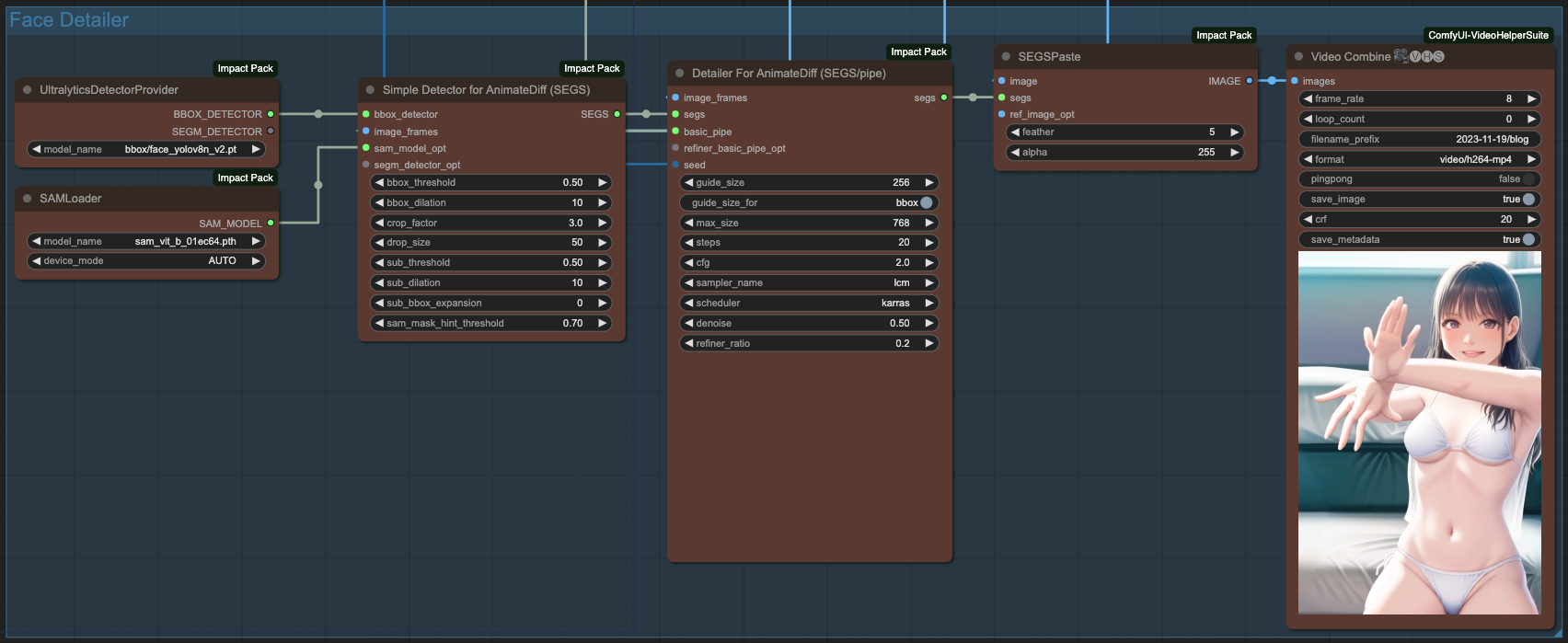
Face Detailer with AnimateDiff
關於臉部修復的部分,我們可以在服裝做完之後,在依照類似的流程來做臉部修復。唯一的差別在於,我們在臉部修復僅需要使用 BBOX DETECTOR 並選擇臉部修復模型即可,以下的範例是使用 bbox/face_yolov8n_v2.pt 這個模型來修復臉部。
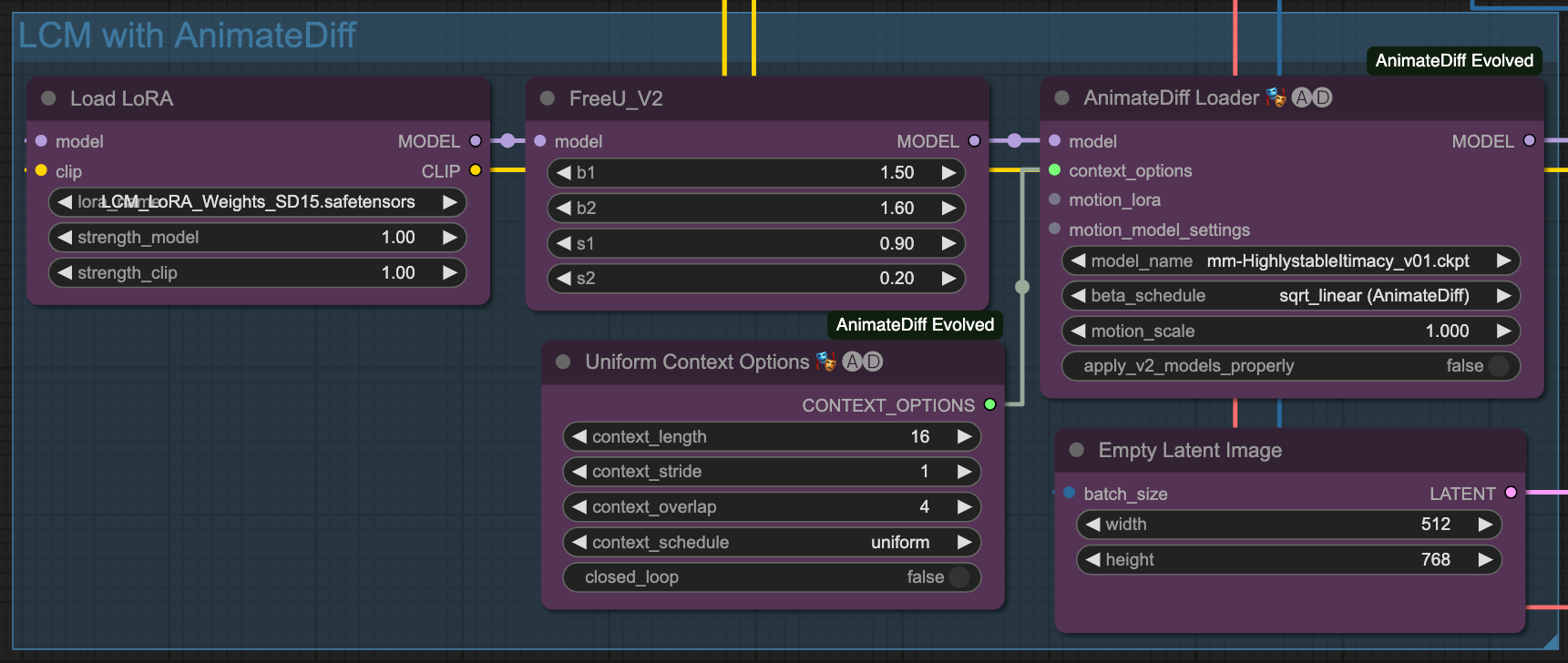
LCM & ComfyUI
本篇文章的所有 KSampler 跟 Detailer 全部都使用 LCM 來做產出。
由於最近 LCM 很紅,而 ComfyUI 在 這個 commit 之後就開始支援原生的 LCM 功能,所以在 ComfyUI 上面使用起來並沒有太困難。
而目前 ComfyUI 也支援了 LCM Sampler 的功能,
我們在 ComfyUI 當中就能搭配 LCM Lora 與 LCM Sampler 來做到快速出圖,
小結
ComfyUI 自由度很高,相對的需要交叉實驗的地方也非常多,我這邊僅只是提供幾個例子讓大家參考,每個人還是得依照自己的需求去調整這個流程。
最後放上這個文章所產出的動畫,
1pass and 2pass Video Sample with LCM
最後的最後,這是這篇文章所使用的完整 Workflow 檔案,若有興趣的人可以自行研究:
https://github.com/hinablue/comfyUI-workflows/blob/main/2023_11_20_blog_workflow.png

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)
{kind=link}
{kind=link}