
![[A1111] AnimateDiff + IPAdapter + OpenPose 操作說明](/content/images/size/w960/2023/11/a1111_cover.jpg)
寫在最前面的,這個操作非常消耗 VRAM,我製作一個簡短的影像時,當載入 ControlNet 計算後,整體的 VRAM 吃掉了 16GB 左右。如果你的 VRAM 不夠的話,建議還是使用 ComfyUI 的方法來製作會比較好。
A1111 with AnimateDiff
這裡的安裝方式跟 ComfyUI 差不多,請先安裝以下的 Extensions,
另外也強烈建議安裝 FreeU,
AnimateDiff 的模型
動作模型與動作 Lora 可以在這邊下載,
另外推薦幾個,可以用來生成動畫的動作模型,
這些模型檔案需要放在這個資料夾裡面,
extensions/sd-webui-animatediff/model
如果是下載動作 Lora,則需要放在這裡,
extensions/sd-webui-animatediff/model/Lora
下載好了之後,如果你有需要用到 ControlNet,請自行把要用到的檔案,放到這裡,
models/ControlNet
當然,你的主模型需要放在 models/Stable-diffusion 裡面。而如果有 VAE 的話,則需要放在 models/VAE 裡面。
AnimateDiff 的介面介紹
全部都安裝完成後,你就會有一個 AnimateDiff 的操作界面,
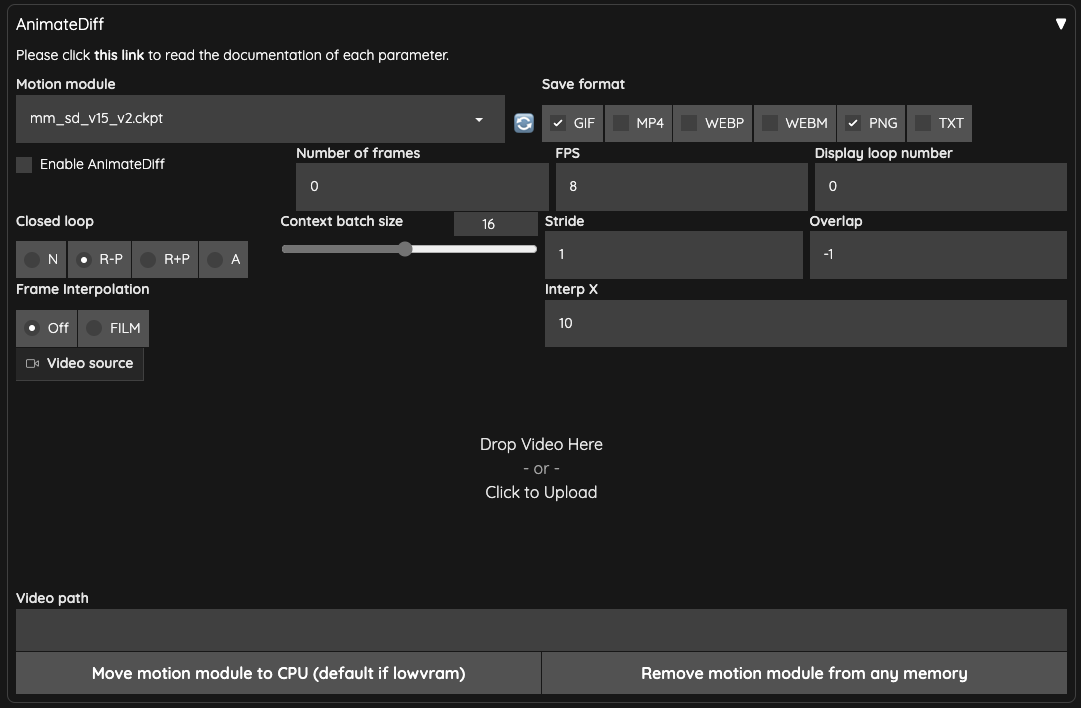
Enable AnimateDiff你要啟動記得勾選。Motion module就是選擇動態模型的地方。Save format儲存輸出的格式,其中TXT是你想儲存文字資訊的話,可以勾選。Number of frames預設使用0,而當你使用Video source或是Video path的時候,他會自動計算然後填入。不然他會依照Context batch size來計算數量。請不要使用跟Context batch size相近的數量,套件作者在 #213 有說明。FPS就是每秒要幾幀。Display loop number如果你選擇輸出是GIF的話,這邊是指要重播幾次,預設0表示連續重播。Context batch size表示 AnimateDiff 要一次處理多少幀數,預設16是不錯的數值。請注意!不同的動作模型會限制這個數字的最大值。Closed loop嘗試著做一個迴圈式的動畫,有四種運算方式,要注意的地方是,當Number of frames小於等於Context batch size時,並不會發生作用。N不使用,當Number of frames(0除外) 小於Context batch size時才有效。R-P會降低迴圈動畫內容(context)的數量,使用 Prompt Travel 的方式並不會做插幀動作(Interpolated)。R+P會降低迴圈動畫內容(context)的數量,使用 Prompt Travel 的方式來做插幀動作(Interpolated)。A將最開頭的幀數接入最後幀數後面做迴圈式動畫,使用 Prompt Travel 的方式來做插幀動作(Interpolated)。
Stride這件事情很難說明,主要的目的是用於確保 AnimateDiff 在幀與幀之間能盡量保持時間同步,預設使用1。具體可以參考原作者說明 WebUI Parameters。與 ComfyUI 相同的地方是,這個設定在 vid2vid 似乎是沒有效果的。Overlap每一次 AnimateDiff 處理圖片時,要預留多少數量的圖片來做為上下內容的重疊,預設-1,他會使用Context batch size / 4的數量。這個設定只有Number of frames大於Context batch size或是Number of frames為0時才會有效。Frame Interpolation預設OFF,若是使用FILM則在 AnimateDiff 處理完後,會使用 Deforum 做影片補幀的操作。Interp X當使用Frame Interpolation = FILM時,取用 X 數量的輸出補幀幀數來補入輸入幀數。他會將整個影片拉長,你必需要輸出之後再將影片作加速處理。Video Source這邊可以上傳影片。Video Path如果沒有影片上傳,這邊可以輸入影片的路徑,你需要把影片拆成幀數的圖片放在這裡。Move motion module to CPU (default if lowvram)低 VRAM 的情況下,把模型挪去系統的記憶體。Remove motion module from any memory移除任何記憶體中的動態模型。
我們上傳了影片之後,上面的一些參數就會自動被帶入,
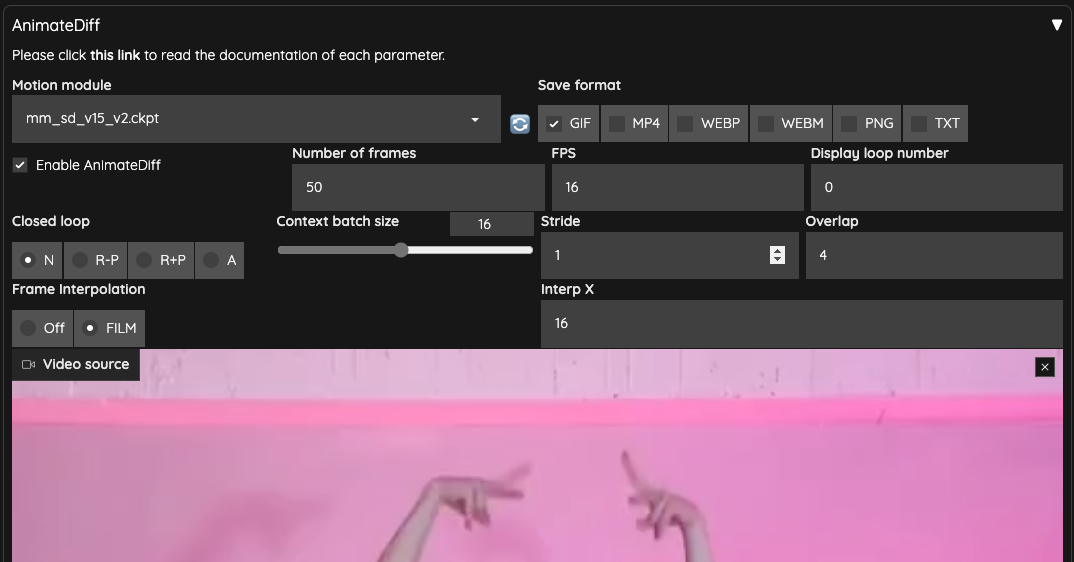
ControlNet
接著,我們要準備兩個 ControlNet 來使用,
- OpenPose
- IPAdapter
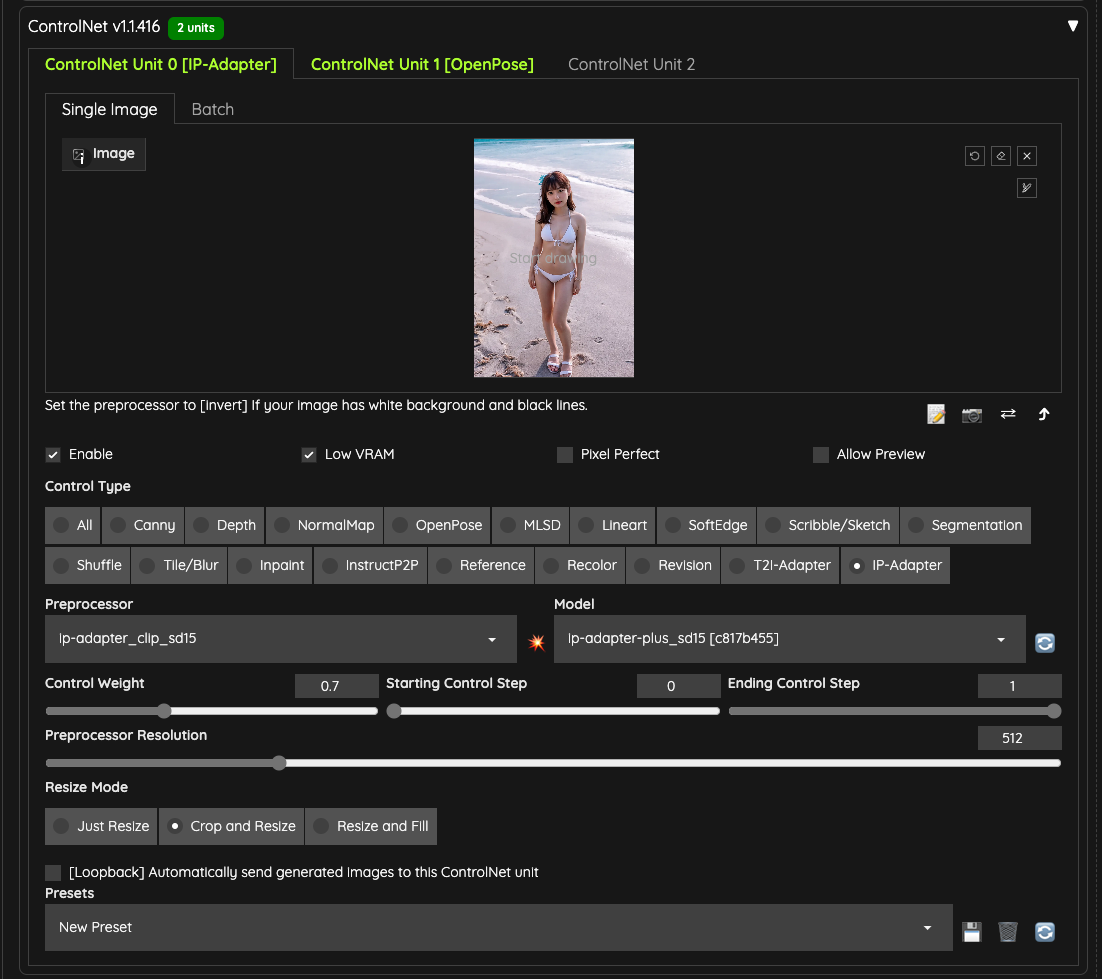
我這邊使用 IPAdapter,並且選擇了 ip-adapter-plus_sd15 這個模型,並且把權重設定在 0.7 避免過高的權重干擾輸出。
另外,我準備了跟上傳的影片相同數量的 OpenPose 骨架圖,並且放在 /output/openpose 資料夾裡面,讓這個 ControlNet 可以讀取。
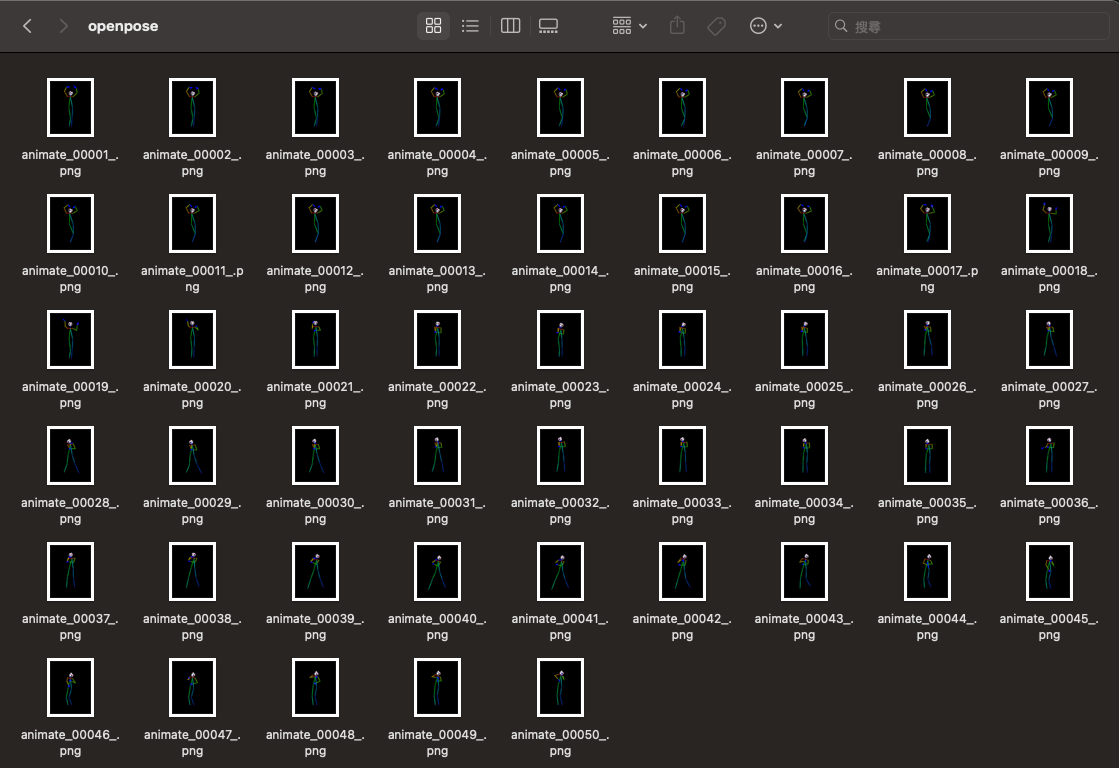
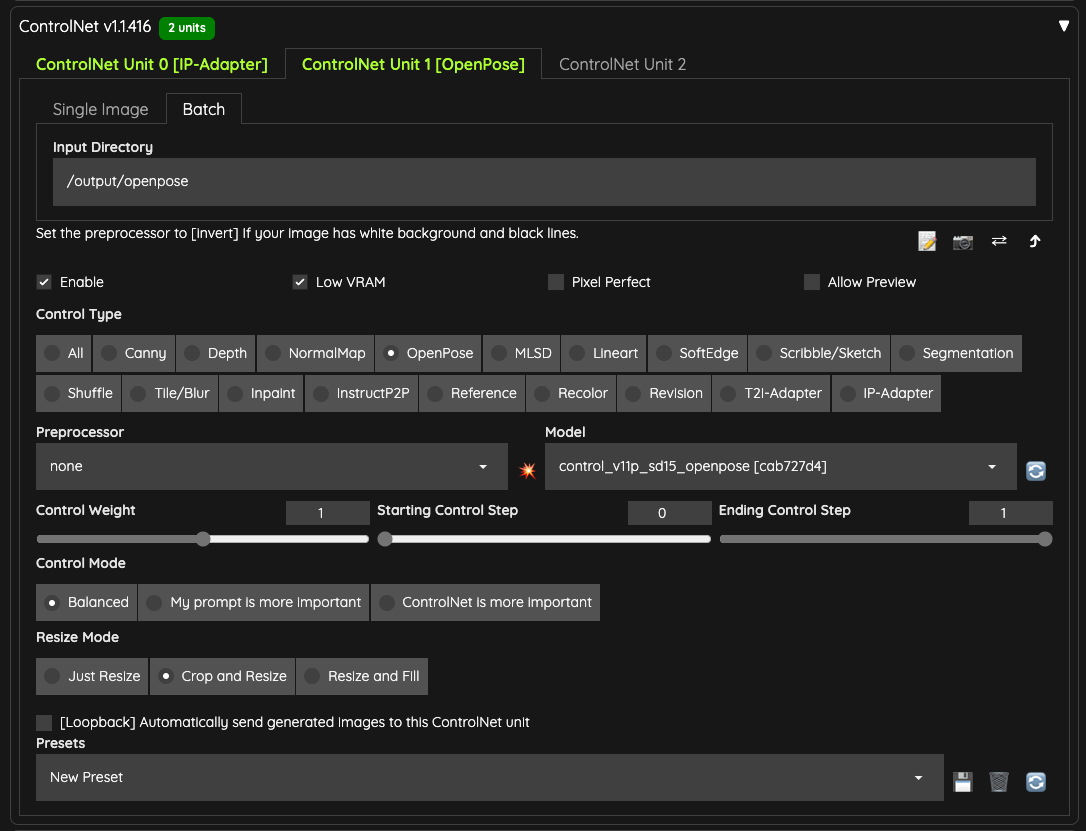
如果你沒有工具可以輸出骨架圖,那麼你可以使用 ControlNet 的預處理器( preprocessor)來幫你完成。但是,前提是你還是必須要把影片的幀數全部匯出成圖片。
你可以使用諸如 FFmpeg 等工具,將影片的所有幀數匯出成圖片,再把它放到 Batch 的輸入資料夾內,接著使用 DWPose 或 OpenPose 相關的預處理器來處理。
我在這邊直接使用骨架圖只是想省一點 VRAM 跟省一點時間,畢竟預處理也是要花一段時間的。
文生圖設定
請留意一下 Batch sizes,這邊稍微解釋一下,
- A1111 與 ComfyUI 不同的地方在於,ComfyUI 是整個流程算一次
Batch Counts,所以,在 ComfyUI 需要把Batch sizes設定成與讀入的幀數數量相同,這樣動畫才不會出現不流暢的狀況。 - 在 A1111 會根據 AnimateDiff 外掛讀取到的
Number of frames,與你所準備的 ControlNet OpenPose 的來源,以本文章為例,你會有50個繪圖的步驟。 - 如果你的
Batch sizes/Batch Counts都設定為1,則表示全部的 T2I 只會做50次。 - 以本文章後續的影片為例,
Batch sizes設定為4,表示 T2I 的過程中,會產生50 x 4 = 200,總共200張圖片。 由於 AnimateDiff 針對 i2ibatch 做了修改,所以在影像處理的部分,AnimateDiff 會拿這200張圖片去做運算(實際是否如此操作需要詳細察看原始碼,目前僅是我個人推測)。- 根據官方 Github 寫明,目前修改
Batch Sizes並無效果,未來或許會支援,官方說法:
You do not need to change batch size at all when you are using this extension.
We are currently developing approach to support batch size on WebUI in the near future.
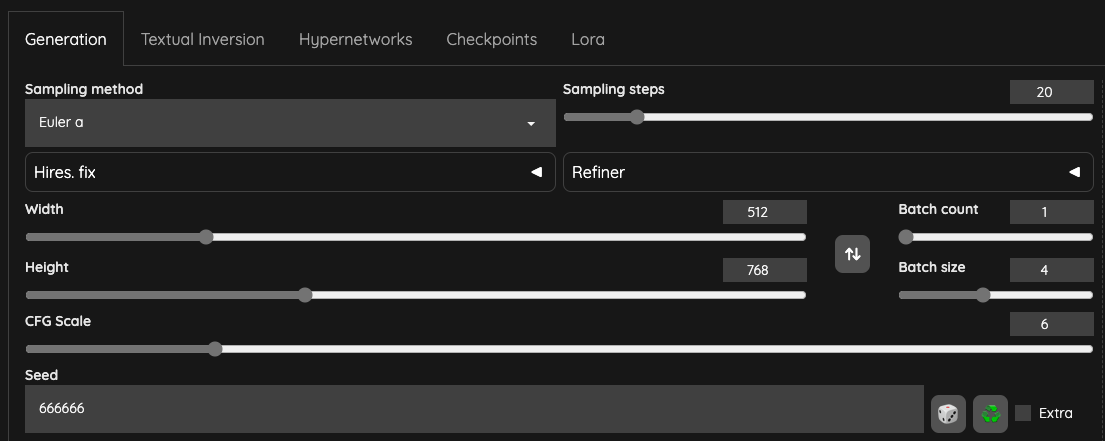
Seed 的設定請保持一個固定值,因為你不會想要輸出完全不同風格的圖片。
ADetailer
最後我們用 ADetailer 來修復臉部,
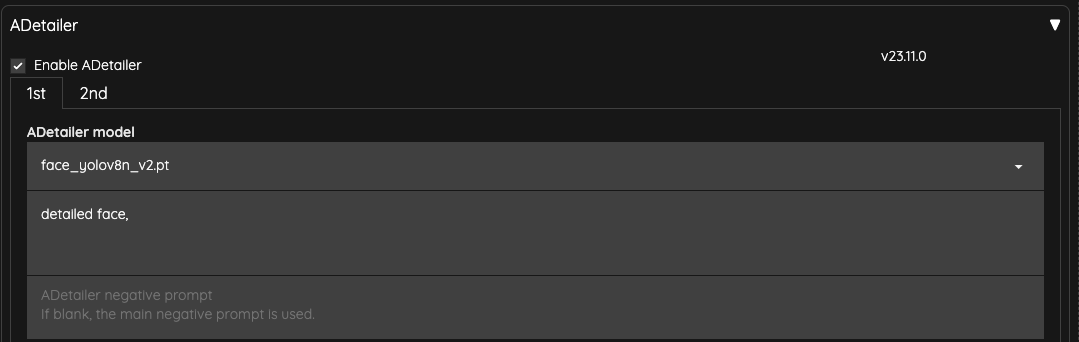
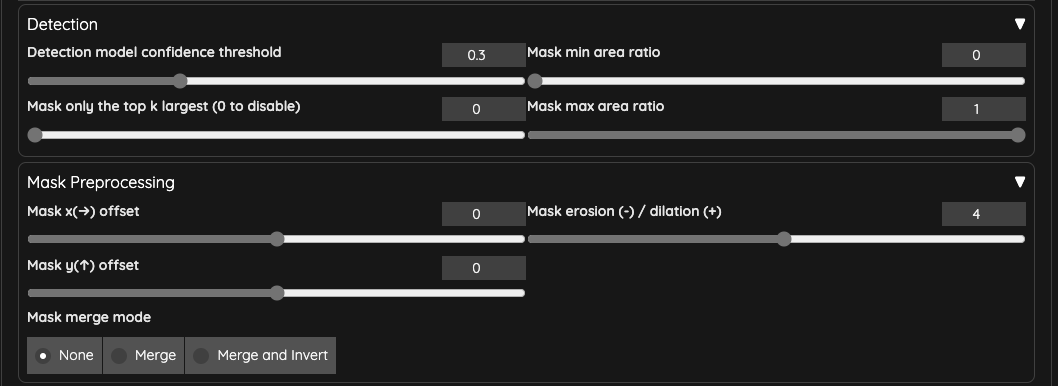
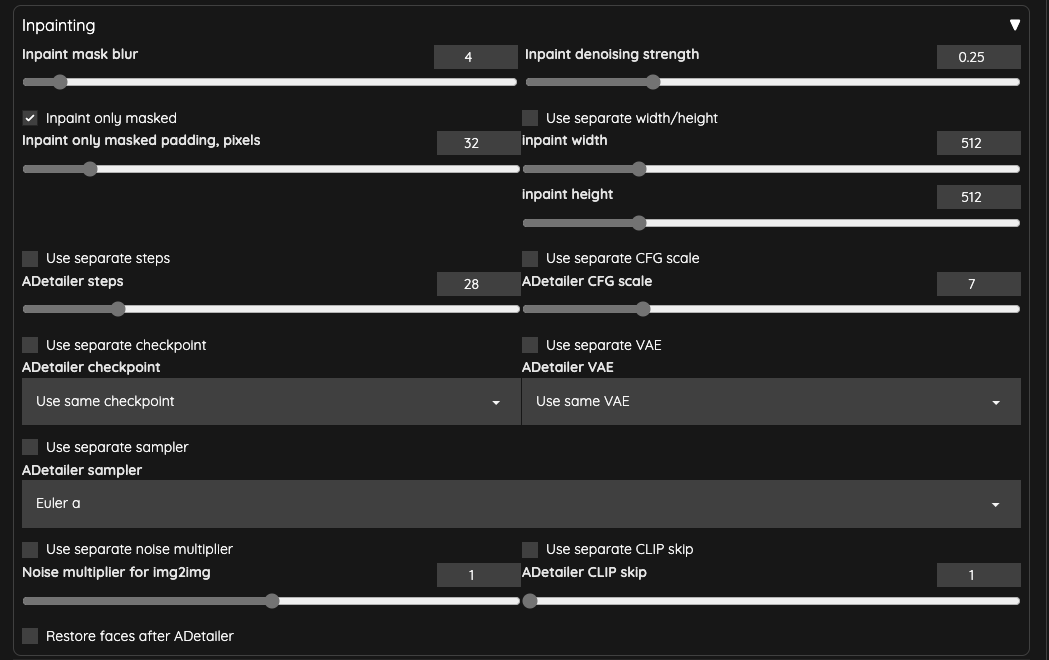
我把 ADetailer 的 Inpaint denosing strength 降低成 0.25 用以確保臉部不要過度重繪造成閃爍問題。
生成
提示詞的部分,因為我們有使用 IPAdapter,所以可以把 IPAdapter 那張圖片,丟去給 PNGInfo 來獲得我們的提示詞,接著再針對提示詞做修調就可以了。
最後,我們來看看輸出結果,
比較三種輸出方式的差異
這三個影片已經另外處理過,輸出的 FPS 是使用 16FPS,其餘不同的輸出設定如下,
Frame Interpolation = NO,Batch Size = 1Frame Interpolation = FILM,Batch Size = 4Frame Interpolation = FILM,Batch Size = 4,Stride = 4
你會發現,當使用比較高的 Batch Size 時,動畫整體的流暢度會明顯的變好。
Batch Size
當你不是使用 vid2vid,而是直接使用文字輸出成 GIF 時,你的 Batch Size 將會決定 GIF 的話面數量(而不是 Batch Counts),這一點在作者 Batch Size 的部分也有說明。
而倘若你是使用 ControlV2V 的話,那麼適度的提高一點 Batch Size 會帶來不錯的效果,你可以多嘗試看看。
Frame Interpolation = FILM / Intrp X
當有開啟 Frame Interpolation = FILM 的時候,以本篇文章的資料來說,我使用了 Interp X = 10 這個預設值。而原始影片所讀取的 Number of frames 為 50,最後,我們產出的 GIF 檔案,裡面共有 491 個畫面。
換句話說,啟用後我們原始影片的每一個幀數,都被補了約 10 個畫面進去,所以,最終輸出的 GIF 檔案就會變成一個慢動作影片。
實際程式碼操作是這樣,
film_in_between_frames_count = calculate_frames_to_add(len(frame_list), params.interp_x)
所以,原始的影片約 3.2 秒,在這個補幀的動作結束後,大概被拉長成 30.2 秒的影片,你勢必要使用其他的工具,將整個影片長度縮短回原始的長度。
如果你有安裝 FFmpeg 的話,你可以使用 setpts 來加快影片速度。以本篇文章的影片為例,這樣就能縮短到與原本的影片相同的速度,
ffmpeg -i input.mp4 -filter:v "setpts=0.1*PTS" output.mp4
額外設定
如果你使用 --xformers 卻發生問題,可以調整 AnimateDiff 的設定,改用 sdp 或許可以解決。

另外一點,因為是使用 vid2vid 搭配 t2i 的運作方式,所以若是在產生圖片上有問題,打開這個設定或許可以解決,同時他也會帶來一點效能上的優化。

小結
A1111 的 AnimateDiff 與 ComfyUI 的操作其實沒有太大的不同,唯一不同的地方是 A1111 都把中間需要做串連的地方打包好了,可以省下一點時間。
如果真的 VRAM 很吃緊的朋友們,還是轉用 ComfyUI 會好一點,不然就是每次製作影片的長度(總幀數)降低,然後最後再利用影片編輯軟體把檔案串起來。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)