
![[Lora] 訓練與大型翻車現場](/content/images/size/w960/2023/05/00016-082b0987-1.png)
說在最前面,這裡就是一堆訓練翻車現場,不用期待有什麼美女圖之類的。每天晚上花時間查文件、紀錄、測試小型模型,然後持續翻車。畢竟設備只有一組,說實在的如果用 Amazon Segamaker 可能可以省一點時間,其實就是花錢買時間,但是如果連續買到 12 次都翻車,那其實也蠻浪費錢的。
人帶賽的時候真的不能跑訓練。
訓練環境
首先,我基本上還是使用 Kohya 的圖形介面來設定參數,
當然我也把他包成容器了,所以我在 [Docker] Kohya_ss GUI 設定 提到的已經被我棄用,直接使用自己封裝的省去一些套件相依性的問題也是不錯。
參數記錄
首先是 第一篇記錄 提到過的訓練集與正規化圖片(REGULARIZATION IMAGES)的準備。原本我天真的以為訓練集的圖片我可以提供一大堆高品質的照片,另外正規化圖片(REGULARIZATION IMAGES)就以訓練集的相關圖片去延伸。
但是,這就是一個翻車的開始。
Train
+ 100_ai-caline girl
- 約 40 張圖片
+ 10_ai-caline girl portrait
- 約 200 張圖片
+ 5_ai-caline girl full body
- 約 1000 張圖片
Reg
+ 5_girl
- 約 500 張圖片
+ 1_portrait
- 約 2000 張圖片
+ 1_full body
- 約 4000 張圖片
根據民間的不成文規則,正規化圖片(REGULARIZATION IMAGES)的數量,大約可以在訓練集圖片的 100 ~ 200 倍之間。但其實我沒有準備這麼多正規化圖片(REGULARIZATION IMAGES),所以你會看到 Reg 的部分有的遠小於那個倍數數量。
接著根據 上一次訓練失敗 的紀錄,又把一些參數給約略調整一下。
最終的結果就是連續翻車 12 次以上。
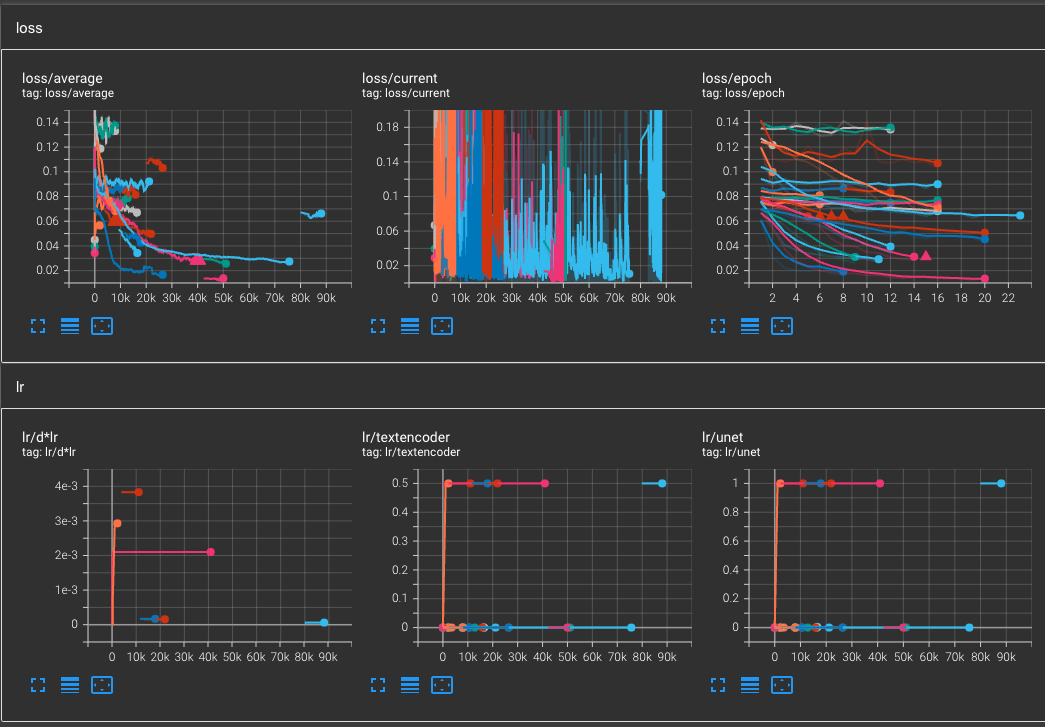
訓練集
首先,訓練集當中所謂的品質,主要是你的精細度要夠,即便我們提供的是 768x768 的圖片,但最好你的圖片來源還是比較清晰的大圖,正所謂 縮圖無爛圖,所以訓練集的重點在於圖面的精細度要夠高。
後來我調整 砍掉重練 訓練集的圖片,讓他縮減到只有約 45 張上下,每一張照片的基本規則如下:
- 取
2000x2000以上的原始圖檔,縮小到768x768的尺寸。 - 盡量選擇單純背景,其實不需要去背或是霧化背景。
- 訓練人臉,盡可能整張臉都出現,側面不要太多,然後 請包含完整的頭部到肩頸。
- 可以有半身或全身,但 不要太多,最多約總圖片數量的
5% ~ 10%左右。
提示詞的部分,需要留意的地方有,
- 請描述表情,或是妝容(例如假睫毛)。
- 臉部或耳朵有任何配件,請一定要描述它(例如耳環)。
- 頭髮若有髮飾,請一定要描述它(例如髮夾)。
- 頸部若有遮蔽物,請一定要描述它(例如圍巾)。
- 眼睛看哪裡可以描述,BLIP 或 deepbooru 偶爾會出現
take a cell phone之類的,他認為你的角色在看手機(或自拍動作),如果你畫面上真的有就可以保留,沒有的話請刪除它。 - 背景若有人物、較為複雜,請約略描述。
接著依照你想要的步數去計算約略的重複次數(Repeats),我懶得算直接用 50。
Train
+ 50_ai-caline
- 0000-01-1.png
- 0000-01-1.txt
- ... 共 45 張
接著,當你準備好提示詞之後,接著我們需要準備正規化圖片(REGULARIZATION IMAGES)。
正規化圖片(REGULARIZATION IMAGES)
市面上所謂的 100 ~ 200 倍於訓練集的數量,多數是使用 Dreambooth 的某些經驗法則(?),至於是不是真的要用到那麼大的數量?我實際測試過,最高以 20 張圖片,200 倍的正規化圖片(REGULARIZATION IMAGES)來看,基本上該翻車的地方還是會翻車。這邊的圖片準備,數量上確實要有一定的量,但是還是有幾個小地方需要留意。
- 請準備跟「訓練集」同類但不正相關的圖片。
- 請準備跟「訓練集」同類但不正相關的圖片。
- 請準備跟「訓練集」同類但不正相關的圖片。
何謂 『同類但不正相關』?假設你今天要訓練的是新垣結衣好了,那你所準備的訓練集就會是許多新垣結衣的照片。那麼,正規化圖片(REGULARIZATION IMAGES)則需要準備:
- 女生 但是不可以完全都是新垣結衣 的圖片。
- 可以是類似的肢體服裝,但不能完全一樣。
為什麼不能一樣?這個我後面一點會提到。
另外,由於新垣結衣是名人,而你所使用的訓練模型 或許 會認識 Yui Aragaki,所以在訓練集的提示詞中,若是大量提及 Yui Aragaki 可能會受到原始模型的污染。
在絕大多數的教學或是文章裡面,會告訴你使用 SD 的 Prompt 去產生正規化圖片(REGULARIZATION IMAGES),這是一個不錯的作法。市面上也有一些 Dataset 是使用這樣的方式去產生出大量的正規化圖片(REGULARIZATION IMAGES)來當作參考資料集。所以,在你準備好「訓練集」的同時,你就可以使用訓練集當中所做好的提示詞,用 SD 幫你大量產出正規化圖片(REGULARIZATION IMAGES)。
但是!
請確保你的正規化圖片(REGULARIZATION IMAGES)的內容有達到他的目的。
我在 [AIGC] Stable Diffusion with Lora 訓練記錄 有提到正規化圖片(REGULARIZATION IMAGES)的用意,我在這邊就不贅述。
翻車的 loss/epoch
loss 也沒有說越低越好,只要有約略在震盪收縮就可以了。
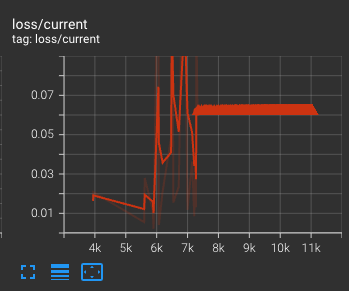
會出現這種狀況主要有幾個方向可以查,
- 學習率過大。
- 梯度過大。
- 無法收斂。
- 髒數據。
通常來說,如果你依照市面上的教學來設定,基本上不太會遇到 1, 2, 3 這幾種狀況,所以最有可能的地方就是 4,也就是說,你所提供的不管是訓練集也好,正規化圖片(REGULARIZATION IMAGES)也好,就是資料有鬼所以把 loss 搞到爆炸。
請注意,loss=nan 並不會停止你的訓練,只是你訓練出來的模型都會是壞的。
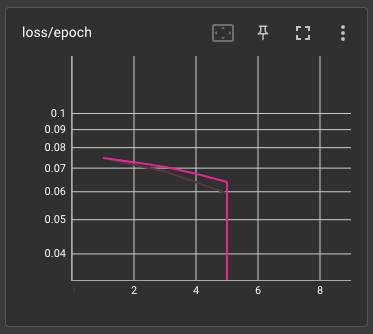
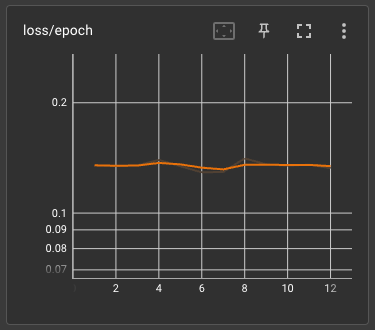
如果你像我一樣實驗性質的跑了很多演算法、各種學習率,那麼你可能就會遇到上面的那些狀況。最主要的還是說,市面上的作法並沒有告訴你訓練集跟正規化圖片(REGULARIZATION IMAGES)到底準備的數量,跟適合的學習次數等等。
所以,學習成效不佳好像也是很合理的事情。
翻車的 Epoch 與 Train batch size
大家都說 Train batch size 設定成 1 可以比較節省 VRAM,是的!沒錯。但是,相對的就必需要花更多的時間來讓訓練的結果擬合。換句話說,當你的資料集很大(包含你的正規化圖片(REGULARIZATION IMAGES))的時候,你的訓練輪次(Epoch)就不是什麼 12 次或 20 次這樣的數字了。換句話說,市面上所謂的訓練次數的甜蜜點,在資料量級不同的情況下,基本上都無法一體適用。
所以當我天真的以為增加 Epoch 開到 24 總會學到一點東西,但事實上,

所以,經過多次測試的結果,其實 Train batch size 可以的話,維持在 2 以上會是比較好的選擇。至於 Epoch 的數量大概是 8 ~ 16 之間。
而上次所提及的 Gradient accumulate steps 則可使用 1 或 2,更高的數字對學習來說並沒有太大的影響,畢竟訓練集的資料相對少很多,所以梯度累加這件事情在這邊看不出多大的幫助。
當然,若你的機器允許,在 Train batch size 可以使用 4 會更好。這個數字大一些對於後續產出的模型相對穩定度會比較高一點。
翻車的優化器 Optimizer 與學習率
首先,優化器(Optimizer)的部分最優先的還是使用 AdamW8bit,至於 DAdaptation 有人說訓練二次元效果不錯,這個我就沒有著墨。我也有嘗試拿 DAdaptation 來訓練真人模型,至於結果如何就算了這樣。

學習率的部分,市面上的通用數據還是可以使用的,大抵上可以看 這一篇文章 關於 Learning Rates 的介紹。
訓練設定參考
我這邊所實驗出來的結果列出來給大家做一個參考,
Train
+ 45 張圖片
Reg
+ 4200 張圖片
- 優化器(Optimizer)使用
AdamW8bit Train batch size用4或2Epoch用12Learning rate與Unet learning rate使用0.0002Text Encoder learning rate使用5e-5LR Scheduler使用cosine_with_restartsNetwork Rank (Dimension)使用128Network Alpha使用1Gradient accumulate steps使用1Prior loss weight使用0.15Noise offset使用0.06
就結果論來說,其實已經相當接近,

如果利用 Additional Network 針對 UNet/TEnc 權重調整,搭配我最初的訓練模型,其實產出的結果也是相當不錯。

小結
人帶賽真的不要訓練模型。

![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)
![[SD3.5] Quickstart - Lora Training with Kohya](/content/images/size/w960/2024/11/ComfyUI_temp_pffyu_00017_.jpg)
![[Flux] Lora 從訓練到放棄](/content/images/size/w960/2024/09/00057-3368661048.png)