
![[Lora] Google Colab 訓練筆記](/content/images/size/w960/2023/05/00065-b3f7709b.png)
雖然本地端可以訓練,不過這個年頭好像不上雲就不夠潮,所以就去找了一個相對簡單的 ipynb 來試著跑跑看。然後前些日子因為 Google Colab 被大家拿來跑 Stable Diffusion 搞得有點頭大(畢竟他是免費),所以最近對於單純跑 SD 這件事情好像開始有了限制。
最近在 reddit 上面有不少相關的討論。
Google Colab with Lora
Google Colab 其實本來是用來給機器學習目的(或是拿來學習 Python, jupyter notebook)用的免費工具,但因為近兩年 Stable Diffusion 越來越流行,然後市面上就開始有一堆「工具」來讓你把 SD 跑在 Colab 上面。
當然,基於學術研究,所以我也去找了幾個 Kohya Lora 訓練的工具,雖然有超多工具可以挑,不過目前我還是以最簡單的(或是我改得動的)部分來挑選,所以,我目前是從這個作者的 Github fork 出來修改成自己的版本。
因為他的目的相當單純,就是專注在跑訓練這件事情,什麼準備資料或是提詞工具的他都沒有。如果說你要比較多功能,然後比較熱門的選項,那這個你可以參考,
不過,我實在很懶得看那麼多原始碼,而且其實我不會寫 Python(遮臉)。
原始碼調整
以下的調整都是基於 hollowstrawberry/kohya-colab 修改而來,我撰寫這篇文章的時候,當下的 main branch SHA 是 ef8fcb8f4c3e43e0752bc995953ea2178bfda7d0,這一點請稍微留意一下。
由於他的訓練工具是基於 kohya-ss/sd-scripts 而來,所以我調整了一下抓取的 SHA,
COMMIT = "5050971ac687dca70ba0486a583d283e8ae324e2"
// Change to
COMMIT = "v0.6.3"
原作者的 requirements.txt 當中,我換了 xformers 套件版本,所以把這個換成我自己的,
!wget https://raw.githubusercontent.com/hollowstrawberry/kohya-colab/main/requirements.txt -q -O requirements.txt
// Change to
!wget https://raw.githubusercontent.com/hinablue/kohya-colab/main/requirements.txt -q -O requirements.txt
然後,如果你的訓練步數會超過 10,000 步的話,會被他強制中斷,我把他稍微放寬一點點,
if total_steps > 10000:
// Change to
if total_steps > 12000:
接著關於 training_arguments 的部分,由於有些東西是固定的,所以這邊你可以調整成你想要的設定,由於我是訓練真人模型,所以我把他替換掉了,
"noise_offset": None,
"clip_skip": 2,
// Change to
"noise_offset": 0.03,
"clip_skip": "None",
最後是關於 Prior loss weight 的部分,這邊他寫死了,所以如果你有正規化圖片(REGULARIZATION IMAGES)的資料,這邊就自己斟酌要取多少的數字,
"dreambooth_arguments": {
"prior_loss_weight": 1.0,
},
// Change to
"dreambooth_arguments": {
"prior_loss_weight": 0.15,
},
以上大概就是對於設定小小調整的部分。
資料集設定
預設資料集可以使用,但由於我有不少自訂設定,加上我還有正規化圖片(REGULARIZATION IMAGES)的設定,所以,在這個工具中要使用 Multiple folders in dataset 來設定更多的資料,
以下是簡易的設定,有需要的人可以參考,
#@title
custom_dataset = """
[[datasets]]
bucket_no_upscale = true
color_aug = false
caption_dropout_every_n_epochs = 0
caption_dropout_rate = 0
face_crop_aug_range = [2.0, 4.0]
random_crop = false
token_warmup_min = 1
token_warmup_step = 0
[[datasets.subsets]]
image_dir = "/content/drive/MyDrive/Loras/dataset"
num_repeats = 30
is_reg = false
class_tokens = "ai-hina"
[[datasets.subsets]]
image_dir = "/content/drive/MyDrive/Loras/reg/ai-hina"
num_repeats = 1
is_reg = true
class_tokens = "ai-hina"
"""
這邊的 toml 設定資料有哪些東西可以用,可以參考 kohya-ss/sd-scripts 說明(日文) 有蠻詳細的說明。
至於訓練集與正規化圖片(REGULARIZATION IMAGES)的準備這邊就不贅述了。另外,這個工具本身有提供一個 Unzip dataset 的功能,就是你把圖片做成壓縮檔,放到你的 Google Drive 之後,可以用這個東西來解壓縮,可以加速你圖片上傳的速度,不然我的訓練集(REGULARIZATION IMAGES)有 5000 多張圖片,上傳會死人的。
訓練
然後建議你去訂閱 Colab Pro 或是 Pay As You Go 購買運算單元,這樣會拿到比較好一點的算力的機器(應該)。
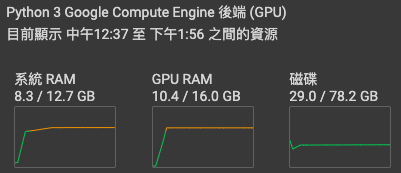
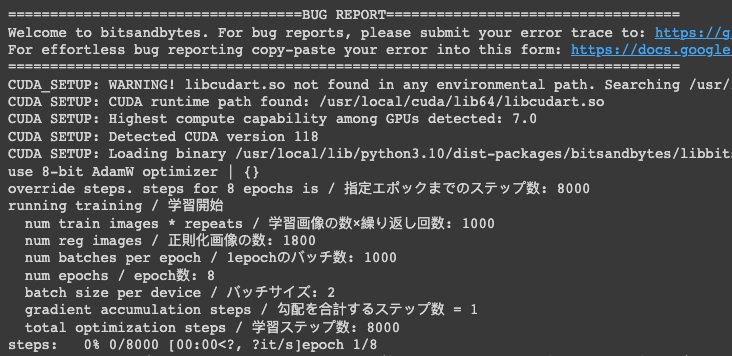
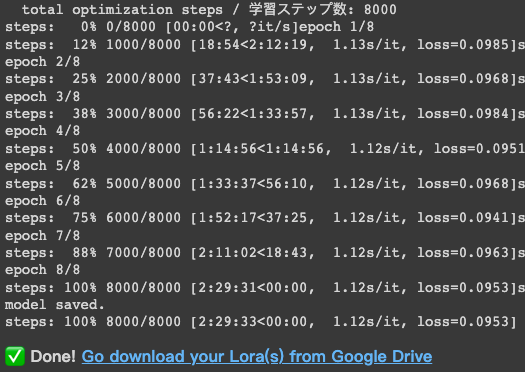
唯一的好處大概就是不太需要擔心 OOM 的問題,當然,如果你把 Total batch size 搞得很大,或是訓練超過 768x768 的解析度(沒啥卵用,請不要這樣做),他還是會有 OOM 的疑慮就是了。
如果你有訂閱到 Colab Pro+ 的等級的話,基本上可以讓他在背景跑。如果不是的話,在官方 FAQ 有提到這件事情,
Where is my code executed? What happens to my execution state if I close the browser window?
Code is executed in a virtual machine dedicated to your account. Virtual machines are recycled when idle for a while, and have a maximum lifetime enforced by the system.
根據外國的鄉民實測的結果大概是,
- 最大存活時間是 12 小時(瀏覽器沒有進入閒置)。
- 當 Colab Notebook 閒置超過 90 分鐘後,會強置中斷。
這個條件是不是適用 Colab Pro 我不清楚,畢竟我不會把瀏覽器頁面開著超過 12 小時。而且,最近 Google Chrome 對於閒置分頁的處理(為了省記憶體),會不會造成 Colab Notebook 出現閒置(Idle)狀況,這個可能得有人去實驗才知道。
訓練參數與結果
這次的訓練參數約略如下,
{
ss_clip_skip: "2",
ss_num_train_images: "1000",
ss_cache_latents: "True",
ss_caption_dropout_every_n_epochs: "0",
ss_caption_dropout_rate: "0.0",
ss_caption_tag_dropout_rate: "0.0",
ss_epoch: "8",
ss_face_crop_aug_range: "None",
ss_full_fp16: "False",
ss_gradient_accumulation_steps: "1",
ss_gradient_checkpointing: "False",
ss_learning_rate: "0.0002",
ss_lowram: "True",
ss_lr_scheduler: "cosine_with_restarts",
ss_max_grad_norm: "1.0",
ss_max_token_length: "225",
ss_max_train_steps: "8000",
ss_min_snr_gamma: "5.0",
ss_mixed_precision: "fp16",
ss_network_alpha: "1",
ss_network_dim: "128",
ss_network_module: "networks.lora",
ss_noise_offset: "None",
ss_num_batches_per_epoch: "1000",
ss_num_epochs: "8",
ss_num_reg_images: "1800",
ss_optimizer: "bitsandbytes.optim.adamw.AdamW8bit",
ss_output_name: "hinaCalineHires",
ss_prior_loss_weight: "1.0",
ss_seed: "42",
ss_session_id: "2926869630",
ss_steps: "8000",
ss_text_encoder_lr: "5e-05",
ss_unet_lr: "0.0002",
ss_v2: "False"
}
眼尖的人大概會看到 Prior loss weight 我是設定 1,對,這樣的產出就是完全參考正規化圖片(REGULARIZATION IMAGES)的結果。

所以當你有正規化圖片(REGULARIZATION IMAGES)的時候,請注意你的 Prior loss weight 是不是設定在合理範圍。
具體可以參考 這邊關於 Prior loss weight 的解釋,我幫大家把他節錄過來,
- Prior Weight Loss = 1.0 (probably too high, stuff will mostly look like your class images)
- Prior Weight Loss = 0.01 (too low, class images will be ignored)
- Prior Weight Loss = 0.15 - 0.4 (this is typically the range I stay in)
小結
其實 Pay As You Go 買個 100 點算力也才 10 美金,如果是 Lora 小模型的話,應該夠算個 8~9 個了吧,跟買一張 4090 來比,挺香的不是嘛。

ps. GPU information 是在 ipynb 加點料,因為我想知道每次訓練抽到什麼卡 XD

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)