
![[Lora] 訓練 1000 個小時之後](/content/images/size/w960/2023/05/00064-74bf3269.png)
本次記錄都會是一些參考資料,如果對於訓練有興趣的人可以自己去看看。基本上網路上能找到的資料有九成以上是針對二次元的訓練,所以如果是對這方面有興趣的人,這些資源是不錯的閱讀方向。
參考資料
論文什麼的太枯燥就不放了,這邊是很多人測試的記錄文章,在相對沒有那麼多資源可以測試的情況下,參考別人的作法來調整也是不錯的選擇!
關於基本訓練
首先我必須說,以下資料對於「小」資料集確實能發揮功效,
| Learning Rate | Text Encoder Lr | UNet Lr |
|---|---|---|
1e-4 |
5e-5 |
1e-4 |
所需要準備的資料集大概是這樣,
| 重複次數 | 資料集 | 正規化資料 |
|---|---|---|
4,000 ~ 2,000 |
20 ~ 50 |
0 |
上述資料集的重複次數可以自行估算,訓練輪次(Epoch)在 4 ~ 8 次就可以獲得不錯的結果。如果沒有追求很高的相似度,那麼市面上所提供的參數應該能符合大部分的需求。
關於我的訓練
聲明一下,我所使用的訓練集都是私人擁有,並無使用其他任何的公開資料集。
由於我都是訓練真人為主,所以其實目標是追求 99.99% 的相似度。當然,我也可以練一個 Embedding 然後用換臉(inpaint)的方式來做。不過基於對 SD 跟 Lora 之間的研究,我還是跑了很多不同的參數、資料集的測試。
我的資料集與訓練設定大概如下,
| 重複次數 | 資料集 | 正規化資料 |
|---|---|---|
32,000 ~ 4,000 |
4,000 ~ 20 |
0 ~ 12,000 |
我目前所使用的提示詞方式,都改用 WD 1.4 SwinV2 Tagger V2 來幫我產生,雖然說 AI 自動產生的不一定會出什麼亂子,不過還是要看一下,畢竟我也不想讓 AI 亂產生一些奇怪的東西。
是的,針對
4,000張資料集設定提示詞。
這邊我要說一下,我所使用的提示詞,都是經過我手動刪減過的,並非完全保留原始提示詞。
關於提示詞的部分,市面上絕大部分都是訓練二次元為主,所以為了保留一些特定風格或特徵,會斟酌的刪減提示詞的內容。不過,由於我是訓練真人,所以我會盡量保留提示詞的內容,不過也會刪減一些不必要的內容。一方面來說,保留特徵提示詞可以增加後續整個模型的泛型,也能確保在訓練時,模型不會太過於偏離原本的風格。
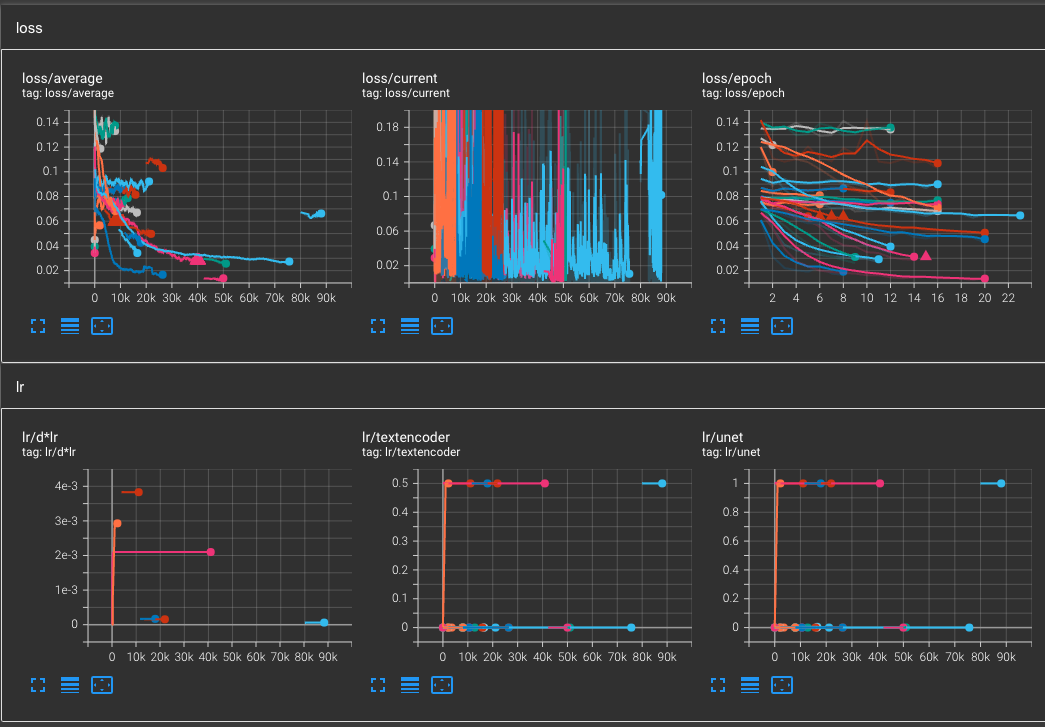
在訓練了超過 100 個模型之後,我發現了一些有趣的現象,
- 優化器的使用來說,
AdamW8bit目前還是首選。 - 優化器
Dadaptation雖然很懶人,但對於優化的程度不佳(需要更多測試)。 - 學習率與 UNet 學習率保持一致的效果比較好(根據網友表示 Lr 根本參考用,重點是 UNet Lr 才有效果)。
- Text Encoder Lr 可以保持為 UNet 的一半,但過低不利於泛型(特徵會鎖定不利更換)。
- Network Rank (Dimension) 在
128 ~ 192之間都有不錯的結果。 - Network Alpha 依照市面上的
dim/2會很容易造成梯度爆炸,必需要適度降低學習率(需要更多測試)。 - Network Alpha 可以的話維持
1再依照學習率調整。 - 若真的要提升 Network Alpha 的話,把這個數字除以
4,然後學習率除以該結果(會需要更多的訓練步數)。 - LR Scheduler 推薦使用
constant或cosine_with_restart來訓練。 - LR Scheduler 如果使用
_warmup系列,注意可能會因為正規化資料的關係,讓訓練結果偏離預期。 - 訓練總步數,若資料集在
30,000以下,最高維持在8,000 ~ 12,000就能得到不錯的結果。 - 優化器的額外參數,如果是
AdamW8bit的話,可以試試weight_decay=0.1來優化梯度避免過度學習(過擬合)。 - 優化器的額外參數,如果是
Dadaptation的話,可以試試decouple=Trueweight_decay=0.02,理由同上。
以上都是我個人的經驗,並不代表絕對正確。
我最上面列出來的文章中,有個日本的筆記提到了關於學習率的計算方式,如果沒有正規化資料集的情況下,在 LR Scheduler 使用 constant 的情況下,可以試試看,
學習率 (
Learning rate) = 目標學習效果 (0.95) / (輪次 (Epoch) x 資料集圖片 x 重複次數 (Repeat) x 批次大小 (Total Batch size))
所以說,若你的目標學習率在 95%,你準備了 20 張照片,每張照片重複 100 次,批次大小為 2,總共跑 8 個輪次(Epoch),那麼你的學習率就是 0.95 / (2 x 20 x 100 x 8) = 2.96875e-5。
這個數字你可以試試看,至於 Text Encoder Lr 就直接除以 2 來用也可以。請注意,這個學習率比起市面上所說的 1e-4 還要小得多,所以請注意你自己的訓練總次數,若是訓練次數太少,可能會造成模型無法收斂。
另外,由於此公式並沒有提出正規化資料集對於整體學習率的影響,所以當你有準備大量正規化資料集時,學習率是否要調整還需要自己去測試。
正規化資料集的影響
在眾多訓練教學當中,其實鮮少提及這個部分,絕大部分的情況下,也是沒有特別針對正規化資料集做提示詞的製作。但,做了會不會比較好?
會,正規化資料集做提示詞增加穩定性,也能提升泛型的作用。
所以在我的訓練當中,就會區分為不需要提示詞,與需要提示詞的兩個部分。再者,由於部分的正規化資料集會非常類似訓練集內容,所以這個部分就更需要提示詞,來避免模型過度學習的狀況。雖然說我們把 Prior loss weight 的數值設定在 0.15 ~ 0.4 之間,不過,就如同我之前所舉的例子,你若是要訓練新垣結衣,正規化資料集中若有完全是本人的照片,那麼會很容易出現複製貼上的情況(過度傾向正規化資料集,而不是你的訓練結果)。
根據幾次的實驗,我在不同的訓練過程中,從完全無關,到完全正相關,完全一樣的正規化資料集,都有不同的結果。
| 正規化資料 | 訓練集資料 | 相關度 |
|---|---|---|
1,000 |
20 |
0% |
2,000 |
50 |
10% |
2,000 |
100 |
10% |
2,000 |
200 |
10% |
4,000 |
20 |
0% |
4,000 |
50 |
10% |
8,000 |
100 |
10% |
12,000 |
100 |
10% |
以上這些組合的相關度,是以訓練集資料為 A,且正規化資料集也是 A 的狀況,換句話說,絕大部分的情況會是正規化資料集的 A 遠大於訓練集的 A 的情況。這種時候,你需要額外做訓練次數平衡,來避免學習過程中出現奇怪的問題。另外,學習率也需要適度降低,避免梯度爆炸(或是直接躺平)。
舉個例子,
| 正規化資料 | 訓練集資料 | 相關度 |
|---|---|---|
4,000 |
20 |
10% |
此時,正規化資料應該區分為兩種,
1_ai-hina完全與訓練集資料無關,假設他有2,600張,只看(Repeat)1次。2_ai-hina與訓練集資料同為 A 的目標,假設他有200張,我們看(Repeat)2次。
那麼我們會知道跟訓練集資料 A 相同目標的正規化資料被看了 400 次,那麼,我們的訓練集資料 A 就必需要約略 大於或等於 這個次數。在這個例子當中,我們訓練集只有 20 張,所以通常看(Repeat)的次數都會設定在 100 左右,所以整個訓練集的總步數會是在 2,000 次。而通常正規化資料集給的建議是 100 ~ 200 倍於訓練資料集,如果你能準備到這麼多正規化資料當然是好,但由於裡面有完全相同的資料,所以並不建議將他放大到太大的數量。
你可以試試看我不反對。
當然,我也準備過 24,000 張正規化資料集,我只能說,如果提示詞修飾的很好,那麼他的泛型跟穩定性,還有訓練結果都是不錯的。唯獨就是學習率需要不斷的嘗試,或者是使用 Dadaptation 讓他爆炸個幾次,然後再從學習的 Log 當中去計算優化的步數、學習率等等。
ps. 若使用 Kohya-ss 的訓練工具,在原始碼中有提到,會捨棄超過訓練數量的正規化資料集。所以如果你的訓練資料集沒有很多的話,太多正規資料集基本上沒有什麼效果。
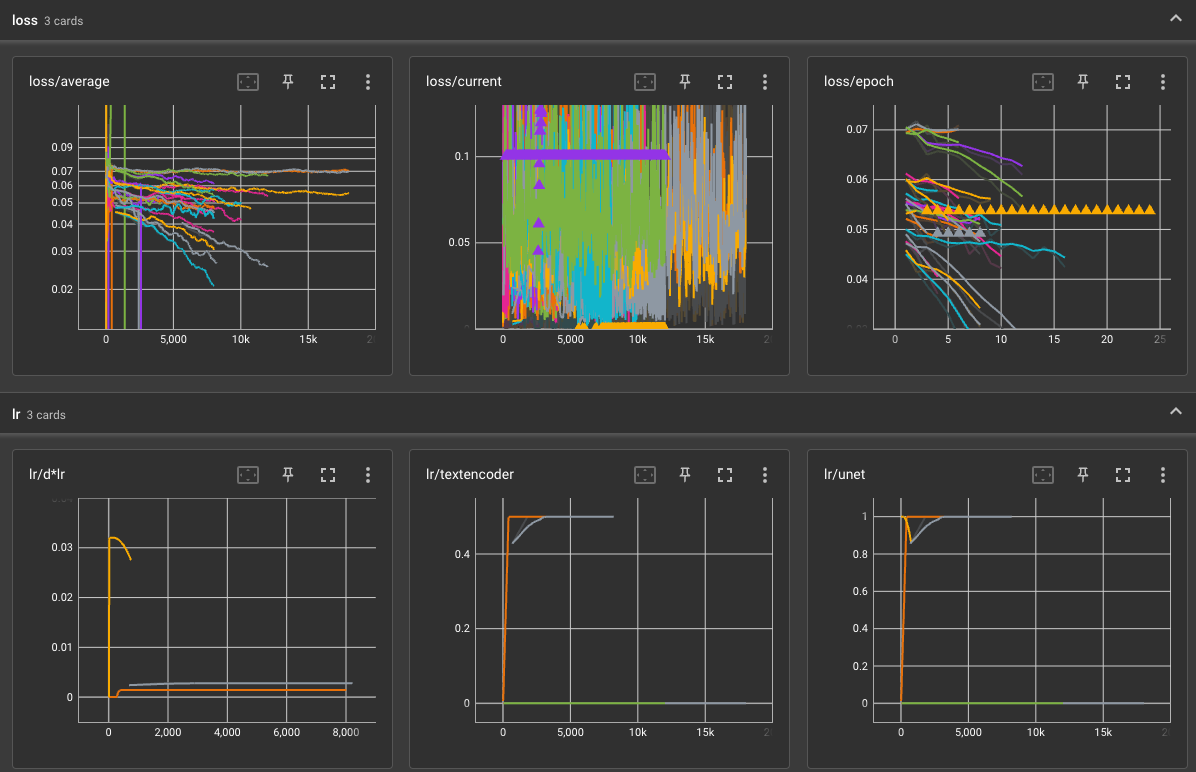

結語
若使用 cosine_with_restart 的話,還得把積分搬出來,還好現在網路很方便,可以在線上算真是很棒的一件事情。
補充說明
以下是我常用的 Kohya-ss 訓練工具,我在 之前的文章 也是用同一套。
另外,關於正規化資料集幾點補充,
- 他是從 Dreambooth 延伸而來,論文 在這邊。
- Dreambooth github
- Huggingface, Dreambooth
- 市面上說的正規化資料集是訓練資料集的多少倍來源不明,起碼我沒有真的照做。
- Kohya-ss 的訓練工具中,會捨棄超過訓練集數量的正規化資料集,所以你準備超多不一定有用。
訓練時間主要取決於「訓練集」,而正規化資料集只是拿來避免過擬合或是避免訓練走歪掉的一個檢查,他「並不會被訓練」,所以實際上你感覺不到時間的變化。有一種狀況會讓正規化資料集強迫干擾訓練集,就是訓練 Epoch 過長,造成非常大的過擬合,這個時候 Reg 的資料就會進行干擾,用來壓低訓練結果過擬合的程度。- 正規化資料集在 Kohya-ss 訓練中,若有使用會直接將步數乘上兩倍。
- 正規化圖片根據
Prior loss weight而對訓練資料集有不同程度上的干涉。 - 在過擬合嚴重的情況下,如果你的正規化資料集,跟訓練集「一樣」那就會更慘。如果跟訓練集「正相關」那就會融合正規化資料集,如果完全「不相關」則會產生出奇妙的結果(不可預期)。
- Regularization 的概念是從 Dreambooth 那邊挪過來用,Huggingface 的Dreambooth 裡面有提到
The authors recommend generating num_epochs * num_samples images for prior preservation.但是我看過論文,沒有提到這件事情(那到底是誰說的 XD) - 可以確定的是,有放 Reg 的效果會比沒放要好,但如果以 Kohya-ss 來說,那個
Prior loss weight可以決定 Reg 的干涉程度,如果用1真的會很容易從 Reg 複製貼上。


![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)