
![[Kohya_ss] 訓練參數計算筆記](/content/images/size/w960/2023/05/00073-cover.png)
更新了 Kohya_ss 之後,有些地方的參數跟 GUI 其實不太一樣,這邊單純記錄一下,以免以後覺得哪裡怪怪的。
Kohya_ss 版本
目前的穩定版本是 v21.5.11 所以以下的紀錄都是針對這個版本來做調整。
另外我有針對正規化資料集而修改程式碼,我先說在前面。
訓練計算的改變
首先,訓練的 Log 都會有這個計算資料出現,
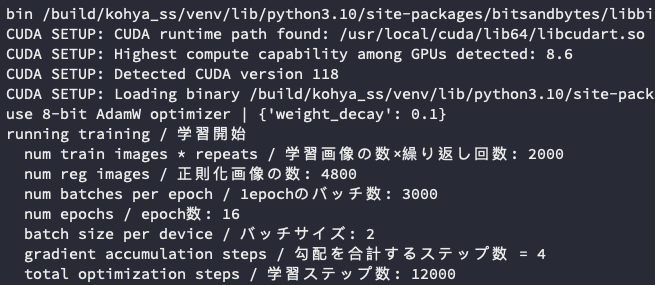
第一個訓練資料集的數量應該沒有懸念,就是你設定多少,他就會寫多少。由上面的圖片可以知道我是有 2,000 步的訓練資料集。接著,正規化資料集的數量有 4,800,這應該也沒什麼太大問題,算法跟資料集一樣,是使用 數量 x 重複次數 來計算。
接著,我先條列一下我在 Kahyo_ss 所使用的相關設定,
Total batch size使用2。Epoch使用24。Gradient accumulate steps使用4。
根據以往的計算方式,我們可以得知最大訓練步數會是:
最大訓練步數 = 資料集步數 x Epoch / Total batch size
所以如果依照以往的計算方式,我們可能會覺得會得到 24,000 這樣的訓練步數。但是,實際你去執行的時候,你會發現你得到了一個 Total optimization steps: 12,000 的結果。
所以,他並不是你 想要的預期訓練步數,而畫面當中的 num epochs 也不是你預期所設定的 24,更不是以往的 (Epoch / Total batch size) x Gradient accumulate steps 的結果。
根據最新版本的 Kahyo_ss 來看,關於訓練步數的計算、Epoch 與每個 Epoch 計算步數,修改為:
https://github.com/bmaltais/kohya_ss/blob/master/train_network.py#L299
// 每一個 Epoch 更新的步數
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
// 總共要跑多少個 Epoch
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
其中 train_dataloader 是由 torch.utils.data.DataLoader 負責,
https://github.com/bmaltais/kohya_ss/blob/master/train_network.py#L220
train_dataloader = torch.utils.data.DataLoader(
train_dataset_group,
batch_size=1,
shuffle=True,
collate_fn=collater,
num_workers=n_workers,
persistent_workers=args.persistent_data_loader_workers,
)
而,倘若有設定 max_train_epochs 的話,則 max_train_steps 會另外計算如下,
https://github.com/bmaltais/kohya_ss/blob/master/train_network.py#L229
args.max_train_steps = args.max_train_epochs * math.ceil(
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
)
如果沒有,那麼 max_train_steps 預設計算方式會是,
https://github.com/bmaltais/kohya_ss/blob/master/lora_gui.py#L561
max_train_steps = int(
math.ceil(
float(total_steps)
/ int(train_batch_size)
/ int(gradient_accumulation_steps)
* int(epoch)
* int(reg_factor)
)
)
total_steps是由訓練集的步數計算而來。epoch就是你在 GUI 當中輸入的數字。reg_factor是一個常數,若沒有使用正規化資料集,則預設為1,有使用的話會是2。
所以,根據以上的資料,我們可以得知,
max_train_steps = 2,000 / 2 / 4 * 24 * 2 = 12,000
這樣你就會獲得跟 Kahyo_ss 所計算出來的總訓練步數相同的結果。
推算 Epoch
在 Kahyo_ss 當中,當你有準備正規化資料集時,他並不會全數採用,
https://github.com/bmaltais/kohya_ss/blob/master/library/train_util.py#L1137
print(f"{num_reg_images} reg images.")
if num_train_images < num_reg_images:
print("some of reg images are not used / 正則化画像の数が多いので、一部使用されない正則化画像があります")
if num_reg_images == 0:
print("no regularization images / 正則化画像が見つかりませんでした")
else:
# num_repeatsを計算する:どうせ大した数ではないのでループで処理する
n = 0
first_loop = True
while n < num_train_images:
for info in reg_infos:
if first_loop:
self.register_image(info, subset)
n += info.num_repeats
else:
info.num_repeats += 1 # rewrite registered info
n += 1
if n >= num_train_images:
break
first_loop = False
他最多只會取出與你的訓練資料集相同數量的正規化資料集來使用,換句話說,如果你的訓練資料集是 2,000 個步數的話,那麼在正規化資料集也會同樣取 2,000 個步數的圖片出來使用。
請注意,他是使用步數計算,並不是圖片數量。
所以,根據這樣的計算方式,如果以我的資料集設定來說,我們可以推算出 train_dataloader 大概是多少,
train_dataloader 的數量 = (訓練集步數 + 正規化資料集步數) / batch size = 4,000 / 2 = 2,000
為什麼我是 3,000 呢?因為我改了原本的程式碼,讓他多吃一點我的訓練資料集進去,所以我會拿到 3,000 的數字,請不要大驚小怪。
接著,我們知道了 train_dataloader 的數量後,就能用上面的公式來推算出 num_update_steps_per_epoch 與 num_train_epochs 的數字,
// 每一個 Epoch 更新的步數
num_update_steps_per_epoch = 3,000 / 4 = 750
// 總共要跑多少個 Epoch
num_train_epochs = 12,000 / 750 = 16
這個時候再回頭看一下剛剛的 Log 畫面,你就會知道這些數字是怎麼計算出來的了。
小結
這個改動蠻討厭的,這樣每次要平衡資料集的次數的時候,都要多按幾次計算機。

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)