
![[Flux] Lora 從訓練到放棄](/content/images/size/w960/2024/09/00057-3368661048.png)
自從 SD3 徹底被放棄之後,Flux 的出現又是一個新的氣象。加上前一陣子 C 站大動作率先支援 Flux Dev 的訓練,所以整個 Flux Lora 如同雨後春筍般瘋狂的冒了出來。
線上工具也是有諸如 AI-toolkit,本地端青龍的訓練包,以及 Kohya。
FLUX
這是由 Block Forest Labs 所釋出的新模型,目前市面上流通的是 Dev 與 Schnell 兩個版本,而 Pro 版本僅只能線上使用並未釋出。這兩個版本都是由 Pro 版本剪支而來(應該是吧?),而 Schnell 則是更精簡的 4 步生成模型。
兩個模型的使用授權範圍不同,Dev 是不可商用的,而 Schnell 基本上走的是 Apache 2.0 的授權,所以商用上沒什麼太大問題。
目前比較大宗的訓練面向還是以 Dev 為主(因為 C 站率先開了第一槍),所以這邊我也會以 Dev 的訓練來介紹。
Lora 訓練
Lora 基本的概念我就不贅述了,訓練 Flux 跟訓練 SD1.5/SDXL 差不多,該準備的提詞、圖片你也一樣都不能少。至於說,訓練的過程中會發生什麼事情,我後續在慢慢跟各位介紹。
首先,訓練的方法有很多選擇,
- CIVITAI 線上訓練,目前應該最方便。
- AI-toolkit, Colab 需要 Colab Pro 你會跑得比較開心。
- Kohya, sd-scripts, sd3 分支 本地端訓練,你需要最少 12GB,最好 16GB 以上 VRAM,系統記憶體最少 32GB 比較保險。
- Kohya GUI, sd4-flux.1 分支 然後他有一個 Typo,我去開 Issue 了但是他還沒修掉。
- Tensor.Art 很少人知道他可以練吧?官方看到我這篇會不會把他關閉呢?
CIVITAI 訓練器
註冊帳號什麼的我就不贅述了。這邊直接給大家參數的畫面參考,
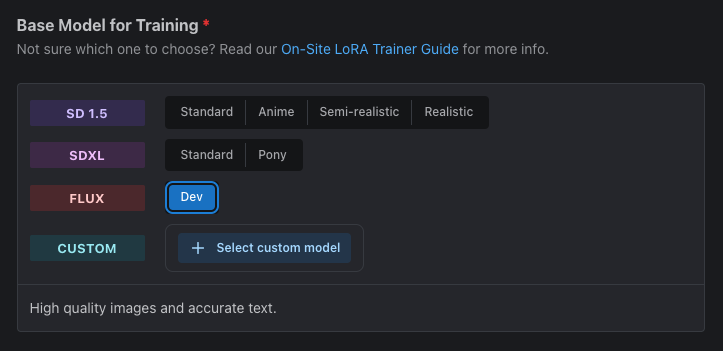
首先你得選擇 FLUX Dev 的項目當作基本的訓練模型。
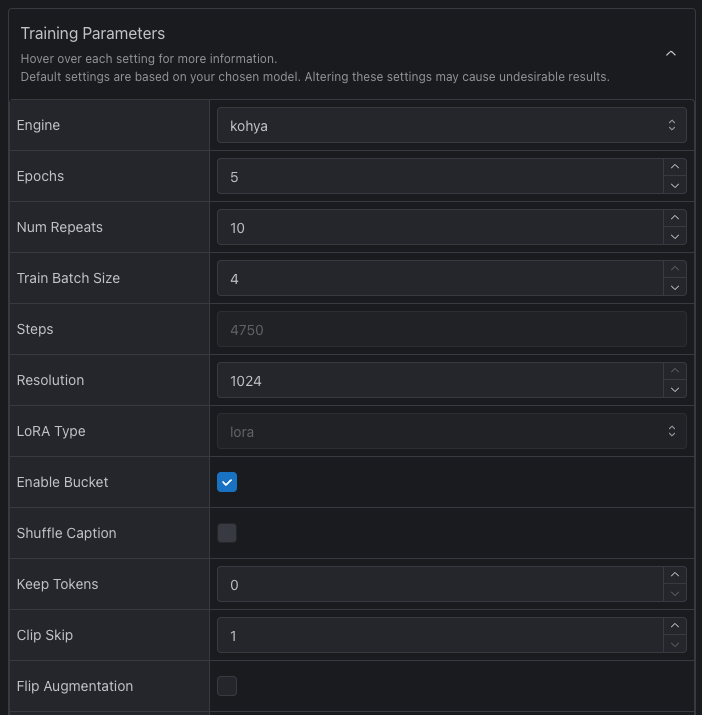
這邊幾個項目我稍微說明一下,
| 參數 | 設定 | 說明 |
|---|---|---|
| Epochs | 5 |
設定訓練要跑幾個輪次,當然數字高一點對穩健性比較有幫助。 |
| Num Repeats | 10 |
設定圖片在訓練時要被看幾次,數字不是越高越好,你圖片數量夠多的情況下,可以斟酌減少這個數量。 |
| Train Batch Size | 4 |
這邊可以先使用 4 沒有問題,他對於訓練目標特徵的固定有幫助。 |
| Resolution | 1024 |
這邊可以直接開到最大 1024,如果你的訓練圖片沒有大於這個尺寸,那麼你可以降低到 768 或是 512 試試看。 |
其他的參數可以不需要更改。最後,你會得到一個 Steps 也就是總共訓練會跑得步數,C 站計算 Buzz 點數主要是依照這個步數為主,步數越高,需要消耗的點數也越高。
這邊建議你可以把步數抓在 4,000 附近。
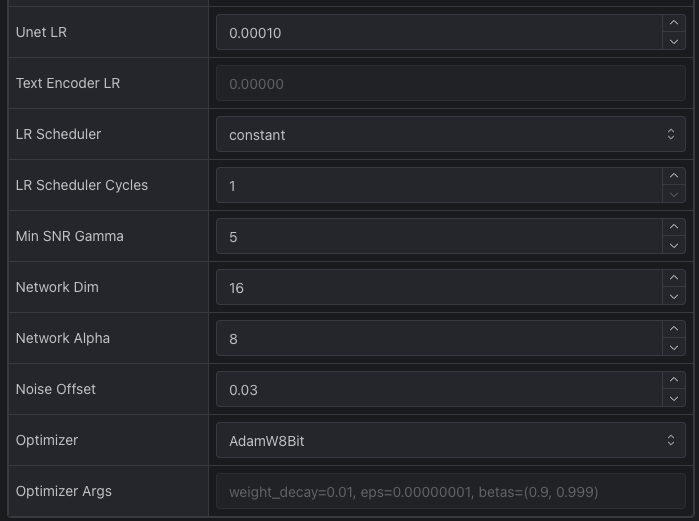
這裡的參數是這樣的,
| 參數 | 設定 | 說明 |
|---|---|---|
| Unet LR | 0.00010 |
這是 UNET 學習率,建議使用 1e-4 或是 5e-5,我這邊採用 1e-4。 |
| LR Scheduler | constant |
這是學習率排程器,採用這個方法對於後面我們使用的優化器來說是不錯的選項。 |
| LR Scheduler Cycles | 1 |
其實這個項目不會用到,除非你排程器使用 cosine_with_restart 才會有效果。 |
| Network Dim | 16 |
如果你只是練一個角色,用 16 其實就足夠了。 |
| Network Alpha | 8 |
由於 Unet LR 使用 1e-4,所以我們這裡用 8。 |
| Noise Offset | 0.03 |
這邊先採用與 SDXL 相近的數值就好。 |
| Optimizer | AdamW8Bit |
我們這邊採用 AdamW8Bit 優化器即可。 |
由於在 C 站的訓練器背後是採用 Kohya,但版本不明,所以上述是目前我執行起來還算不錯的設定。
其實在 Flux 訓練中,排程器使用 constant_with_warmup 是更好的選擇,但由於 C 站並沒有提供 Lr warmup steps 的設定,所以我們這邊才會採用 constant 來執行。
而關於 Dim/Alpha 的設計,我之所以採用 Alpha = Dim / 2 的原因在於,我的學習率是使用 1e-4 的情況下,我希望在權重累加的時候削弱效果,所以 Alpha 才會採用 Dim 的一半來設定。實際上,你要使用 Dim = Alpha = 16 也是可以的。
設定好之後就可以讓他去幫你訓練模型了。
AI-Toolkit
這個工具需要在 Colab 上面執行,或者是你本地端的設備夠用的話,你也可以在本地端執行應該是沒有問題的。
要執行這個 notebook 你需要有 Huggungface 的帳號,並且要先取得 black-forest-labs/FLUX.1-dev 的存取權。
我這邊直接開啟他預設的項目來給大家說明,
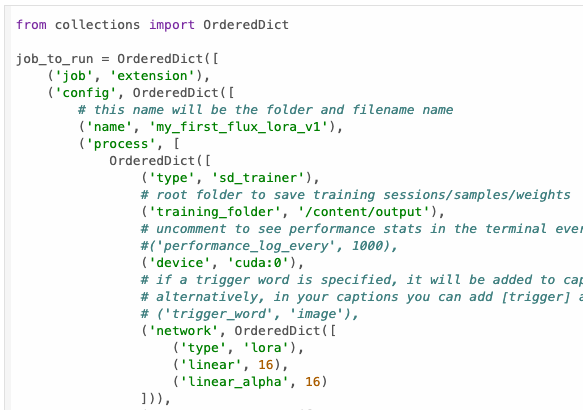
這邊就按照項目來逐一說明:
| 項目 | 值 | 說明 |
|---|---|---|
name |
my_first_flux_lora_v1 |
你的 Lora 名稱,你可以自己修改成你要的名字。 |
training_folder |
/content/output |
訓練後儲存的位置,這邊可以改成指定到你的 Google Drive 裡面的路徑。 |
network.linear |
16 |
這邊就是我們所熟悉的 Network Dim,預設使用 16。 |
network.linear_alpha |
16 |
這邊就是我們所熟悉的 Network Alpha,預設使用 16。請注意!更改他貌似沒有作用,AI-Toolkit 訓練會讓 Alpha = Dim。 |
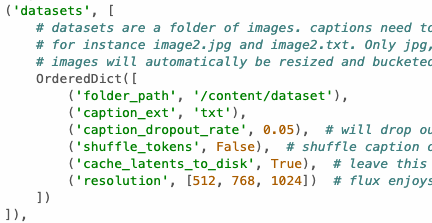
接下是要設定你要訓練的資料集:
| 項目 | 值 | 說明 |
|---|---|---|
folder_path |
/content/dataset |
你的圖片資料集的資料夾,資料夾中直接放置圖片跟提示詞檔案。 |
caption_ext |
txt |
圖片提示詞檔案的附檔名。 |
caption_dropout_rate |
0.05 |
圖片提示詞捨棄率,在 Flux 中我並不確定這個是否真的有效。 |
shuffle_tokens |
False |
隨機打散提示詞,在 Flux 中我並不確定這個是否真的有效。 |
cache_latents_to_disk |
True |
快取潛空間資訊,預設啟用,請別更改他。 |
resolution |
[512, 768, 1024] |
Flux 可以支援多解析度訓練,所以可以放三個,你要改成一個也可以。 |
其中 shuffle_tokens 與 caption_dropout_rate 個人覺得應該是設定了也沒效果。根據 Kohya 的作法,在訓練 Flux 時會快取 Caption,所以這兩個設置基本上會直接失效。但我不確定 AI-Toolkit 背後的訓練機制,所以這兩個設定就暫時留著。
請注意!以上的設定只有設定一個資料夾,而他每個資料夾的圖片只會看 1 次。所以如果你要多組資料夾,或是要設定他的圖片重複次數,需要使用 num_repeats 來設定。
我舉個例子:
OrderedDict([
('folder_path', '/content/drive/MyDrive/portrait'),
('caption_ext', 'txt'),
('num_repeats', 5),
('cache_latents_to_disk', True),
('resolution', [512, 768, 1024])
]),

接著訓練設定,我沒有提到的部分你可以暫時忽略:
| 項目 | 值 | 說明 |
|---|---|---|
batch_size |
1 |
他在這邊預設使用 1,可以先使用這個沒問題,畢竟你不是每次都抽的到 A100。 |
steps |
2000 |
預設訓練 2,000 步,你可以增加他或減少他,看你的訓練目標。 |
content_or_style |
balanced |
這邊可以選擇三種,content, style, balanced,是對於你的訓練目標的方向,預設是使用 balanced。 |
optimizer |
adamw8bit |
優化器預設採用 adamw8bit。 |
lr |
1e-4 |
學習率預設使用 1e-4 |
linear_timesteps |
True |
這個項目你可以斟酌使用,實驗性功能,可能可以獲得比較好的結果。 |
最後是訓練時可以生成範例圖片的設定,如果你上面有使用 disable_sampling 的話,底下的設定就不需要管他了。

這個生成範例設定,在 Prompt 裡面的每一行都是一個描述,你可以改成你想要的描述,然後每一行都會生成一張圖片,如果你不想要太多,就把他刪減到只剩下一行就好。最後就是讓他跑訓練了。
使用神童 Prodigy 優化器
('lr_scheduler', 'cosine'),
('optimizer', 'prodigy'),
('lr', 1.0),
('optimizer_params', OrderedDict([
('safeguard_warmup', True),
('decouple', True),
('use_bias_correction', True),
('betas', [0.9, 0.99]),
('weight_decay', 0.5),
('d_coef', 2)
])),
具體要怎麼改我不多說,懂的就懂。
Kohya / Kohya GUI
我想這是絕大多數人熟悉的,在 Kohya GUI 新的分支 sd3-flux.1 當中,已經對 Kohya 的 Flux 訓練新增了支援。但我實在不知道他那個打錯字的 Bug 到底什麼時候要修。
首先,在本地端訓練,你需要準備以下檔案,
- flux.1-dev
- flux.1-schnell 如果你要訓練這種,才需要下載。
- ae
- clip-l
- t5xxl-fp16
接著我們從熟悉的 Kohya 介面開始,
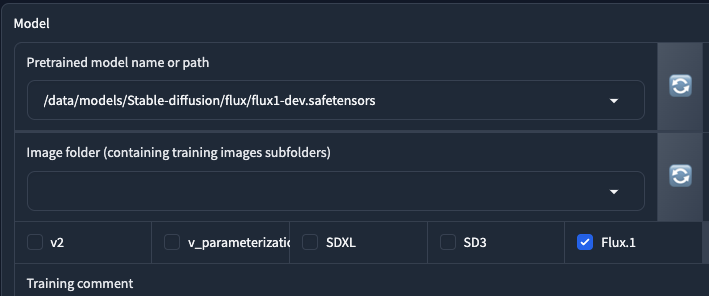
在預訓練模型的部分,你要選擇剛剛下載的 flux.1-dev.safetensors 檔案,這是一個 fp16 的 UNET 預訓練模型。在 Kohya 訓練器中,你只能使用這種預訓練模型(或是 flux.1-schnell.safetensors)。
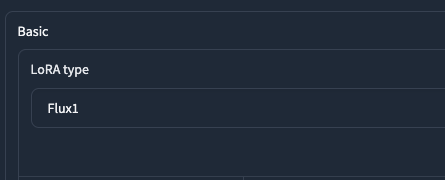
接著我們在 Lora Type 的地方選擇 Flux1,代表我們是要訓練 Flux。選擇了這個類型之後,我們在下方的參數設定中,就會多出一個區塊是關於 Flux1 的設定。
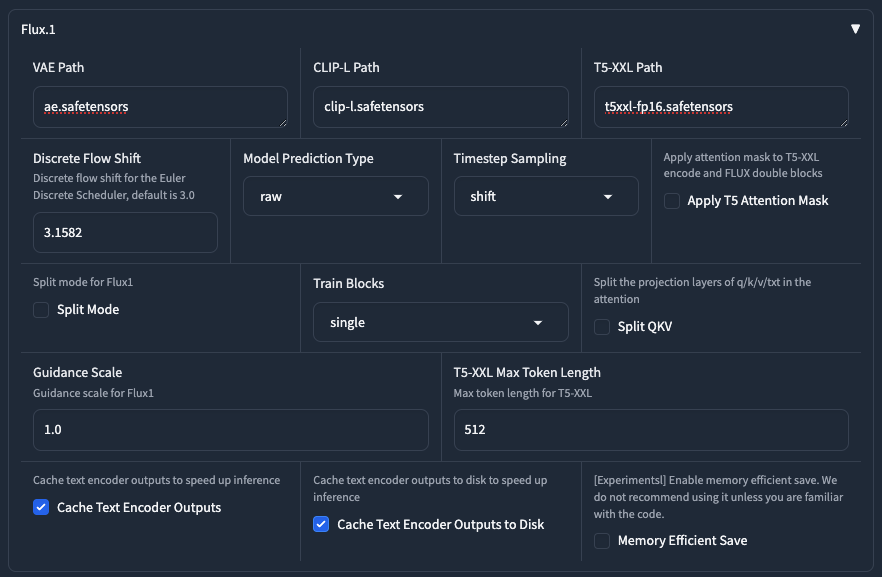
這個地方我稍微說明一下,
| 參數 | 值 | 說明 |
|---|---|---|
| VAE Path | ae.safetensors |
這邊要填入你剛剛下載的 ae.safetensors 的檔案路徑。 |
| CLIP-L Path | clip-l.safetensors |
這邊要填入你剛剛下載的 clip-l.safetensors 的檔案路徑。 |
| T5-XXL Path | t5xxl-fp16.safetensors |
這邊要填入你剛剛下載的 t5xxl-fp16.safetensors 的檔案路徑。 |
| Discrete Flow Shift | 3.1582 |
Kohya 建議數值,當 Timestep Sampling 使用 shift 時。 |
| Model Prediction Type | raw |
使用 raw 即可。 |
| Timestep Sampling | shift |
使用 shift 或是 flux_shift 都可以。 |
| Apply T5 Attention Mask | 不使用 |
建議開啟。 |
| Split Mode | 不使用 |
VRAM 嚴重不足要開啟,但訓練速度會變慢很多。 |
| Split QKV | 不使用 |
這是從 AIToolkit 那邊拿來的功能,開了訓練速度會變慢,但效果會變好,可以自行斟酌是否要開。 |
| T5-XXL Max Token Length | 512 |
你可以使用 154 |
| Train Blocks | single |
你可以訓練 all 或 single 都可。 |
| Guidance Scale | 1.0 |
請使用 1.0。 |
| Cache Text Encoder Outputs | 啟用 |
請啟用他。 |
| Cache Text Encoder Outputs to Disk | 啟用 |
請啟用他。 |
這邊需要注意一點,關於 Timestep Sampling 在 Kohya GUI 的 Bug 還沒修正以前,請不要使用 flux_shift。
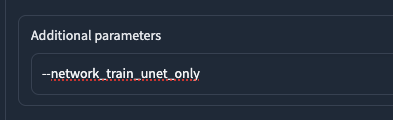
請在 Additional parameters 上面填入 --network_train_unet_only。
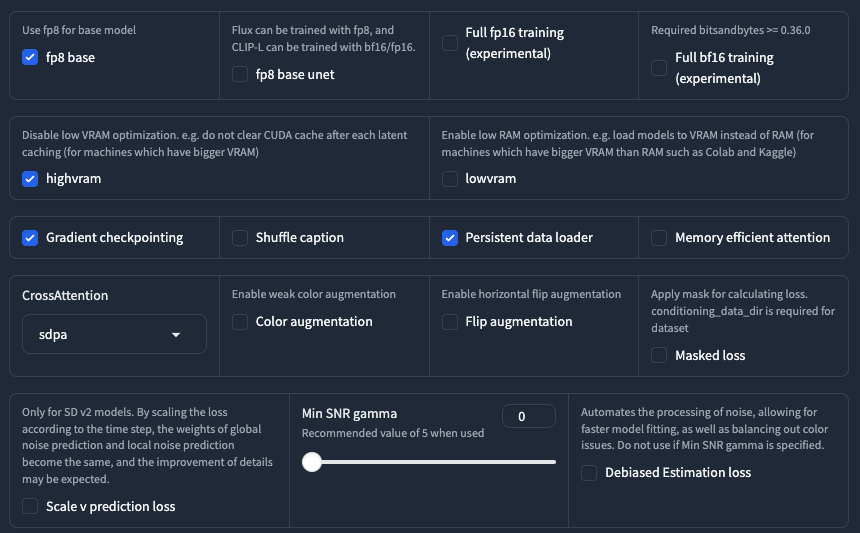
剩下的一些項目請依照上面的去設定即可。如果你不知道這些項目的功能,請勿隨意開啟或是設定他,我無法保證這樣是否會干擾到最終訓練結果。
最後,我知道大家很喜歡抄作業,所以我準備了一個在 Kohya 中可以訓練多解析度的設定,
如果你沒有要跑多解析度,就使用後面的 json 檔案就好。
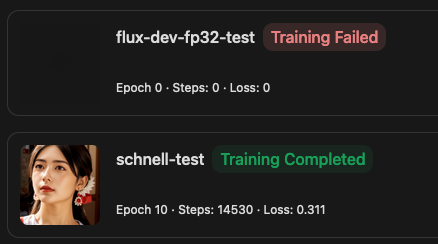
Tensor.ART
最後提一下這件事情,關於 Tensor.art 的註冊我之前 有寫過 TensorArt 訓練筆記 我就不再多說。
因為 TensorArt 有人把 FLUX-Dev fp32 的模型放上去,所以在好奇心的驅使下,我就來嘗試看看到底能不能跑 Flux 訓練。
後面的訓練參數設定其實跟上面的設定差不多,
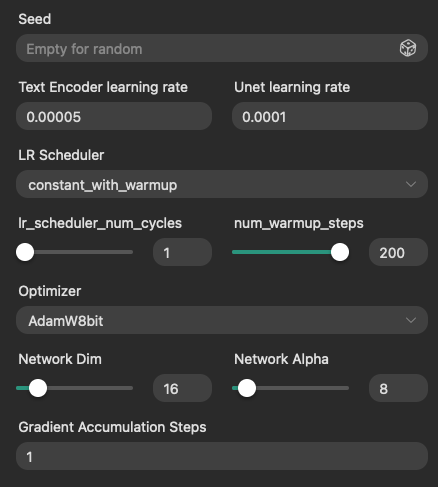
接下來就是賭你的運氣,看是不是 TensorArt 可以幫你跑完訓練了。
提詞
這件事情說起來真的很冗長,或許之後有時間我再整理這方面的相關資訊。目前的一個小小的結論是,
短提詞 + 自然語言描述
這是目前在訓練當中,算是表現比較好的一種訓練提詞方法。
小結
以下是我的 Flux 訓練結果,歡迎大家愛用,

![[LoRA Guide] Z Image Turbo Training with AI-Toolkit and Merging It!](/content/images/size/w960/2025/12/LN_845764713767329_00001_.jpg)
![[Lora] Z Image Turbo 與 AI-Toolkit](/content/images/size/w960/2025/12/hina_zImageTurbo_caline_v3-dream-1.jpg)
![[AI] 與 AI Agent 一起開發優化器](/content/images/size/w960/2025/07/00059-293292005.jpg)