
我不是 DBA,寫這種東西有點班門弄斧(揍飛)。
底下這兩個 Query 做的是相同的事情。
SELECT
a.id, COUNT(b.user_id) AS count FROMusersAS a LEFT JOINrecordsAS b ONa.id=b.user_idWHERE 1=1 GROUP BYb.user_id;
SELECT
a.id, ( SELECT COUNT(b.user_id) FROMrecordsAS b WHEREb.user_id=a.idGROUP BYb.user_id) AS count FROMusersAS a WHERE 1=1;
但是誰比較好?
由於我不太愛用 ORM,所以偶爾會面對這種問題。其實這是之前某個朋友來問我,如果要做關聯查詢的話,這樣的效能怎麼樣?雖然他用的是 MSSQL,但是我想只要是 SQL 應該是半斤八兩(除了 O 牌)。在 MySQL 裡面,有個很重要的東西,叫做 EXPLAIN!
他是用來分析你的 Query 命令用的,分析出來的結果大抵上會長這樣:
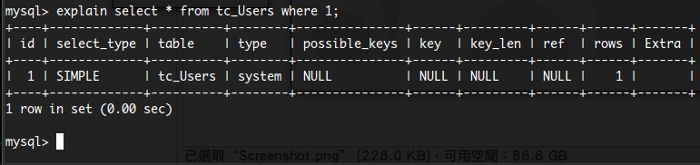
請不要問我 mysql> 這個命令提示列是怎麼來的。我打死也不會告訴你!
另外,你可以在 EXPLAIN 的結尾加上 \G; 來改變顯示方式。
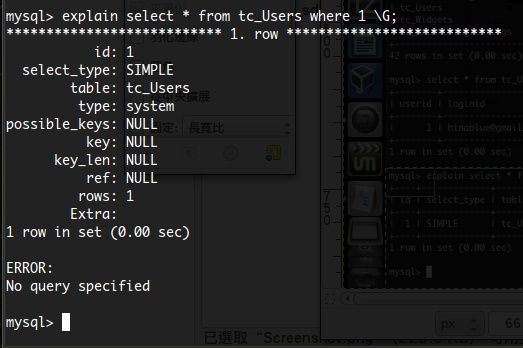
各個項目所代表的意義(可詳閱:http://www.beberlei.de/mysql_explain.html):
- table:有所關聯的資料表。
- type:資料表被取出的型態。效能從最優到最差分別有:
- system:該表只有 1 筆資料,會顯示這個形式。
- const:查詢結果等同於 1 筆資料(使用 PRIMARY 或是 UNIQUE KEY)。
- eq_ref:該表僅有 1 筆資料比對其他(或自身)表格,KEY 值欄位比對為 =(等號)。
- ref:JOIN 資料表時使用,當 KEY 值非 PRIMARY 或是 UNIQUE KEY 時,KEY 值欄位比對為 = 或是 <=>(不等於)。
- fulltext:使用全文比對(但是 Unicode 字元就別想了)。
- ref_or_null:跟 ref 類似,但是值是 NULL。
- index_merge:使用索引值合併最佳化(Index Merge Optimization used)。
- unique_subquery:單一資料表,子查詢使用 PRIMARY 或是 UNIQUE KEY。
- index_subquery:單一資料表,子查詢非 UNIQUE KEY(non-unique_key)。
- range:比對條件使用:=, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN [ list ] 等狀況。
- index:使用索引(Index)全表搜尋。
- all:全表搜尋。
- possible_key:可能所使用到的索引鍵值,通常是看 WHERE 條件式而定。
- key:實際被用到的索引鍵值,如果顯示 NULL 則表示沒有使用。
- key_len:所使用到的索引鍵值長度,長度越短表示索引鍵值越準確。
- ref:顯示那一個欄位的索引值被使用,如果沒有參照則顯示 NULL,通常會是常數 (const)
- rows:顯示查詢返回了多少筆資料。
- Extra:顯示額外的查詢訊息,這裡會告知你一些關於索引的資訊。通常的訊息有:
- Distinct:當 MySQL 找到相關資料後,就不再繼續查詢。
- Full scan on NULL key:子查詢沒有相關索引,所以使用全表搜尋。
- Impossible WHERE noticed after reading consts tables:WHERE 條件永遠不成立。
- No tables:找不到 FROM(或是 FROM DUAL)所指定的資料表。
- No exists:針對 JOIN 查詢,倘若找到相關資料後,就不再繼續查詢。
- Range checked for each rocord(index map: N):沒有相對應(或良好的)索引鍵值,這是最緩慢的查詢。
- Select tables optimized away:
我不知道該怎麼解釋。 - Using (...):有很多種狀況:
- filesort:使用額外的資訊來查詢。
- index:僅使用索引中的資料,並非由實際資料返回。
- index for group-by:使用 BROUP BY 或是 DISTINCT 時,僅使用索引中的資料。
- intersection:使用 index_merge JOIN type 取回資料。
- sort_union:使用 index_merge JOIN type 取回資料。
- temporary:使用暫存資料表(Temporary table)取回資料。
- union:使用 index_merge JOIN type 取回資料。
- where:使用 WHERE 條件來返回資料。
- where wish pushed condition:NDB 才會有的東西(
我也不知道怎麼解釋)。
我們可以繼續研究 Extra 所提供的資訊,相較之下,我撇除 NDB 的訊息,資料表存取的速度,大抵上可以這樣區分:
index > index for group-by > intersection = sort_union = union > where > temporary = filesort
同樣的,type 中也是有速度差別的:
system = const > eq_ref > ref >= ref_or_null >= fulltext > index_merge >= unique_subquery = index_subquery > range > index > all
HOWTO "EXPLAIN"
如果你慣用 ORM,那麼我想效能瓶頸可能不是你需要去關心的地方。我們來看一個例子:

這種複雜查詢(預設的 ORM 特性就是不斷地 JOIN),在帶來方便之餘,對於效能的衝擊並不是這麼容易去解決的事情。但是,在開發階段,與其去思考如何最佳化這樣的查詢,可能先能夠跑一個東西出來,要比去最佳化這件事情要來得容易許多。
那,什麼時候我需要這麼做?
- 當你的查詢慢到無以復加的時候。
- 當你的查詢條件非常複雜的時候。
- 當你要組合非常多的資料表的時候。
- 當你要 反正規化 的時候。
- 當你
吃飽沒事幹的時候。 - 當你要打掉重練得時候。
為什麼說反正規化(denormalized)?當我們資料越來越多,我們就得面臨到一個問題,如何適當地減少資料表中,資料 重複 性的可能。也許,我們在接手(或是在開始)一個專案的同時,我們所面對的資料庫是已經被資料正規化過(normalized)得資料表。那麼,在無法修改或是砍掉重練得情況下,我們就只能適切的將那些東西 逆向操作。
逆向操作就是反正規化。但是不能改怎麼辦?那就只好做新的資料表來解決這些事情。這很消極,但是卻很實用。ORM 並不是壞事,壞得是資料表沒有很適當地做好該有的索引(Index),導致資料汲取變得複雜冗長,而且緩慢!
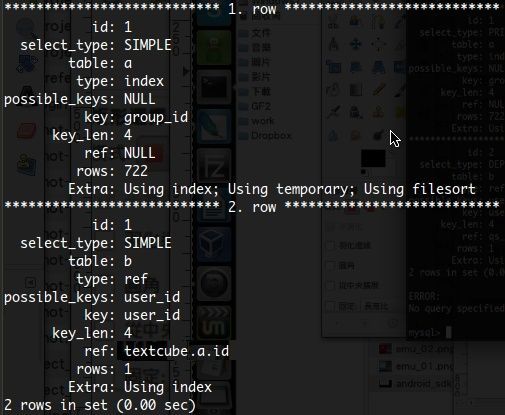
我們再回到開頭所說的兩個 Query,現在來 COMPLAIN EXPLAIN 一下!
這是第一個 Query 所輸出的訊息:
這是第二個 Query 所輸出的訊息:
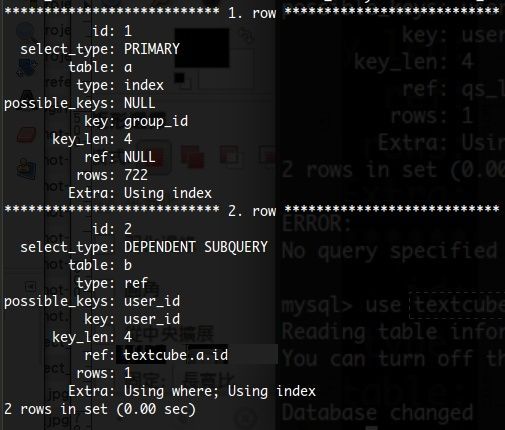
看出在 Extra 的差異了嗎?雖然兩筆資料查詢速度都非常快(因為總共也才 722 筆而已),但是資料表的查詢方式很明顯的就有所差別。如果你需要超大量資料來測試的話,可以到這裡找找看:
http://www.mysqlperformanceblog.com/2011/02/01/sample-datasets-for-benchmarking-and-testing/
我目前看到最大的好像是 3.5GB 上下的資料,可以提供給你作一些壓力測試等等。其實最主要的,還是資料表之間的規劃,不然,其實這麼大量的資料,拿來練習 Query 是還滿好玩的就是(揍飛)。
總之不要讓 EXPLAIN 變成 COMPLAIN 就好了(大誤
如果想看看很多資料的結果的話,我這邊貼出幾個讓大家參考一下。我對 ontime_2000_01 與 ontime_2000_02 這兩個資料表做取出動作:
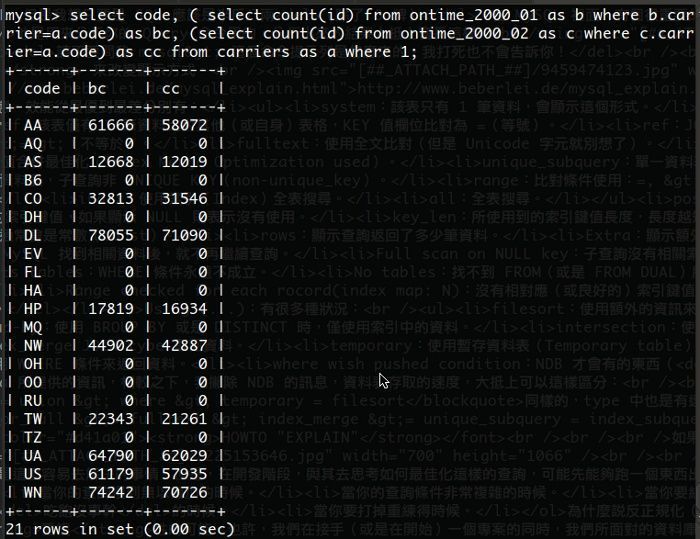
EXPLAIN 一下:
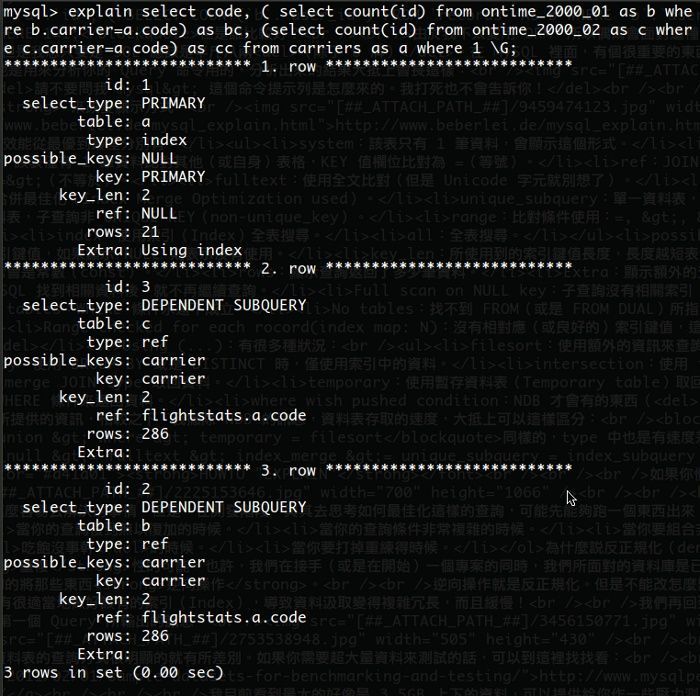
如果我用 UNION 只取出 code 為 AA 與 AS 的結果,EXPLAIN 一下:
對於 ontime_2000_01 這個資料表(共有 470,477 筆資料),如果用 UNION 效率是比 sub-query 還差得多,這顯而易見。如果用 JOIN 呢?
認真?
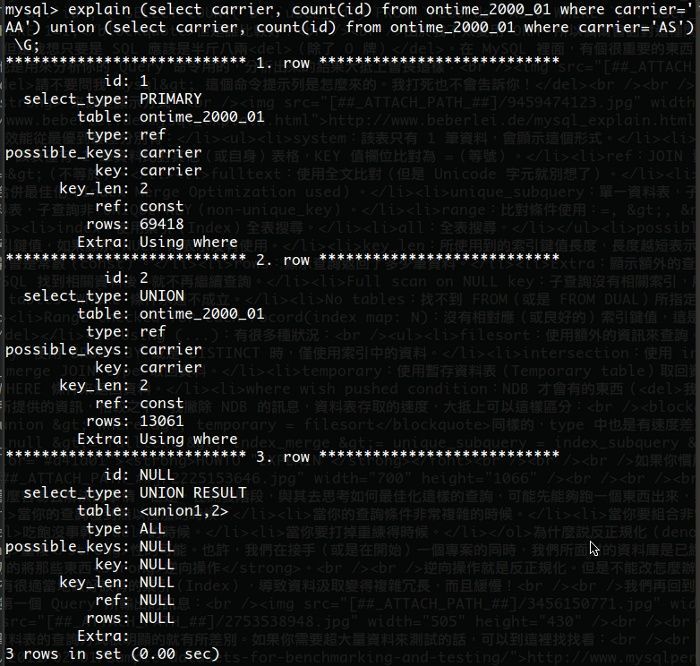
如果你需要 COUNT 多資料表,請勿輕易使用 JOIN,除了會讓資料表嚴重鎖死之外,還可以讓你住套房喔!底下是針對兩個表,四組 UNION 所出來的資料:

要看 JOIN 也是可以,不過只能跑一個表,我的 NB 撐不住跑兩個(兩個表加起來有 8x 萬筆以上的資料)。這是跑出來的 EXPLAIN 結果:
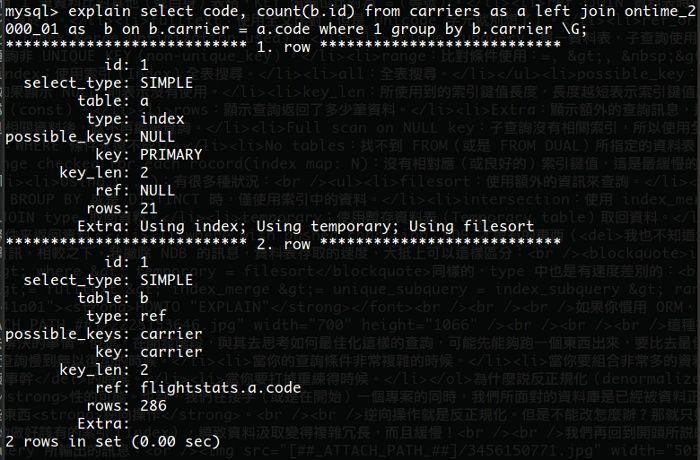
也許你會發現,有些時候 JOIN 單表速度(或是多表參照)的時候,會比起 sub-query 更具彈性且靈活(這也是 ORM 為什麼會使用 JOIN 的特性之一),但是,別忘記多表參照的時候,對於資料表的鎖定(lock)時間也會相對的拉長,如何避免這種問題,就只能在 Query 上面多花點心思了。
至此,希望大家對 EXPLAIN 有多一點認識。
ps. 我取用的資料是 http://dl.flightstats.us/ 所提供,壓縮檔案大概是 1.3GB 左右,解壓縮後 3.6GB。光是 ontime 系料資料表,保守估計超過 3 千萬筆資料,作為測試還蠻不錯的。
