
我之前寫過關於 AWS 的一些操作心得,然後最近剛好有人一直來信詢問,關於 Auto Scaling 的問題,索性,我就整理成步驟好了。當然,首推外國網友這一篇,這應該是我翻過那麼多資料的最佳解了吧!
Autoscaling with custom metrics
UPDATE
先來一張圖,
首先,對於 INSUFFICIENT_DATA 的情況解釋,我想連官方都有點講不清楚。我們先來看 mon-put-data 到底做了什麼事情,
- --metrics-name 測量的名稱
- --namespace 所屬命名空間
- --dimensions 測量維度
- --value 測量數值
- --unit 測量單位
以上是最簡單的 mon-put-data 的設定方式,所以其實我們要針對 AutoScalingGroup 去作這件事情的時候,重點在Dimensions,這是目前網路上詳解所忽略的地方。所以我才想,怎麼我自己慢慢摸索會成功,然後其他人照著網路上做會不能用?
差異在於 Alarm 的 Dimensions 不同!
先前行文的設定方式,如果全部拆成 mon-put-data 的方法來看,大抵上會是這樣,
mon-put-data --metric-name "MemoryUtilization" \
--namespace "System/Linux" \
--dimensions "InstanceID=i-d3670fd3" \
--value "53.9416642950275" \
--unit "Percent"
這樣這個資料在 CloudWatch 裡面,就屬於 System/Linux 命名空間中,關於 InstancdID 分類的數據。如此一來,要建立正確的 Alarm 的時候,就必須指定正確(或者該說數據正常)的維度資料。以上面的例子來說,便是這樣,
mon-put-metric-alarm HighMemAlarm \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--metric-name MemoryUtilization \
--namespace "System/Linux" \
--period 300 \
--statistic Average \
--threshold 85 \
--alarm-actions <arn:aws:autoscaling:ap-northeast-....HighMemPolicy>
--dimensions "InstanceID=i-d3670fd3"
看出差異了嗎?目前大家的解法,都把 --dimensions 設定成 AutoScalingGroupName=myAutoScalingGroup 這樣的作法,所以會一直拿到 INSUFFICIENT_DATA 也挺合理的。
那麼,對於 AutoScalingGroupName 這個維度該怎麼設定?作法其實雷同,
mon-put-data --metric-name "MemoryUtilization" \
--namespace "System/Linux" \
--dimensions "AutoScalingGroupName=myAutoScalingGroup" \
--value "53.9416642950275" \
--unit "Percent"
建立 Alarm 就指定這樣的 dimensions,
mon-put-metric-alarm HighMemAlarm \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--metric-name MemoryUtilization \
--namespace "System/Linux" \
--period 300 \
--statistic Average \
--threshold 85 \
--alarm-actions <arn:aws:autoscaling:ap-northeast-....HighMemPolicy>
--dimensions "AutoScalingGroupName=myAutoScalingGroup"
這樣就可以了。
多個維度偵測
是,Dimensions 可以設定兩個以上的維度,但是,HELP 沒有告訴你多維度,要多 --value 才行(或者這是常識?其實這件事情我也是看別人的 source code 才知道的(遮臉
舉例來說,我如果要將 InstancdID 跟 AutoScalingGroupName 兩種維度丟在同一個 Metrics 裡面,
mon-put-data --metric-name "MemoryUtilization" \
--namespace "System/Linux" \
--dimensions "AutoScalingGroupName=myAutoScalingGroup" \
--value "53.9416642950275" \
--value "60.0987632456784" \
--unit "Percent"
這樣就可以了,你進入 AWS Console 就可以看到兩種數據(當然,你持續的丟上去的話,他會畫圖,不然都是一點一點(小星星
結語
網路上的教學不可盡信,我寫的也一樣喔(啾咪
以上資訊是針對 AutoScalingGroup 的部份做解說,以下的內文是針對單一 instancdID 做操作。目前網路上針對 CloudWatch 的部份,沒有特別說明兩者差異,所以會導置出現 INSUFFICIENT_DATA 的情況發生。
TL;DR
準備工作
如果之前有看過我寫的操作心得,請自行先備妥以下的東西,
另外,由於原生的 CloudWatch 沒有監控記憶體用量爾等的東西,所以我推薦這個,
上述的 Monitoring Scripts 下載下來後,這邊有說明,
你的 Ubuntu 要裝一些套件,
sudo apt-get install unzip libwww-perl libcrypt-ssleay-perl
然後就可以準備開始操作了。喔,這個工具需要一組 AccessKey,請到 IAM 自己弄一組出來。
建立自訂 CloudWatch metrics
這個 Monitoring Scripts 工具有兩個工具,
- mon-put-instance-data.pl
- mon-get-instance-data.pl
這跟官方的差別在,他是幫你打包好的工具,他可以建立記憶體、SWAP 跟磁碟使用量。如果你要自己用官方的 mon-put-data 去丟資料也可以,這個工具就是幫你做好了。舉例來說,我們可以測試一下,
$ ./mon-put-instance-data.pl --mem-util --verify --verbose
MemoryUtilization: 53.9416642950275 (Percent)
Using AWS credentials file <./awscreds.conf>
Endpoint: https://monitoring.ap-northeast-1.amazonaws.com/
Payload: AWSAccessKeyId=XXXXXXXXXXXXXXXXXXXXXXX&Action=PutMetricData&MetricData.member.1.Dimensions.member.1.Name=InstanceId&MetricData.member.1.Dimensions.member.1.Value=i-d3670fd3&MetricData.member.1.MetricName=MemoryUtilization&MetricData.member.1.Timestamp=2012-11-25T14%3A01%3A19.000Z&MetricData.member.1.Unit=Percent&MetricData.member.1.Value=53.9416642950275&Namespace=System%2FLinux&SignatureMethod=HmacSHA256&SignatureVersion=2&Timestamp=2012-11-25T14%3A01%3A19.000Z&Version=2010-08-01&Signature=aBDNz1kWY%2BW9jSdQXv6zhHtg%2F%2BKxcktfXXXXX6Ppp0%3D
上述就是把記憶體使用量抓出來的測試,加入 --verify 就不會把資料真的放到 CloudWatch 上面(畢竟丟資料上去,是要收錢的)。上面列出來很多資訊,我們逐一來看一下,
MetricData.member.1.Dimensions.member.1.Name=InstanceId
MetricData.member.1.Dimensions.member.1.Value=i-d3670fd3
MetricData.member.1.MetricName=MemoryUtilization
MetricData.member.1.Timestamp=2012-11-25T14%3A01%3A19.000Z
MetricData.member.1.Unit=Percent
MetricData.member.1.Value=53.9416642950275
Namespace=System%2FLinux
如果把他翻譯成 CloudWatch 的指令大概會是這樣,
mon-put-data --metric-name "MemoryUtilization" \
--namespace "System/Linux" \
--dimensions "InstanceID=i-d3670fd3" \
--value "53.9416642950275" \
--unit "Percent"
然後,沒有然後了,這就是將資料放到 CloudWatch 裡面的過程,如果要把他拿出來,就用 mon-get-instance-data 就好了,
$ ./mon-get-instance-stats.pl
Instance i-d3670fd3 statistics for the last 1 hour.
CPU Utilization
Average: 9.71%, Minimum: 4.10%, Maximum: 44.79%
Memory Utilization
Average: N/A, Minimum: N/A, Maximum: N/A
Swap Utilization
Average: N/A, Minimum: N/A, Maximum: N/A
Disk Space Utilization for /dev/xvda1 mounted on /
Average: N/A, Minimum: N/A, Maximum: N/A
至於 CloudWatch 怎麼拿,我就不多說了。如果你想要建立這些事情以外的監控方法,你就得用 CloudWatch 所提供的 mon-put-data 去放你想要的資料了。
持續紀錄
請用 crontab,容我直接抄討論區的內容(喂
*/5 * * * * ~/aws-scripts-mon/mon-put-instance-data.pl --mem-util --disk-space-util --disk-path=/ --from-cron
建立 Alarm
這邊有兩個作法,一個是去 Console 操作,另一個是使用 Command Line 操作。兩種我都大略提一下,首先是在 AWS 的 Console 裡面操作,
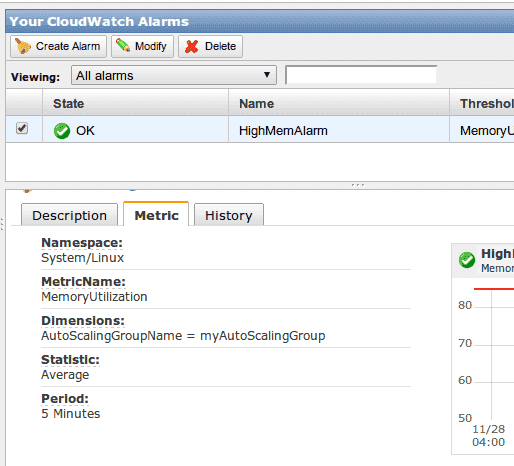
首先你可以在 metrics 裡面看到你自己建立的資料,
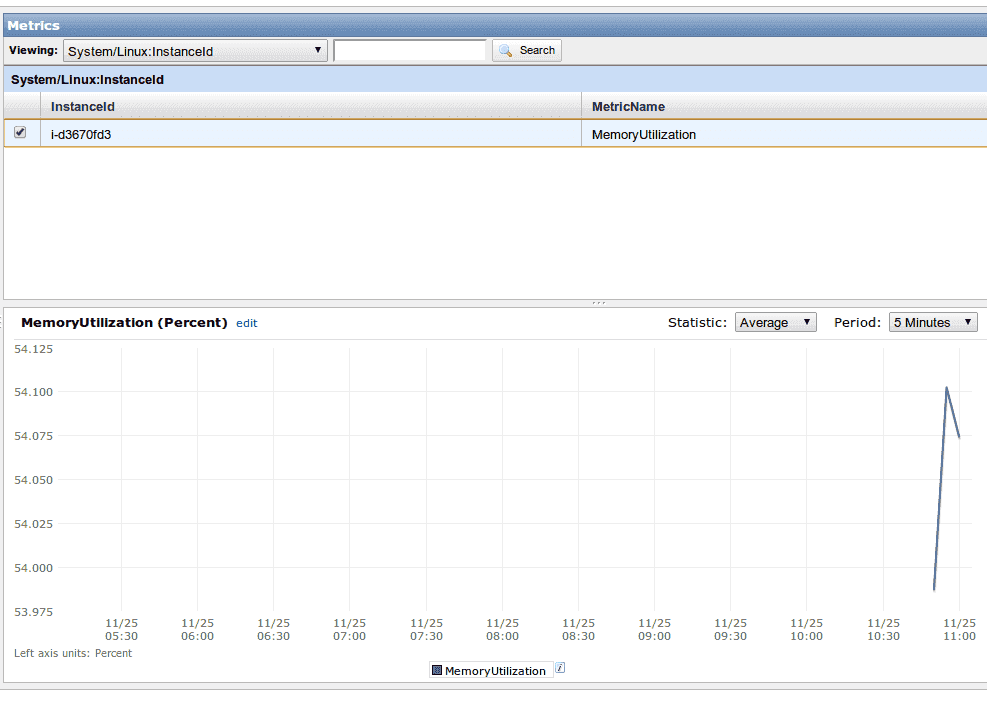
然後可以建立一個新的 Alarm,
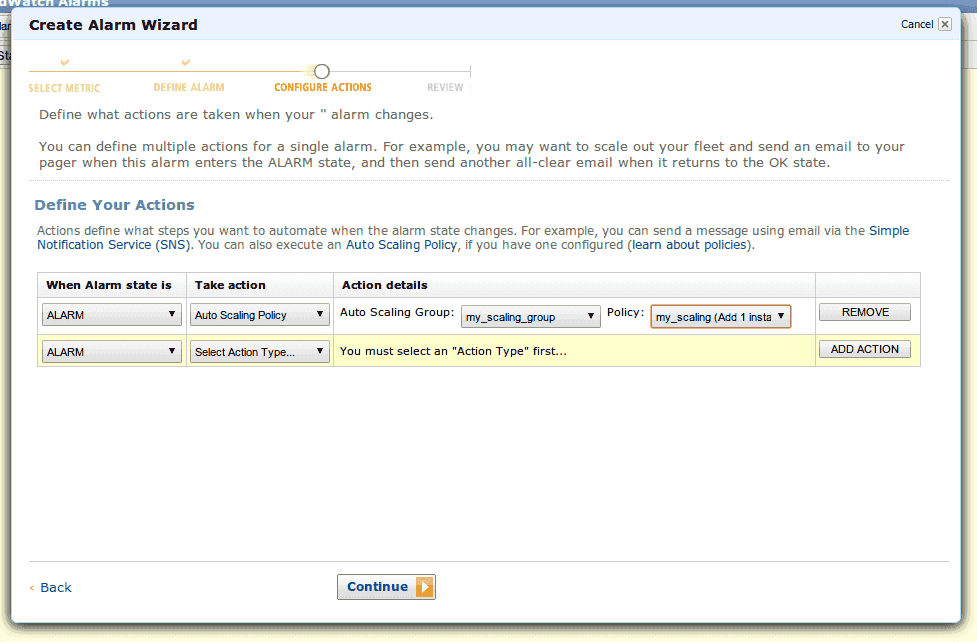
這是你自己建立的 Alarm 資料,
然後?然後就做完了(疑),沒錯,他就幫你做完很多事情了。接著可以看一下 Command Line 的作法,
mon-put-metric-alarm LowMemAlarm \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--metric-name MemoryUtilization \
--namespace "System/Linux" \
--period 300 \
--statistic Average \
--threshold 85 \
--alarm-actions <arn:aws:autoscaling:ap-northeast-....LowMemPolicy>
--dimensions "InstanceID=i-d3670fd3"
大概就是這樣啦,有看過我之前文章的人應該知道他做了什麼事情,所以我就不多做解釋了(喂
意外
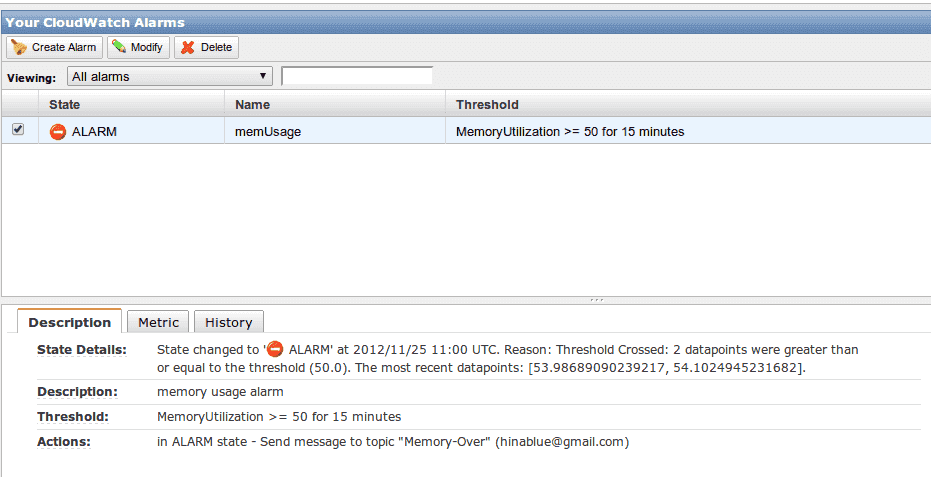
如果你使用 Command Line 來設定 Alarm 的時候,你會發現你的狀態會是這樣,
INSUFFICIENT_DATA
然後,官方的說明是,
Hi,
There is an inherent delay in transitioning into INSUFFICIENT_DATA state (only) as alarms wait for a period of time to compensate for metric generation latency.
For an alarm with a 60 second period, the delay before transition into I_D state will be between 5 and 10 minutes.
Cloudwatch Alarm on INSUFFICIENT DATA HELP
結語
如果對於 AWS 有極高興趣或是有問題想發問,請先到這裡,
你寫信給我我也是會回啦其實...
