
現在的 JavaScript 框架面對搜尋引擎,普遍的問題大概都會圍繞著 SEO 打轉,這是以往在伺服器渲染的前端頁面下所沒有的。然後,對於這樣的狀況,多數也是有相對應的解決方案,只是是否合乎你的使用情境,就見仁見智了。
我們今天會提到一些關於 SEO 與其工具的介紹,就讓我們繼續看下去。
前端渲染
不僅僅是 Vue 這個框架,另外兩家若僅僅只是前端渲染的話,多少會遇到 SEO 的問題。而撇除掉網頁的內容( content ),我們還要處理關於 <meta> 的事情,中文說法有很多:元資料、中繼資料、後設資料、描述資料的資料等等。
由於前端渲染這件事情,必須得等到 JavaScript 讀取完畢,並開始執行之後,才會產生出 內容,而你所提供的 <meta> 也得等到你的 App 運行之後,才可能會被修改為正確的資料。換句話說,在你的 App 還沒有任何動作之前,你的網站所提供的訊息,基本上不一定會正確。
舉例來說,當你的 App 是屬於前端渲染,我們如果使用 Facebook 分享功能,他就會抓到一些比較奇怪的東西。
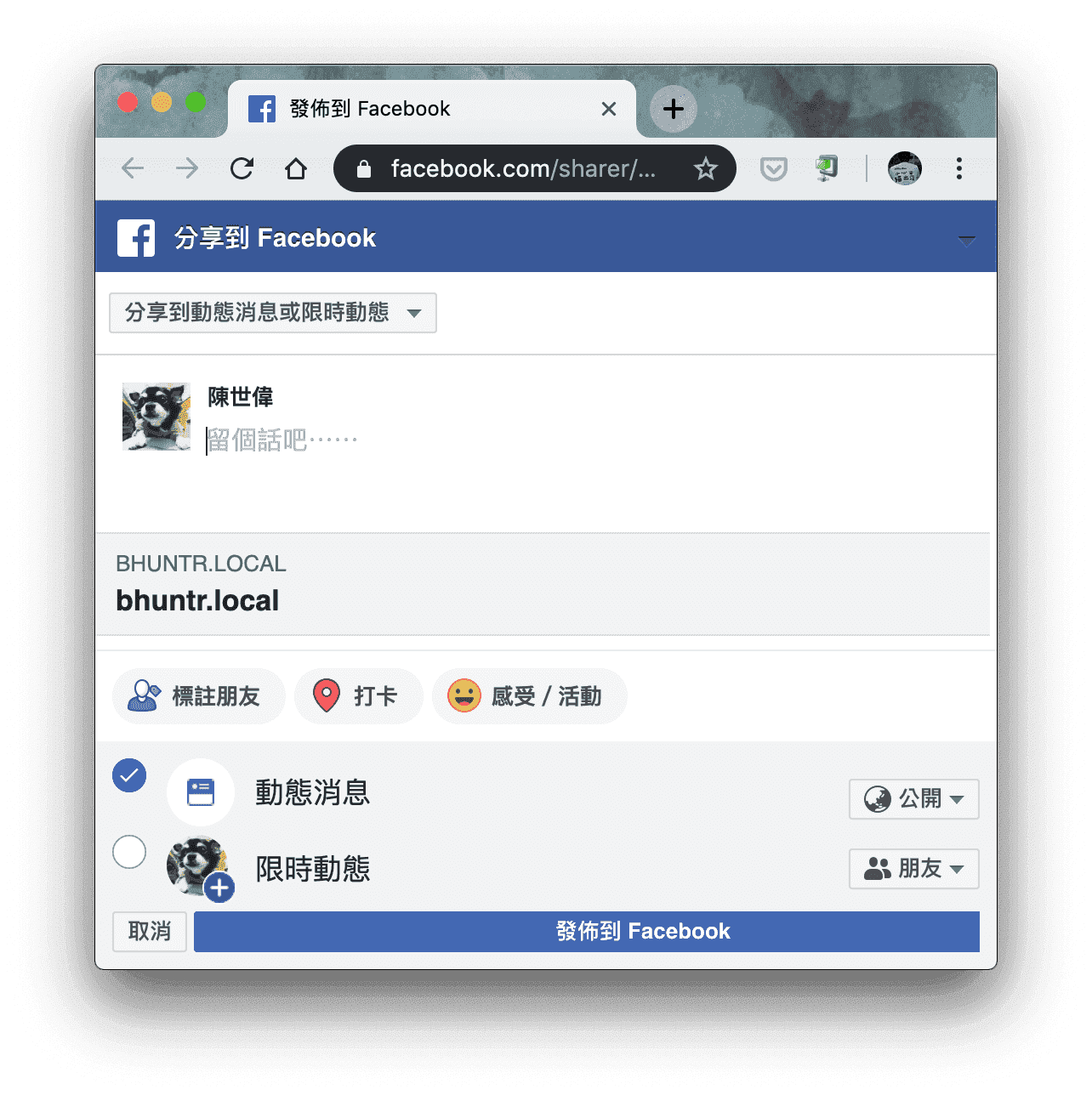
所以說,今天無論是 Facebook,爾或是 Twitter, LINE 或是其他可以分享貼文的平台,爾或是 Google Search 等等的搜尋引擎,他們基本上都有可能會拿到不正確的資訊。不過聽說 Google 搜尋引擎的機器人 ( bot ),好像慢慢看得懂 JavaScript 渲染的頁面了(聽說)。
那麼,這些使用框架的東西不就完全沒辦法了嗎?
預先渲染
當然,市面上有一些工具是幫你做預先渲染的動作,亦即我們蠻常聽到的 SSR ( Server Side Render ) 套件,而 Vue 官方也有關於這方面的介紹:
我本來想說介紹一下,但是還是留到明天我們再來詳談。先說明一下這個東西的優缺點:
- 優點:
- 可以預先寫好
<meta>與少部分的內容( content )。 - 前端可以先顯示部分結構,然後漸進式讀取資料內容。
- 縮短整體頁面渲染時間,增加使用者體驗。
- 對於搜尋引擎相對友善一點點。
- 可以預先寫好
- 缺點:
- 遇到全頁面皆需要更動的部分,並沒有占到優勢。
- 快取級別雖然可縮小到元件,但僅針對
v-for相對有優勢一點。 - 元件快取有坑,而且很容易踩到(官方自己有說)。
- 你要搞一個 NodeJS 環境來做快取。
為何會說對搜尋引擎友善,原因在於非特定使用者產生的頁面,我們對於 <meta> 大多都可以固定,而且鮮少變動,更甚是,你也可以把 JSON-LD 都寫好在樣版裡面,那麼,當搜尋引擎機器人來查找時,他就能取得相對應的資料。所以,這一點對比起什麼都要等 JavaScript 渲染完成,要好得多。
當然,如果是特定使用者產生,也就是全頁面都需要因為使用者( 這裡說的使用者也可以換為特定對象,例如說新聞頁面、部落格文章等等 )而變更時,那麼你就沒辦法產生特定的 <meta> 或是 JSON-LD,因為,那些所謂「預設」的資料,對各種內容平台或是搜尋引擎,都不是正確的資料。
讓我們再看一次:
你幫我渲染
既然預先渲染的資料沒那麼正確,那麼還有一種方式叫做 你幫我渲染 ,也就是市面上常見到的預先渲染( prerender services )的服務,例如小有名氣的 Prerender.io ,然後就沒有然後了,因為我不知道其他家。
這種方式用比較白話一點的方式來說,大概是這樣:
- 你先來申請個 API KEY (
順便留一下信用卡資料)。 - 然後教你怎麼把服務掛到 Nginx 或是 Apache 裡面。
- 接著請你把想要渲染的頁面接到他們的服務器。
- 最後限制一些機器人來查找的時候,才做 3. 的事情。
當然,Prerender 也很佛心的你想要自己架也可以:
兩種我都試過,不知道是不是我 沒有付錢 的關係,我曾經戳到他們的服務沒有回應過。我記得我也沒有戳很多,不過就是公司某一些頁面而已( 30000+/day ),然後我可以得到一個大概 3~5 分鐘的反應時間。然後你就會發現 Facebook 的分享除錯工具告訴你,你的頁面逾時取不到資料。
後來改自己架設,基本上除非你的機器記憶體很大,不然我用 AWS m3.medium 的機器(我知道是老機器了,我窮不要逼我),光一個 Prerender 他就能把記憶體吃光,就算了,你的 node 還會不小心因為負載太高而直接嗝屁給你看。所以,基於 我沒有付錢 還狂戳 Prerender.io 這件事情,
對不起!我錯了!
既然知道 Prerender.io 的操作方式,那麼其實還是有其他的替代方案,例如說,使用 Chrome Headless 來做畫面渲染的動作。
你就可以利用 NodeJS 來幫你渲染畫面:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
// 然後你就把 content 存起來,或是傳回去給你的 Nginx/Apache.
let content = await page.content();
await browser.close();
})();
上述的方法我也是用過,但是呢,你覺得,在伺服器上開一個 Chrome 然後 newPage() 要花多少記憶體?你猜猜看一台 6 cores, 32GB RAM 的機器,最多可以開幾頁?
5 頁 (每間隔 300 豪秒),再多或過於頻繁,頁面會崩潰( Crash )。
偉哉 Google Chrome!即便是開在伺服器端,終究還是吃記憶怪獸啊(遠目)。所以,你如果要應付像是每日 3 萬頁以上,最好還是找一個好一點的機器(如果你真的想要自己做的話)。另外,快取的機制也是很重要,不然實在挺麻煩的。特別是,這些頁面可能還只是機器人來掃描的,對於機器的瞬間壓力有時候會挺高的。
小結
今天沒有什麼程式碼,讓大家比較輕鬆一點。對於 SEO 的狀況,我們明天會認真的來聊一下關於 SSR 的部分。然後其實我明天的題目是 為何我不用 SSR ,沒辦法我比較反骨。就是因為操作過,所以才放棄。
SSR 從開始到放棄(
棒棒噠)
